Имитационное моделирование работы вычислительной системы из трех ЭВМ в среде GPSS
СОДЕРЖАНИЕ: Федеральное агентство по образованию Пояснительная записка к курсовому проекту по курсу «Моделирование систем» Тема: «Имитационное моделирование работы вычислительной системы из трех ЭВМ в среде GPSS»Федеральное агентство по образованию
Пояснительная записка к курсовому проекту
по курсу «Моделирование систем»
Тема: «Имитационное моделирование работы вычислительной системы из трех ЭВМ в среде GPSS»
Екатеринбург 2008г
Содержание
Введение
1. Построение концептуальной модели системы и ее формализация
1.1 Формулировка цели и постановка задачи машинного моделирования системы
1.2 Анализ задачи моделирования системы
1.3 Определение требований к исходной информации об объекте моделирования и организация ее сбора
1.4 Выдвижение гипотез и принятие предположений
1.5 Определение параметров и переменных модели
1.6 Установление основного содержания модели
1.7 Обоснование критериев оценки эффективности системы
1.8 Определение процедур аппроксимации
1.9 Описание концептуальной модели системы
1.10 Проверка достоверности концептуальной модели
2. Алгоритмизация модели системы и ее машинная реализация
2.1 Построение логической схемы модели
2.2 Получение математических соотношений
2.3 Проверка достоверности модели системы
2.4 Выбор инструментальных средств моделирования
2.5 Составление плана выполнения работ по программированию
2.6 Спецификация и построение схемы программы
2.7 Проведение программирования модели
2.8 Проверка достоверности программы
3. Получение и интерпретация результатов моделирования системы
3.1 Планирование машинного эксперимента с моделью системы
3.2 Определение требований к вычислительным средствам
3.3 Проведение рабочих расчетов
3.4 Анализ результатов моделирования системы
3.5 Представление результатов моделирования
3.6 Интерпретация результатов моделирования
3.7 Подведение итогов моделирования и выдача рекомендаций
Введение
Вычислительная система состоит из трех ЭВМ. С интервалом 3 ± 1 мин в систему поступают задания, которые с вероятностями Р1 = 0,4; P2 = P3 = 0,3 адресуются одной из трех ЭВМ. Перед каждой ЭВМ имеется очередь заданий, длина которой не ограничена. После обработки задания на первой ЭВМ, оно с вероятностью P12 = 0,3 поступает в очередь ко второй ЭВМ и с вероятностью P13 = 0,7 – в очередь к третьей ЭВМ. После обработки на второй или третьей ЭВМ задание считается выполненным. Продолжительность обработки заданий на разных ЭВМ характеризуется интервалами времени Т1 = 7 ± 4 мин, T2 = 3 ± 1 мин, T3 = 5 ± 2 мин. Смоделировать процесс обработки 200 заданий. Определить максимальную длину каждой очереди и коэффициенты загрузки ЭВМ.
1. Построение концептуальной модели системы и ее формализация
1.1 Формулировка цели и постановка задачи машинного моделирования системы
Необходимо исследовать работу вычислительной системы из трех ЭВМ. В качестве цели моделирования выберем изучение функционирования системы, а именно оценивание ее характеристик с точки зрения эффективности работы системы, т.е. минимизацию длины очереди к ЭВМ и максимизацию коэффициента загрузки ЭВМ (т.е. будет ли она простаивать, работать на износ или работать с запасом). В качестве цели эффективного функционирования системы целесообразно выбрать максимизацию коэффициента загрузки каждой ЭВМ.
С учетом имеющихся ресурсов в качестве метода решения задачи выберем метод имитационного моделирования, позволяющий не только анализировать характеристики модели, но и проводить структурный, алгоритмический и параметрический синтез модели на ЭВМ при заданных критериях оценки эффективности и ограничениях.
Постановка задачи исследования функционирования вычислительной системы состоящей из трех ЭВМ представлена в задании к курсовому проектированию, из которого следует, что необходимо определить:
- максимальную длину очередей к каждой ЭВМ;
- коэффициенты загрузки каждой ЭВМ.
Пересмотр начальной постановки задачи исследования не предусмотрен.
1.2 Анализ задачи моделирования системы
В качестве критерия оценки эффективности процесса функционирования системы целесообразно выбрать коэффициент загрузки ЭВМ, который должен быть максимальным, при этом длина очереди к каждой ЭВМ должна быть минимальной. Соотношение загрузки каждой ЭВМ должно быть в среднем одинаковым, чтобы каждое устройство было задействовано равноценно. В качестве еще одного традиционного критерия оценки эффективности процесса функционирования системы можно выбрать минимальное время обработки заданий в системе в целом при максимальном количестве обработанных заданий.
Экзогенные (независимые) переменные модели:
- интервал времени поступления заданий;
- вероятность поступления заданий на первоначальную обработку к каждой из ЭВМ;
- вероятность поступления заданий на дальнейшую обработку к оставшимся ЭВМ;
- продолжительность обработки заданий на каждой из ЭВМ;
- количество заданий.
Эндогенные (зависимые) переменные модели:
- длину очереди к каждой из ЭВМ;
- коэффициент загрузки каждой ЭВМ.
При построении математической имитационной модели процессов функционирования системы будем использовать непрерывно-стохастический подход на примере типовой Q-схемы, потому что исследуемая система – вычислительная система из трех ЭВМ – может быть представлена как система массового обслуживания с непрерывным временем обработки параметров при наличии случайных факторов.
Формализовав процесс функционирования исследуемой системы в абстракциях Q-схемы, на втором этапе алгоритмизации модели и ее машинной реализации выберем язык имитационного моделирования, потому что высокий уровень проблемной ориентации языка значительно упростит программирование, а специально предусмотренные в нем возможности сбора, обработки и вывода результатов моделирования позволят быстро и подробно проанализировать возможные исходы имитационного эксперимента с моделью. Для получения полной информации о характеристиках процесса функционирования системы необходимо будет провести полный факторный эксперимент, который позволит определить, насколько эффективно функционирует система, и выдать рекомендации по ее усовершенствованию.
1.3 Определение требований к исходной информации об объекте моделирования и организация ее сбора
Вся необходимая информация о системе и внешней среде представлена в задании к курсовому проектированию и не требует предварительной обработки.
1.4 Выдвижение гипотез и принятие предположений
Для заполнения пробелов в понимании задачи исследования, а также проверки возможных результатов моделирования при проведении машинного эксперимента выдвигаем следующие гипотезы:
- если интенсивность поступления заданий в ВС будет меньше времени обработки заданий на каждой из ЭВМ, то коэффициент загрузки каждой из ЭВМ будет возрастать, и, как следствие, будет увеличиваться количество поступивших заданий в ВС, которые образуют длинные очереди;
- первая ЭВМ прорешивает меньше заданий двух других ЭВМ и при этом имеет длину очереди всегда больше длины очереди ко второй ЭВМ;
- третья ЭВМ прорешивает всегда больше заданий, чем две другие ЭВМ по отдельности.
Для упрощения модели можно выдвинуть следующие предположения:
- время перехода задания от одной ЭВМ к другой равно нулю.
1.5 Определение параметров и переменных модели
Входные переменные модели:
- интервал времени (интенсивность) поступления заданий в вычислительную систему (ВС), tп ±Dtп , где tп – средний интервал времени между поступлением заданий в ВС, Dtп – половина интервала, в котором равномерно распределено значение, единица измерения – минута;
Выходные переменные модели:
- количество заданий обработанных на каждой из ЭВМ в заданные интервалы времени обработки заданий и вероятностями поступления заданий на них, NОЗ1 , NОЗ2 , NОЗ3 , единица измерения – количество заданий;
- коэффициент загрузки каждой из ЭВМ, ZЭ1 , ZЭ2 , ZЭ3 , единица измерения - относительная единица;
- количество заданий, которым пришлось ждать в очереди, вследствие высокого коэффициента загрузки ЭВМ в заданные интервалы времени обработки заданий на каждой из ЭВМ и вероятностями поступления заданий на них, NО1 , NО2 , NО3 , единица измерения – количество студентов.
Параметры модели:
· вероятность поступления заданий на вторую или третью ЭВМ после обработки на первой ЭВМ, РР2 , РР3 , единица измерения – %;
· вероятность поступления заданий на первоначальную обработку к каждой из ЭВМ, РП1 , РП2 , РП3 , единица измерения – количество заданий;
· количество заданий, решенных второй или третьей ЭВМ в заданные интервалы времени обработки заданий на каждой из ЭВМ и вероятностями поступления заданий на них, NРЗ2 , NРЗ3 , единица измерения – количество заданий;
· количество заданий, которые надо прорешать, NО , единица измерения - количество заданий;
· интервал времени (интенсивность) обработки заданий каждой из ЭВМ, tЭ1 , tЭ2 , tЭ3 , единица измерения – минута.
Воздействия внешней среды отсутствуют.
1.6 Установление основного содержания модели
На основе анализа исходных данных и выдвинутых гипотез можно сделать вывод о том, что процессы, происходящие в моделируемой системе, являются процессами массового обслуживания, поэтому эти процессы целесообразно описать на языке Q-схем.
1.7 Обоснование критериев оценки эффективности системы
Для оценки качества процесса функционирования моделируемой системы сформируем на основании анализа задачи моделирования системы функцию поверхности отклика в исследуемой области изменения параметров и переменных как совокупность критериев оценки эффективности. Эта функция позволит определить экстремумы реакции системы.
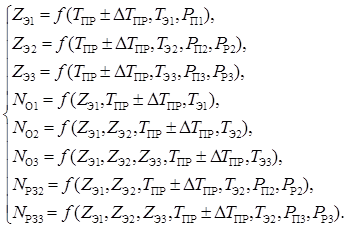
1.8 Определение процедур аппроксимации
Для аппроксимации реальных процессов, протекающих в системе, воспользуемся процедурой определения средних значений выходных переменных, поскольку в системе имеются случайные значения переменных и параметров.
1.9 Описание концептуальной модели системы
Концептуальная модель исследуемой системы представлена в виде структурной схемы (рис. 1), состоящей из одного входного потока х – задания, поступающие в вычислительную систему, двух выходных потоков у1 , у2 – задания, решенные в вычислительной системе на второй и третьей ЭВМ.
Целевая функция модели системы:
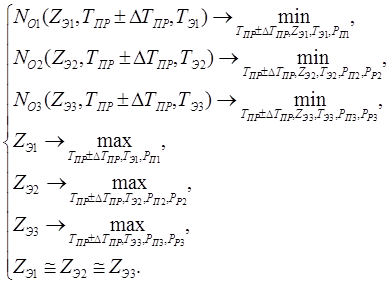
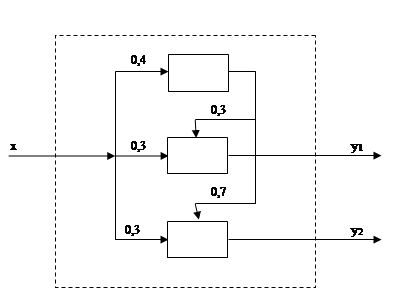
Рис. 1. Концептуальная модель в виде структурной схемы
В качестве типовой математической схемы применяется Q-схема, состоящая из одного источника (И), трех накопителей (Н1 , Н2 , Н3 ), трех каналов (К1 , К2 , К3 ), восемью клапанов (рис. 2). Задания в систему поступают от источника И с интервалом 3 ± 1 мин в каждый из первых трех клапанов с вероятностями: клапан 1 – 40%, клапан 2 – 30%, клапан 3 – 30%. Клапан 1, клапан 2, клапан 3 управляются накопителями Н1 , Н2 , Н3 , ёмкость которых LН1 , LН2 , LН3 не ограничена по условию задачи. С накопителя 1 (Н1 ), задания поступают в клапан 4, который управляется каналом 1 (К1 ). Аналогично с накопителями 2 и 3 (Н2 , Н3 ), задания с которых поступают в клапан 5 и 6, управляются каналами 2 и 3 (К2 , К3 ) соответственно. Обработка (задержка) заданий в каналах К1 , К2 , К3 занимает 7 ± 4 мин, 3 ± 1 мин, 5 ± 2 мин соответственно. После обработки каналом 1 (К1 ), задания поступают на конечный этап обработки до решенного состояния с вероятностями 30% в клапан 2 и 70% в клапан 3. После вновь поступившие задания в клапан 2 и 3, управляются накопителями 2 и 3 (Н2 , Н3 ), задания с которых поступают в клапан 5 и 6, управляются каналами 2 и 3 (К2 , К3 ) соответственно. После очередной обработки (задержки) в каналах 2 и 3 (К2 , К3 ), задания поступают в клапаны 7 и 8, где и уничтожаются, как полностью выполненные (решенные) задания.
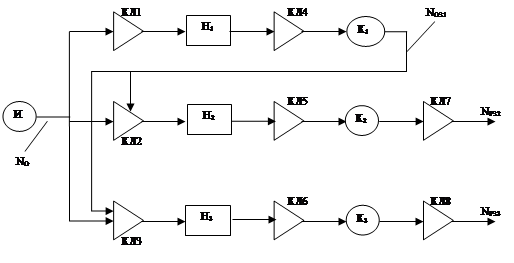
Рис. 2. Концептуальная модель в виде Q-схемы
Формальная модель системы:
Q = {И, Н1 , Н2 , Н3 , К1 , К2 , К3 , NО , NОЗ1 , NРЗ2 , NРЗ3 , кл1 , кл2 , кл3 , кл4 , кл5 , кл6 , кл7 , кл8 , LН = }.
Согласно разработанной концептуальной модели окончательные гипотезы и предположения совпадают с ранее принятыми. Выбранная процедура аппроксимации определения средних значений выходных переменных соответствует реальным случайным процессам, протекающим в системе массового обслуживания.
1.10 Проверка достоверности концептуальной модели
Проверка достоверности концептуальной модели включает:
а) проверку замысла модели: изначальное изучение поставленной задачи было сделано очень подробно, а именно описаны все параметры и переменные, выдвинуты гипотезы и предположения, доказательство которых должно быть подтверждено в дальнейших этапах анализа;
б) оценку достоверности исходной информации: в течение первого этапа анализа задачи четко определились и выявились данные, которые нужно найти и с помощью чего, что подтверждается элементарной логикой;
в) рассмотрение задачи моделирования: проходит через анализ по отдельным этапам, по которым выдвигаются начальные зависимости данных в задаче;
г) анализ принятых аппроксимаций: на принятых аппроксимациях, возможен дальнейший анализ и обратная логика тоже подтверждена, но полный анализ будет проходить на дальнейших этапах исследования;
д) исследование гипотез и предположений: из данных и полученных различных формулировок возможно выдвинуть гипотезы и предположения, которые не опровергают все выше сказанное.
2. Алгоритмизация модели системы и ее машинная реализация
2.1 Построение логической схемы модели
Логическая схема модели представлена на рис. 3.
После генерации заявок в источнике И (блок 1) осуществляется распределение потока заданий с вероятностями 40%, 30%, 30% между накопителями Н1 (блок 2), Н2 (блок 3), Н3 (блок 4). В условии задачи емкость накопителя не ограничена, поэтому отказов в системе нет. После ожидания в накопителях Н1 , Н2 , Н3 , задания поступают на обслуживание в каналы К1 (блок 5), К2 (блок 6), К3 (блок 7). Задание, закончившее обработку на первом канале не является решенным, поэтому поступает на ожидание последней обработки в накопители Н2 (блок 3), Н3 (блок 4) с вероятностным распределением 30% и 70% соответственно. Для того чтобы определить загруженность (или простои) каналов К1 , К2 и К3 , можно проанализировать статистические данные, касающиеся очереди перед соответствующими каналами. После обработки в каналах К2 и К3 , задание поступает на удаление (блок 8 и блок 9) и покидает систему.
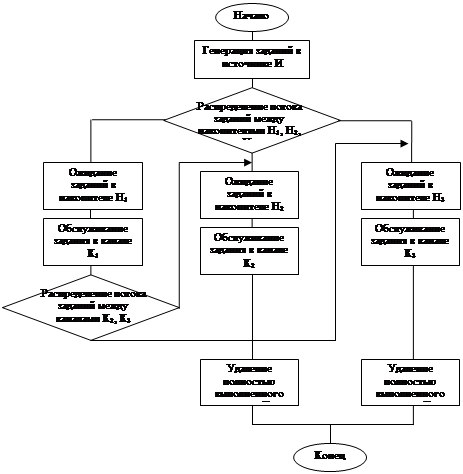
Рис. 3. Логическая схема
2.2 Получение математических соотношений
Для построения машинной модели системы в комбинированном виде, т.е. с использованием аналитико-имитационного подхода, необходимо часть процессов в системе описать аналитически, а другую часть сымитировать соответствующими алгоритмами. На данном этапе построения аналитической модели зададим математические соотношения в виде явных функций.
Загрузки каждой ЭВМ и максимальную длину очередей в виде явных функций записать трудно. Эти величины определим с помощью языка имитационного моделирования.
2.3 Проверка достоверности модели системы
На данном подэтапе достоверность модели системы проверяется по следующим показателям:
а) возможности решения поставленной задачи:
Решение данной задачи с помощью математических отношений нецелесообразно, так как искомые данные не имеют явных функций. Использование имитационного моделирования решает эти сложности, но для правильной реализации нужно точно и безошибочно определить параметры и переменные модели, обосновать критерии оценки эффективности системы, составить концептуальную модель и построить логическую схему. Все эти шаги построить модель данного процесса;
б) точности отражения замысла в логической схеме:
При составлении логической схемы, важно понимать смысл задачи, до этого построить концептуальную модель. Проверку точности можно выполнить при подробном описании самой схемы, при этом, сопоставлять с описанием концептуальной модели;
в) полноте логической схемы модели:
Проверить наличие всех выше описанных переменных, параметров, зависимостей, последовательности действий;
г) правильности используемых математических соотношений:
2.4 Выбор инструментальных средств моделирования
В нашем случае для проведения моделирования системы массового обслуживания с непрерывным временем обработки параметров при наличии случайных факторов необходимо использовать ЭВМ с применением языка имитационного моделирования GPSS, т.к. в настоящее время самым доступным средством моделирования систем является ЭВМ, а применение простого и доступного языка имитационного моделирования GPSS (http://www.gpss.ru) позволяет получить информацию о функции состояний zi (t) системы, анализируя непрерывные процессы функционирования системы только в «особые» дискретные моменты времени при смене состояний системы благодаря моделирующему алгоритму, реализованному по «принципу особых состояний» (принцип dz). Кроме того, высокий уровень проблемной ориентации языка GPSS значительно упростит программирование, специально предусмотренные в нем возможности сбора, обработки и вывода результатов моделирования позволят быстро и подробно проанализировать возможные исходы имитационного эксперимента с моделью.
2.5 Составление плана выполнения работ по программированию
Выбранный язык имитационного моделирования GPSS имеет три версии: MICRO-GPSS Version 88-01-01, GPSS/PC Version 2, GPSS World Students Version 4.3.5. Micro-GPSS имеет DOS-интерфейс, который чувствителен к стилю написания программы (количеству пробелов между операндами, длине меток и имен и др.), не содержит текстового редактора. GPSS/PC лишен указанных недостатков, однако интерпретатор GPSS World Students имеет ряд преимуществ перед ним, например наличие интерфейса Windows, пошагового отладчика, возможность сбора и сохранения в файлах различной статистической информации, визуальный ввод команд. Поэтому для разработки модели был выбран именно интерпретатор GPSS World Students.
Для моделирования достаточно использовать ЭВМ типа IBM/PC, применение специализированных устройств не требуется. В программное обеспечение ЭВМ, на которой проводится моделирование, должны входить операционная система Windows (версия 9Х и выше) и интерпретатор GPSS. Затраты оперативной и внешней памяти незначительны, и необходимости в их расчете при современном уровне техники нет. Затраты времени на программирование и отладку программы на ЭВМ зависят только от уровня знаний языка и имеющихся навыков, которые были получены мною на лабораторных работах.
2.6 Спецификация и построение схемы программы
к программе на языке имитационного моделирования GPSS согласно спецификации программы предъявляются традиционные требования: структурированность, читабельность, корректность, эффективность и работоспособность.
Спецификация постановки задачи данного курсового проекта – определить максимальную длину очередей перед каждой ЭВМ (NО1 , NО2 , NО3 ) и коэффициенты загрузки каждой из ЭВМ (ZЭ1 , ZЭ2 , ZЭ3 ). В качестве исходных данных задаются интервал времени (интенсивность) поступления заданий в вычислительную систему, состоящую их трех ЭВМ (tпр ±Dtпр ), интервал времени обработки заданий на каждой из ЭВМ (tЭ1 , tЭ2 , tЭ3 ), а также процент распределения заданий на одну из трех ЭВМ (РЭ1 , РЭ2 , РЭ3 ), процент распределения заданий на последний этап обработки на вторую и третью ЭВМ (РР2 , РР3 ).
Спецификация ограничений на параметры исследуемой системы следующая: исходные данные должны быть положительными числами, кроме того, процент распределения заданий на одну из трех ЭВМ (РЭ1 , РЭ2 , РЭ3 ) и процент распределения заданий на последний этап обработки на вторую и третью ЭВМ (РР2 , РР3 ), каждый по отдельности в сумме должен составлять 100%.
Схема программы (см. рис. 4) зависит от выбранного языка моделирования.
Блоки схемы соответствуют блок-диаграмме языка GPSS, что позволит легко написать текст программы, провести ее модификацию и тестирование. Для полного покрытия программы тестами необходимо так подобрать параметры, чтобы все ветви в разветвлениях проходились по меньшей мере по одному разу. Интерпретатор языка GPSS позволяет проанализировать статистические данные по каждой ветви программы.
Оценка затрат машинного времени проводится по нескольким критериям эффективности программы: затраты памяти ЭВМ, затраты вычислений (идентичны времени вычислений при последовательной обработке), время вычислений («время ответа»). Форма представления входных и выходных данных определяется интерпретатором языка GPSS и изменить ее по усмотрению пользователя невозможно.
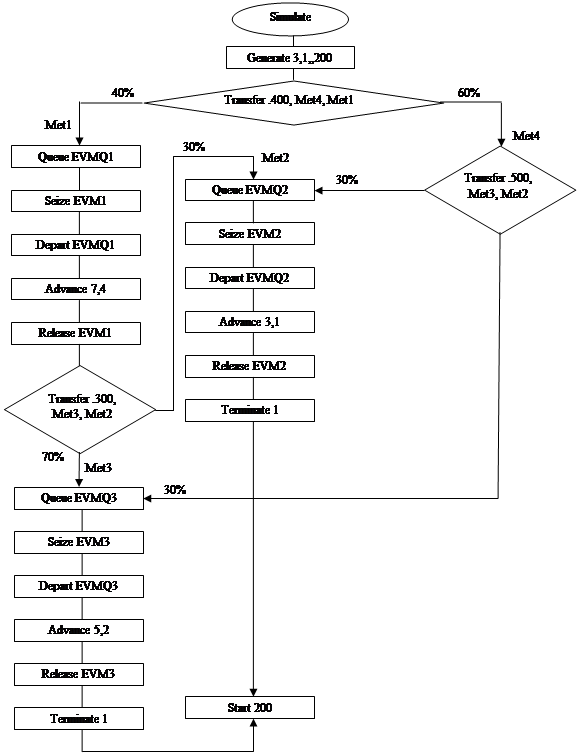
рис. 4. Схема программы
2.7 Проведение программирования модели
| Метки | Текст программы | Комментарии |
| Simulate | Начало программирования | |
| Generate 3,1,,200 | Генерация входных заданий | |
| Transfer .400, Met4, Met1 | 40% заданий направляется на метку 1, а 60% - на метку 4 | |
| Met1 | Queue EVMQ1 | Сбор статистических данных о входе задания в очередь EVMQ1 к прибору EVM1 |
| Seize EVM1 | Занятие прибора EVM1 | |
| Depart EVMQ1 | Сбор статистических данных о выходе задания из очереди EVMQ1 к прибору EVM1 | |
| Advance 7,4 | Обработка заявки в приборе EVM1 | |
| Release EVM1 | Освобождение прибора EVM1 | |
| Transfer .300, Met3, Met2 | 30% заданий, обработанных на приборе EVM1 направляется на метку 2, а 70% - на метку 3 | |
| Met4 | Transfer .500, Met3, Met2 | из 60% заданий - 30% заданий направляется на обработку к метке 2 и 30% к метке 3 |
| Met2 | Queue EVMQ2 | Сбор статистических данных о входе задания в очередь EVMQ2 к прибору EVM2 |
| Seize EVM2 | Занятие прибора EVM2 | |
| Depart EVMQ2 | Сбор статистических данных о выходе задания из очереди EVMQ2 к прибору EVM2 | |
| Advance 3,1 | Обработка заявки в приборе EVM2 | |
| Release EVM2 | Освобождение прибора EVM2 | |
| Terminate 1 | Уничтожение одного задания | |
| Met3 | Queue EVMQ3 | Сбор статистических данных о входе задания в очередь EVMQ3 к прибору EVM3 |
| Seize EVM3 | Занятие прибора EVM3 | |
| Depart EVMQ3 | Сбор статистических данных о выходе задания из очереди EVMQ2 к прибору EVM3 | |
| Advance 5,2 | Обработка заявки в приборе EVM3 | |
| Release EVM3 | Освобождение прибора EVM3 | |
| Terminate 1 | Уничтожение одного задания | |
| Start 200 | ||
| End | Конец моделирования |
2.9 Проверка достоверности программы
На данном подэтапе последняя проверка машинной реализации модели проводится следующим образом:
а) обратным переводом программы в исходную схему, что в очередной раз подтверждает правильность пути исследования для моделирования;
б) проверкой отдельных частей программы при решении различных тестовых задач;
в) объединением всех частей программы и проверкой ее в целом на контрольном примере моделирования варианта системы.
На этом подэтапе необходимо также проверить затраты машинного времени на моделирование.
3. Получение и интерпретация результатов моделирования системы
3.1 Планирование машинного эксперимента с моделью системы
Для получения максимального объема необходимой информации об объекте моделирования при минимальных затратах машинных ресурсов проведем полный факторный эксперимент с четырьмя существенными факторами (переменных и параметров).
Согласно выбранным критериям оценки эффективности системы и целевой функции модели выберем следующие существенные факторы:
х1 – интервал времени (интенсивность) поступления заданий в вычислительную систему, состоящую их трех ЭВМ, Dtпр = 3мин;
х2 – интервал времени обработки заданий на первой ЭВМ, tЭ1 = 7;
х3 – интервал времени обработки заданий на второй ЭВМ tЭ2 = 3;
х4 – интервал времени обработки заданий на третьей ЭВМ tЭ3 = 5.
Зададим уровни вариации для каждого фактора:
Dх1 = 1, Dх2 = 4, Dх3 = 1, Dх2 = 2.
Составим матрицу плана полного факторного эксперимента
| Номер опыта | Фактор х1 | Фактор х2 | Фактор х3 | Фактор х4 |
| 0 (базовый) | 3 | 7 | 3 | 5 |
| 1 | 2 | 3 | 2 | 3 |
| 2 | 2 | 3 | 2 | 7 |
| 3 | 2 | 3 | 4 | 3 |
| 4 | 2 | 3 | 4 | 7 |
| 5 | 2 | 11 | 2 | 3 |
| 6 | 2 | 11 | 2 | 7 |
| 7 | 2 | 11 | 4 | 3 |
| 8 | 2 | 11 | 4 | 7 |
| 9 | 4 | 3 | 2 | 3 |
| 10 | 4 | 3 | 2 | 7 |
| 11 | 4 | 3 | 4 | 3 |
| 12 | 4 | 3 | 4 | 7 |
| 13 | 4 | 11 | 2 | 3 |
| 14 | 4 | 11 | 2 | 7 |
| 15 | 4 | 11 | 4 | 3 |
| 16 | 4 | 11 | 4 | 7 |
3.2 Определение требований к вычислительным средствам
Для проведения эксперимента потребуется только один персональный компьютер без внешних устройств. Время выполнения эксперимента ограничено лишь временем доступа к персональному компьютеру.
3.3 Проведение рабочих расчетов
Набор исходных данных для ввода в ЭВМ представлен в виде матрицы плана, с помощью которой в достаточном объеме исследуется факторное пространство. Получение выходных данных зависит от интерпретатора языка GPSS. Дополнительные расчеты не требуются.
3.4 Анализ результатов моделирования системы
Планирование полного факторного эксперимента с моделью позволяет вывести необходимое количество выходных данных, при этом каждый опыт соответствует одному из возможных состояний исследуемой системы. Статистические характеристики модели вычисляются в интерпретаторе языка GPSS автоматически. Проведение регрессионного, корреляционного и дисперсионного анализа не требуется.
3.5 Представление результатов моделирования
Результаты моделирования представлены в табл. 1, 2.
Коэффициент использования – это доля времени моделирования, в течение которого устройство было занято. Среднее время занятия устройства из расчета именно одним транзактом в течение времени моделирования, единица измерения - в минутах.
Таблица 1. Результаты работы устройств EVM1, EVM2, EVM3
| Номер опыта | Устройство | Кол-во раз, когда устройство было занято | Коэффициент использования | Среднее время занятия устройства | Конечное время работы устройств |
| 1 | 2 | 3 | 4 | 5 | 6 |
| 0 | EVM1 | 77 | 0,831 | 7 | 649,000 |
| EVM2 | 73 | 0,337 | 3 | ||
| EVM3 | 127 | 0,978 | 5 | ||
| 1 | EVM1 | 80 | 0,583 | 3 | 412,000 |
| EVM2 | 84 | 0,408 | 2 | ||
| EVM3 | 116 | 0,845 | 3 | ||
| 2 | EVM1 | 81 | 0,303 | 3 | 803,000 |
| EVM2 | 86 | 0,214 | 2 | ||
| EVM3 | 114 | 0,994 | 7 | ||
| 3 | EVM1 | 86 | 0,623 | 3 | 414,000 |
| EVM2 | 81 | 0,783 | 4 | ||
| EVM3 | 119 | 0,862 | 3 | ||
| 4 | EVM1 | 83 | 0,316 | 3 | 789,000 |
| EVM2 | 88 | 0,446 | 4 | ||
| EVM3 | 112 | 0,994 | 7 | ||
| 5 | EVM1 | 96 | 0.996 | 11 | 1060,000 |
| EVM2 | 83 | 0.331 | 2 | ||
| EVM3 | 117 | 0.157 | 3 | ||
| 6 | EVM1 | 89 | 0.991 | 11 | 988,000 |
| EVM2 | 91 | 0.772 | 2 | ||
| EVM3 | 109 | 0.184 | 7 | ||
| 7 | EVM1 | 87 | 0.994 | 11 | 963,000 |
| EVM2 | 87 | 0.352 | 4 | ||
| Продолжение таблицы 1 | |||||
| 1 | 2 | 3 | 4 | 5 | 6 |
| EVM3 | 113 | 0.361 | 3 | 963,000 | |
| 8 | EVM1 | 84 | 0.994 | 11 | 930,000 |
| EVM2 | 87 | 0.374 | 4 | ||
| EVM3 | 113 | 0.851 | 7 | ||
| 9 | EVM1 | 81 | 0.302 | 3 | 805,000 |
| EVM2 | 92 | 0.229 | 2 | ||
| EVM3 | 108 | 0.402 | 3 | ||
| 10 | EVM1 | 66 | 0.239 | 3 | 830,000 |
| EVM2 | 90 | 0.217 | 2 | ||
| EVM3 | 110 | 0.928 | 7 | ||
| 11 | EVM1 | 75 | 0.280 | 3 | 804,000 |
| EVM2 | 92 | 0.458 | 4 | ||
| EVM3 | 108 | 0.403 | 3 | ||
| 12 | EVM1 | 77 | 0.945 | 3 | 822,000 |
| EVM2 | 89 | 0.433 | 4 | ||
| EVM3 | 111 | 0.281 | 7 | ||
| 13 | EVM1 | 91 | 0.993 | 11 | 1008,000 |
| EVM2 | 87 | 0.336 | 2 | ||
| EVM3 | 113 | 0.173 | 3 | ||
| 14 | EVM1 | 78 | 0.975 | 11 | 880,000 |
| EVM2 | 93 | 0.211 | 2 | ||
| EVM3 | 107 | 0.851 | 7 | ||
| 15 | EVM1 | 80 | 0.992 | 11 | 887,000 |
| EVM2 | 85 | 0.383 | 4 | ||
| EVM3 | 115 | 0.389 | 3 | ||
| 16 | EVM1 | 82 | 0.988 | 11 | 913,000 |
| EVM2 | 83 | 0.364 | 4 | ||
| EVM3 | 117 | 0.897 | 7 | ||
Таблица 2. Результаты работы очередей EVMQ1, EVMQ2, EVMQ2
| Номер опыта | Устройство | Максимальное содержимое очереди | Общее кол-во входов транзактов в очередь в течение времени моделирования | Общее кол-во входов транзактов в очередь с нулевым временем ожидания | Среднее значение содержимого очереди в течение времени моделирования | Среднее время пребывания одного транзакта в очереди с учетом всех входов в очередь | Среднее время пребывания одного транзакта в очереди без учета «нулевых» входов в очередь |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 0 | EVMQ1 | 4 | 77 | 12 | 1,020 | 8,597 | 10,185 |
| EVMQ2 | 2 | 73 | 65 | 0,020 | 0,178 | 1,625 | |
| EVMQ3 | 9 | 127 | 4 | 3,488 | 17,827 | 18,407 | |
| 1 | EVMQ1 | 2 | 80 | 43 | 0,160 | 0,825 | 1,784 |
| EVMQ2 | 2 | 84 | 65 | 0,070 | 0,345 | 1,526 | |
| EVMQ3 | 6 | 116 | 30 | 1,063 | 3,776 | 5,093 | |
| 2 | EVMQ1 | 2 | 81 | 50 | 0,062 | 0,617 | 1,613 |
| EVMQ2 | 2 | 86 | 57 | 0,055 | 0,512 | 1,517 | |
| EVMQ3 | 57 | 114 | 1 | 27,928 | 196,719 | 198,460 | |
| 3 | EVMQ1 | 2 | 86 | 48 | 1,162 | 0,779 | 1,763 |
| EVMQ2 | 6 | 81 | 15 | 1,179 | 6,025 | 7,394 | |
| EVMQ3 | 8 | 119 | 28 | 1,645 | 5,723 | 7,484 | |
| 4 | EVMQ1 | 2 | 83 | 40 | 0,106 | 1,012 | 1,953 |
| EVMQ2 | 6 | 88 | 16 | 0,790 | 7,080 | 8,653 | |
| EVMQ3 | 55 | 112 | 1 | 28,999 | 204,286 | 206,126 | |
| 5 | EVMQ1 | 60 | 96 | 1 | 28,930 | 319,438 | 322,800 |
| EVMQ2 | 1 | 83 | 81 | 0,002 | 0,024 | 1,000 | |
| EVMQ3 | 2 | 117 | 81 | 0,070 | 0,632 | 2,056 | |
| 6 | EVMQ1 | 52 | 89 | 1 | 25.302 | 280.876 | 284.068 |
| EVMQ2 | 1 | 91 | 87 | 8.890 | 80.578 | 92.453 | |
| EVMQ3 | 25 | 109 | 14 | 0.005 | 0.055 | 1.250 | |
| 7 | EVMQ1 | 51 | 87 | 1 | 24.082 | 266.563 | 269.663 |
| EVMQ2 | 3 | 87 | 48 | 0.073 | 0.619 | 2.059 | |
| EVMQ3 | 2 | 113 | 79 | 0.134 | 1.483 | 3.308 | |
| 8 | EVMQ1 | 48 | 84 | 1 | 23.465 | 259.786 | 262.916 |
| EVMQ2 | 4 | 87 | 56 | 0.154 | 1.644 | 4.613 | |
| EVMQ3 | 30 | 113 | 11 | 10.389 | 85.504 | 94.725 | |
| 9 | EVMQ1 | 1 | 81 | 81 | 0.000 | 0.000 | 0,000 |
| Продолжение таблицы 2 | |||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| EVMQ2 | 1 | 92 | 85 | 0.009 | 0.296 | 0,076 | |
| EVMQ3 | 1 | 108 | 91 | 0.040 | 0.076 | 0,296 | |
| 10 | EVMQ1 | 1 | 66 | 66 | 0,000 | 0,000 | 0,000 |
| EVMQ2 | 1 | 90 | 87 | 0,004 | 0,033 | 1,000 | |
| EVMQ3 | 7 | 110 | 12 | 3,117 | 23,518 | 26,398 | |
| 11 | EVMQ1 | 1 | 75 | 75 | 0,000 | 0,000 | 0,000 |
| EVMQ2 | 1 | 92 | 71 | 0,078 | 0,685 | 3,000 | |
| EVMQ3 | 1 | 108 | 86 | 0,047 | 0,352 | 1,727 | |
| 12 | EVMQ1 | 1 | 77 | 77 | 0,000 | 0,000 | 0,000 |
| EVMQ2 | 1 | 89 | 80 | 0,033 | 0,303 | 3,000 | |
| EVMQ3 | 5 | 111 | 10 | 1,491 | 11,045 | 12,139 | |
| 13 | EVMQ1 | 19 | 91 | 1 | 8,268 | 95,571 | 96,633 |
| EVMQ2 | 1 | 87 | 80 | 0,008 | 0,092 | 1,143 | |
| EVMQ3 | 1 | 113 | 94 | 0,032 | 0,283 | 1,684 | |
| 14 | EVMQ1 | 7 | 78 | 4 | 2,802 | 31,615 | 33,324 |
| EVMQ2 | 1 | 93 | 88 | 0,007 | 0,065 | 1,200 | |
| EVMQ3 | 5 | 107 | 27 | 0,956 | 7,860 | 10,512 | |
| 15 | EVMQ1 | 12 | 80 | 2 | 5,781 | 64,100 | 65,774 |
| EVMQ2 | 2 | 85 | 69 | 0,054 | 0,565 | 3,000 | |
| EVMQ3 | 1 | 115 | 87 | 0,057 | 0,443 | 1,821 | |
| 16 | EVMQ1 | 10 | 82 | 1 | 4,525 | 50,378 | 51,000 |
| EVMQ2 | 2 | 83 | 65 | 0,041 | 0,446 | 2,056 | |
| EVMQ3 | 5 | 117 | 15 | 1,388 | 10,829 | 12,422 | |
3.6 Интерпретация результатов моделирования
Полученные результаты можно интерпретировать следующим образом.
Согласно целевой функции оптимальными вариантами модели являются опыты № 3, 9, 11, т.к. ЭВМ1, ЭВМ2 и ЭВМ3 загружены равномерно, максимальная длина очередей перед каждой ЭВМ в течение моделирования минимальна.
Это объясняется тем, что в 9 и 11 опытах задания поступают реже – каждые 4 минуты, в то время как время обработки заданий на каждой из ЭВМ минимально, именно поэтому в этих случаях коэффициент использования более равномерно распределен, по сравнению с другими опытами (9: 0,302; 0,229; 0,422. 11: 0,28; 0,458; 0,403 соответственно).
При этом данные опыты являются лучшими для минимизации длины очередей перед каждой ЭВМ в отдельности (9: 1,1,1. 11: 1,1,1 соответственно). Опыт №3 тоже по-своему отвечает целевой функции – длина очередей перед каждой ЭВМ минимальна, по сравнению с другими опытами (2,6,8 соответственно), но лучшим опыт является не только из-за более или менее равномерного распределения загрузки между ЭВМ, но и из-за максимизации коэффициента использования, которые всех ближе к единице и при этом еще и почти равны между ЭВМ (0,623; 0, 723; 0,862 соответственно).
Наихудшими вариантами модели являются опыты № 5, 6, 8, т.к. загруженность ЭВМ неравномерна, максимальная длина очередей перед каждой ЭВМ в течение моделирования огромна. Это объясняется тем, что в 5, 6 и 8 опытах задания поступают чаще - каждые 2 минуты, в то время как время обработки заданий на каждой из ЭВМ разбросано в большом интервале времени (от 3 до 11 минут), именно поэтому в этих случаях коэффициент использования также разбросан в интервале от 0 до 1 по сравнению с другими опытами (5: 0,996; 0,331; 0,157. 6: 0,991; 0,772; 0,184. 8: 0,994; 0,374; 0,851. Соответственно).
Также данные опыты являются наихудшими в показателях по минимизации длины очередей перед каждой ЭВМ в отдельности (5: 60, 1, 2. 6: 52, 1, 25. 8: 48, 4, 30. Соответственно). Опыт № 5 является измерителем максимально возможной длины очереди перед ЭВМ (в данном случае перед ЭВМ1), при решении в процессе моделирования 200 заданий с заданными условиями задачи.
3.7 Подведение итогов моделирования и выдача рекомендаций
Результаты моделирования при проведении машинного эксперимента подтвердили следующие гипотезы для базовой точки эксперимента:
- если интенсивность поступления заданий в ВС будет меньше времени обработки заданий на каждой из ЭВМ, то коэффициент загрузки каждой из ЭВМ будет возрастать, и, как следствие, будет увеличиваться количество поступивших заданий в ВС, которые образуют длинные очереди;
- первая ЭВМ обрабатывает меньше заданий двух других ЭВМ и при этом в большинстве случаев имеет длину очереди всегда больше длины очереди ко второй ЭВМ;
- третья ЭВМ обрабатывает всегда больше заданий, чем две другие ЭВМ по отдельности.
Рекомендации по практическому использованию результатов моделирования следующие:
· для получения более высокого коэффициента использования каждой ЭВМ одновременно, нужно уменьшить время интенсивности поступления заданий в систему, при этом время обработки на каждой ЭВМ должны быть почти равны (например, у первой и третьей ЭВМ одинаковы, а у второй отличаться на единицу);
· для минимизации очереди нужно увеличить время интенсивности поступления заданий, при этом время обработки заданий на каждой из ЭВМ должно быть меньше или даже равно интенсивности поступления.