«информационные технологии как средство накопления, упорядочивания и обмена биологической информацией»
СОДЕРЖАНИЕ: Реферат на тему «информационные технологии как средство накопления, упорядочивания и обмена биологической информацией» 4БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Выпускная работа по
«Основам информационных технологий»
Магистранта
биологического факультета
кафедры микробиологии
Кудина Кирилла Валерьевича
Руководители:
профессор Прокулевич Владимир Антонович
ассистент Шешко Сергей Михайлович
Минск 2010 г.
Оглавление
Перечень условных обозначений. 3
1.2 Основные принципы организации и работы базы данных GeneBank. 7
1.3 Для чего людям нужен BLAST. 9
Глава 2. Методика исследования. 11
Глава 3. Основные результаты.. 12
Глава 4. Обсуждение результатов. 13
Список литературы к реферату. 14
Предметный указатель к реферату. 15
Интернет ресурсы в предметной области исследования. 16
Действующий личный сайт в WWW... 18
тестовые вопросы по основам информационных технологий. 20
Вопрос по ИТ в предметной области. 20
Презентация магистерской диссертации. 21
СПИСОК ЛИТЕРАТУРЫ К ВЫПУСКНОЙ РАБОТЕ. 22
Перечень условных обозначений
ДНК – дезоксирибонуклеиновая кислота
ПЦР – полимеразная цепная реакция
тпн – тысяч пар нуклеотидов
BLAST – Basic Local Alignment Search Tool
Реферат на тему «информационные технологии как средство накопления, упорядочивания и обмена биологической информацией»
Введение
Современная эпоха развития молекулярно-биологических исследований и внедрения биотехнологий в обыденную практику началась с окончательного выяснения Дж. Уотсоном и Ф. Криком в 1953 году факта, что «веществом наследственности» является ДНК. Это открытие дало толчок к определению истинной природы гена и раскрытию ряда молекулярных механизмов, лежащих в основе функционирования живой клетки, а огромные возможности и манящие перспективы, которые виделись в знании генной структуры геномов организмов, подстегнули человечество к разработке методов расшифровки этих самых геномов.
Наиболее известный, массовый и дорогостоящий проект, связанный с расшифровкой генома, официально был запущен в 1990 году в США под руководством Дж. Уотсона и назывался «Геном человека». В его осуществлении приняли участие множество университетов и лабораторий по всему миру, а общие затраты превысили 3 млрд. долларов США. Проект завершился в 2003 году, когда была опубликована вся полученная в процессе работы информация о геноме, однако собранные данные до сих пор уточняются и редактируются [1]. Впоследствии, разработка новых методов сиквенирования ДНК (определения ее первичной нуклеотидной последовательности) и совершенствование старых привели к тому, что в настоящее время, для сравнения, полную информацию по любому геному можно получить в частном порядке в течение трех месяцев, при этом стоимость услуги составляет менее 100 тыс. долларов США и эта цена неуклонно снижается (к примеру, фирма Knome собирается в ближайшем будущем предложить услуги по сиквенированию индивидуальных геномов по расценкам 1 доллар за ген) [2, 3].
Одновременно с выяснением нуклеотидных последовательностей генома человека проводилась (и до сих пор проводится) работа по расшифровке структуры геномов и множества других организмов. Это, в конце концов, привело к появлению огромного массива информации, который с каждым днем расширялся и дополнялся. По мере накопления данных о геномах возникла необходимость их упорядочивания, постоянного обновления и создания системы удобного доступа к ним, с этой целью на основе нескольких университетов были созданы базы данных нуклеотидных последовательностей, обеспечивающие легкий поиск нужного сегмента информации, ориентировку в последовательностях, их сравнение, и многие другие весьма полезные функции. Однако накопленные данные не более чем простой электронный «каталог», ценность которого определяется лишь теми практически значимыми результатами, которые невозможно было бы получить без использования этого «каталога». Для примера можно привести следующую жизненную ситуацию, характерную в том числе и для Беларуси: имеется два типа вирусов свиней – первый тип вируса - PCV1, - является безобидным проявлением многообразия форм жизни, он непатогенный и не приносит никакого ущерба, второй тип вируса - PCV2, – возбудитель опасного системного заболевания, называемого синдром мультисистемного истощения отъемышей (СМИО) и являющегося причиной огромных убытков в свиноводстве большинства государств, знакомых с этой отраслью сельского хозяйства. При этом оба типа вирусов часто обнаруживаются в одном организме одновременно, а их геномы идентичны на 86% - это означает, что такая простая, дешевая и широко используемая в диагностике вирусов биологическая процедура как ПЦР становится делом весьма сложным, и своевременно определить опасный вирус PCV2 в организме животного для предотвращения развития эпидемии почти невозможно. Теперь встает законный вопрос, который может оправдать (или не оправдать) огромные средства, затрачиваемые не поддержание такого международного научного ресурса как нуклеотидные базы данных – а возможно ли используя информацию такой базы данных подобрать условия, позволяющие дифференцировать оба типа вирусов? Достаточно ли исчерпывающа информация ресурса и надежны алгоритмы ее обработки для того, чтобы оказалось возможным, не прибегая к собственным затратным внутренним исследованиям по расшифровке и уточнению последовательностей геномов вирусов, быстро создать систему идентификации патогенного PCV2, позволяющую диагностировать вирус на достаточно ранних стадиях инфицирования, чтобы оказалось возможным предотвратить распространение заболевания? В связи с поставленными вопросами цель исследования можно сформулировать следующим образом: определение возможности использования информационных технологий в области диагностической биологии. Задачи:
- выяснить структуру нуклеотидных баз данных и механизм их работы;
- изучить электронные инструменты, применяемые в области аннотации геномов;
- создать систему биологической проверки, позволяющую оценить эффективность использования ИТ в диагностических экспериментах.
Глава 1. Обзор литературы
1.1 Как все начиналось
Первая электронная база данных Los Alamos DNA Database, содержащая информацию о сиквенированных последовательностях ДНК, была организована У. Гоадом в Лос-Аламосской национальной лаборатории в США в 1979 году. К 1981 в ней уже содержалась информация о 280 опубликованных нуклеотидных последовательностях общей протяженностью 370 тпн. В 1982 году на ее основе под опекой Национального института здоровья (National Institutes of Health, NIH) был организован новый банк данных генетических последовательностей и кодируемых ими белков – GeneBank, существующий и поныне [4]. На первых этапах основная задача рабочего состава GeneBank заключалась в изучении литературы и поиске опубликованных нуклеотидных последовательностей, которые затем вручную переводились в электронную форму банка данных. Сейчас подобная работа стала редким исключением, поскольку большинство научных журналов отказалось от практики опубликования расшифрованных последовательностей в оригинальных статьях и требуют, чтобы исследователи самостоятельно пересылали данные в любые открытые базы данных, а в статьях приводили присвоенный данной последовательности инвентарный номер, по которому ее легко возможно отыскать в случае необходимости. В настоящее время, объем информации, находящейся в распоряжении GeneBank, быстро растет, удваиваясь каждые 10 месяцев [4, 5, 6].
GeneBank является американской базой данных и финансируется правительством США, хотя и содержит теперь информацию, собранную со всего мира. Созданная в 1980 году в Европе аналогичная база данных EMBL Data Library (European Molecular Biology Laboratory) задумывалась как интернациональный проект и стала первым международным хранилищем такого рода информации, предназначенным для обеспечения бесплатного доступа к коллекциям опубликованных нуклеотидных последовательностей, выработки определенных стандартов и развития информационного и компьютерного обеспечения проводимых молекулярно-биологических исследований. Свой первый релиз, охватывающий информацию о 568 последовательностях общей протяженностью 585`433 тпн, EMBL выпустила в апреле 1982 года. Первое время очередные релизы распространялись на магнитных лентах и предоставлялись по запросу любому желающему, позже увеличение числа пользователей и рост базы привели к тому, что дальнейшие выпуски стали распространяться по подписке. В 1994 г. EMBL Data Library трансформировалась в EMBL Nucleotide Sequence Database и стала курироваться Европейским институтом биоинформатики (European Bioinformatics Institute, или EBI)[4, 7].
С 1986 года в Японии начал функционировать еще один банк данных DDJB (DNA Data Bank of Japan). В 1995 году, когда в Японии был создан Центр информационной биологии (CIB), ресурс DDJB перешел к нему в подчинение [4, 8].
В середине 90-х годов все три базы данных – GeneBank, EMBL и DDJB – были объединены в рамках международного проекта в единое информационное пространство – Международную Базу Данных Нуклеотидных Последовательностей (International Nucleotide Sequence Database, или сокращенно INSD). В настоящее время эти базы данных, обладая своим набором источников и собственными инструментами поиска и обработки информации, в конечном счете, содержат идентичные наборы последовательностей, поскольку ежедневно обмениваются информацией. А благодаря разработанным единым правилам аннотации геномов и синтаксиса, при различном формате данных и способе их предоставления в разных базах, лежащая в их основе биологическая информация имеет одинаковый и понятный каждому смысл.
1.2 Основные принципы организации и работы базы данных GeneBank
Типичная форма данных, пригодная для помещения в GeneBank, представляет собой непрерывный отрезок последовательности ДНК или РНК, который на первый взгляд выглядит как бессмысленное и беспорядочное чередование четырех букв – А, Т, Г, Ц (например «..atggcagat..») – каждая из которых на самом деле соответствует конкретному азотистому основанию в цепочке нуклеиновой кислоты и, распределяясь по ней в определенном порядке, формирует уникальную и неповторимую для данного отрезка строку генетического кода. Такой участок нуклеиновой кислоты, как правило, содержит аннотацию, в которой поясняется биологический смысл последовательности. Для облегчения работы исследователей при передаче новых расшифрованных последовательностей в GeneBank существуют два программных инструмента – BankIt и Sequin (на самом деле существует несколько путей поступления информации в GeneBank, например, из крупных сиквенирующих центров поток данных может идти в автоматическом режиме, в данном случае речь идет о непосредственной передаче имеющихся в распоряжении исследователя данных, как более простом, часто используемом и доступном каждому ученому варианте).
BankIt является web-инструментом и представляет собой, по сути, электронную анкету с развернутыми пояснениями – каким образом и какие поля заполнять. BankIt используется в случаях, когда количество предоставляемых в банк последовательностей мало, а структура их проста (или информации о них мало) – это наиболее простой способ помещения новой последовательности в GeneBank. После внесения всей доступной исследователю информации о регистрируемой последовательности в анкету, производится ее первичный автоматический анализ – поиск внутренних ошибок и противоречий при сопоставлении, например, введенной исследователем цепочки нуклеотидов и ее аминокислотного «перевода» (если речь идет о кодирующем сегменте), проверяется наличие не относящихся к последовательности и не являющихся уникальными фрагментов клонирующих векторов и др. При обнаружении каких-либо недочетов или ошибок в заполненной анкете, пользователя просят их исправить на месте. Введенные данные сохраняются в виде неструктурированного файла, который передается на сервер для более глубокого анализа. Если процедура всесторонней проверки данных прошла успешно, пользователю приходит электронное письмо с подтверждением внесения предлагаемой им последовательности в базу данных GeneBank [6, 9].
Инструмент Sequin предназначен для более сложных случаев и представляет собой загружаемое под определенную операционную систему приложение (хотя относительно недавно появилась его web-разновидность). Данный инструмент, в сравнении с BankIt, обладает более широким набором возможностей для редактирования и описания последовательностей нуклеиновых кислот, помещаемых в Genebank, соответственно, он используется при работе со сложно организованными и хорошо изученными сегментами ДНК (РНК), содержащими большое количество подлежащих аннотации геномных элементов [6, 9, 10].
Все последовательности, направленные в GeneBank посредством инструментов BankIt или Sequin, анализируются штатом квалифицированных сотрудников базы данных, специализирующихся в области аннотации геномов. Обработка входящих запросов производится в два этапа, первый этап называется «Сортировка» и сводится он, по сути, к оценке качества предоставленной последовательности генома. В течение 48 часов с момента поступления последовательности специалисты проверяют ее на соответствие минимальным критериям, необходимым для помещения в GeneBank - полнота последовательности (отсутствие нерасшифрованных участков), ее происхождение (принимаются только естественные последовательности реально существующих организмов), размеры (минимальные – 0,05 тпн ) и др. Итогом этапа сортировки становится присвоение последовательности т.н. инвентарного номера, состоящего из 2-х букв и 6 цифр (для примера, полная последовательность генома одного из штаммов вируса PCV2 имеет инвентарный номер FJ935780)[6, 11].
Следующий за сортировкой этап представляет собой углубленный анализ присланной последовательности и называется фазой индексирования. Он заключается во всесторонней проверке таких пунктов, как:
1. Отсутствие биологических ошибок. Например, это может быть соответствие нуклеотидной последовательности гена и аминокислотной последовательности кодируемого этим геном белка, указанные исследователем в запросе.
2. Отсутствие случайных фрагментов векторов, использовавшихся при работе с последовательностью и не относящихся непосредственно к ней.
3. Поиск и создание внутренних связей и ссылок между помещенной в GeneBank последовательностью и относящимися к ней публикациями и комментариями, если таковые имеются.
4. Поиск и исправление неточностей в формате данных и аннотации.
Как можно заметить, некоторые элементы первичного и углубленного анализа пересекаются или дублируются, гарантируя, в конечном итоге, более высокий уровень качества обработки поступающих в огромных объемах данных (на сегодняшний день это около 20`000 последовательностей в месяц). Завершенные работы высылаются отправителям для проверки – на внесение корректировок, если они необходимы, отводится 5 дней. При желании исследователи могут попросить сместить сроки размещения последовательности в открытом доступе в GeneBank до выхода их статьи – это позволяет застраховаться, к примеру, от возможных споров за место первооткрывателя. По завершении всех проверок отредактированные последовательности сохраняются в виде фалов с расширением ASN.1. ASN.1 представляет собой дескрипторный язык, который позволяет подробно описывать хранимые последовательности и всю относящуюся к ним информацию [11].
В своей работе сотрудники GeneBank используют большое количество программных инструментов, позволяющих упросить процесс обработки данных и повысить его эффективность. Эти инструменты весьма удобны и универсальны, а потому любезно открыты для доступа широкому кругу пользователей GeneBank. Наиболее важным из них для данного исследования является BLAST (от англ. Basic Local Alignment Search Tool).
1.3 Для чего людям нужен BLAST
Программа BLAST была разработана в 1990 году под руководством Altschul S. как средство поиска и сопоставления нуклеотидных и белковых последовательностей. В ее основе лежат надежные алгоритмы выявления близкородственных участков разных последовательностей (ускоренный почти в 50 раз аналог алгоритма Смита-Ватермана) и функции статистической обработки результатов, которые обусловили ее повсеместное использование в научной практике. Программа доступна в автономной форме и в качестве web-приложения и имеет целый ряд разновидностей, каждая из которых оптимизирована для работы с определенными типами данных, охватывая лишь конкретное поле научных изысканий. К примеру, разновидность blastn предназначена для сравнения и поиска сходных участков в нуклеотидных последовательностях, а разновидность blastx переводит введенную нуклеотидную последовательность в белковую и сравнивает с базами данных по белкам и т.п. [6, 12].
Попав на web-страницу BLAST, исследователь вводит желаемую последовательность и задает параметры сопоставления – база данных для сравнения, размер слова, ожидаемое значение и т.п., с учетом всей входящей информации сервер BLAST приступает к реализации заложенных алгоритмов.
При сопоставлении двух или нескольких последовательностей между собой, BLAST осуществляет то, что по-научному называется «локальное выравнивание». Локальное выравнивание заключается в том, что программа делит всю введенную исследователем последовательность на ряд небольших отрезков равной длины, которые организуются в форме таблицы, эти отрезки называются «словами», а длина отрезка называется «размером слова». Для наглядности представим маленькую цепочку ДНК из 8 звеньев в виде текста «крокодил» и введем эту последовательность в BLAST, задав размер слова равный 6. Руководствуясь установленными нами параметрами для сравнения (размер слова 6), программа BLAST разбивает введенную цепочку на ряд отрезков, из которых формируется рабочая таблица, в данном случае с учетом длин последовательности и размера слова таких отрезков будет три – крокод (крокод ил), рокоди (крокоди л) и окодил (крокодил ). Далее для каждого слова таблицы производится его сопоставление с последовательностями всех подразделений базы данных, выбранных пользователем для сравнения, с целью отыскать наиболее похожие участки. Эти участки становятся центрами поиска для следующего этапа работы. К примеру, BLAST нашел полное совпадение слова рокоди с участком одной из последовательностей базы данных, далее он начинает это слово продлевать в обе стороны, достраивая его по бокам до полного слова крокодил и сравнивая после очередного добавления буквы с найденной последовательностью, чтобы определить, насколько обширна область сходства. При каждом таком совпадении производится оценка степени близости фрагментов друг другу – в зависимости от количества совпадающих букв в расширенном слове и от расположения совпавших букв относительно несовпавших (т.е. при анализе буквы не обязательно должны составлять непрерывный ряд совпадений) начисляются (либо снимаются) очки, чем больше набрано очков, тем выше степень родства двух фрагментов, причем программа при работе учитывает только те случаи совпадения, которые набрали количество очков выше определенного значения, называемого пороговой величиной Т (устанавливается пользователем в параметрах программы перед запуском). BLAST осуществляет поиск не непосредственно в подразделениях базы данных GeneBank, а в сформированных на ее основе собственных базах данных, которые организованы так, чтобы максимально сократить время поиска и увеличить его эффективность.
Кроме того, при выводе результатов, напротив каждого из них BLAST отображает величину E (от англ. Expect value), которая является уровнем значимости и определят достоверность каждого конкретного результата. Например, E=0,05 означает: вероятность того, что найденное сходство случайно составляет 5%.
Важным является то, что BLAST способен предоставлять результаты поиска в нескольких форматах без перезапуска, и пользователь может сравнить и выбрать наиболее для него приемлемый. Это возможно благодаря тому, что результаты работы сохраняются в формате ASN.1, который быстро трансформируется утилитой BLAST formatter в определнного вида html, наиболее предпочтительный для пользователя [6, 12, 13].
Глава 2. Методика исследования
Для проведения эксперимента, способного продемонстрировать эффективность/неэффективность использования ИТ в области диагностической биологии, планировалось с помощью одного из программных приложений GeneBank разработать пару праймеров, позволяющих в условиях обычной лаборатории производить достоверное определение вируса PCV2 с помощью простой реакции ПЦР. Для работы было использовано web-приложение Primer-BLAST, представляющее собой гибрид двух широко использующихся в молекулярно-биологической практике программ – Primer 3 и упомянутого выше BLAST.
Праймеры – короткие одноцепочечные фрагменты ДНК с известной и заданной последовательностью нуклеотидов, которые при определенных условиях (соответствие нуклеотидов, температуры и др.) могут связываться с длинными и также одноцепочечными нитями ДНК (называемыми матрицами), создавая короткие двухцепочечные участки, служащие центрами связывания с ферментами, осуществляющими удлинение этих двухцепочечных участков до определенного размера (образуются т.н. продукты). За счет многократного повторения этапа связывания праймеров с матрицей и синтеза двухцепочечных продуктов в ходе реакции накапливается большое количество одинаковых фрагментов, которые можно легко определить, к примеру, с помощью электрофореза. Сама по себе программа Primer 3 используется для поиска на основе введенной последовательности ДНК всех праймеров, соответствующих заданным условиям ПЦР, она учитывает множество основных параметров, которые вручную определить очень сложно (если вообще возможно), например, температура плавления праймеров, сложность структуры последовательности и др. Таким образом, после установки всех необходимых параметров, Pimer-BLAST производит поиск результатов, соответствующих заданным критериям, осуществляя их сортировку по двум направлениям – соответствие условиям проведения ПЦР (с помощью компонента Primer 3) и соответствие заданному уровню уникальности (специфичности) праймера (с помощью компонента BLAST).
При работе в Primer-BLAST были заданы две группы основных параметров. Первая группа параметров определяла условия проведения ПЦР – температура плавления праймеров (57-63°С), размер продукта (0,7-1,1 тпн) и т.п. Вторая определяла условия поиска родственных последовательностей, которые следовало исключить из результатов, чтобы оставить наиболее специфичные и уникальные праймеры – размер слова (7), пороговая величина (50000), разделы базы данных для сравнения (заданны геномы PCV1 и свиньи Sus scrofa, на основе образцов которой проводился эксперимент) и т.п.
Из предоставленных программой результатов был выбран один, наиболее соответствующий, с точки зрения специфичности, задачам эксперимента (см. таблица 1). После получения праймеров проводилась ПЦР с последующим электрофорезом (разделением молекул синтезированного продукта в геле в электрическом поле).
Таблица 1 - Характеристики отобранных праймеров.
| Название праймера |
Последовательность , 5’ 3’ |
Длина , n |
GC , % |
Tm гетеродимера , o C |
| F1_OUT_PCV2 |
GGAAGAATGCTACAGAACAATCCA |
24 |
41.67 |
14,6 |
| R1_OUT_PCV2 |
GATTATTCAGCGTGAACACCCAC |
23 |
47.83 |
35,6 |
Глава 3. Основные результаты
Результаты проведенного эксперимента представлены на рисунке 1 в виде фотографии геля, в котором проводилось разделение полученных продуктов ПЦР.
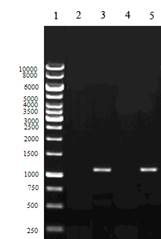
Рисунок 1 –Фотография результатов электрофореза ПЦР в агарозном геле
На дорожке 1 для сравнения ДНК-маркеры молекулярного размера, представляющие собой набор двухцепочечных молекул ДНК различных длин (размеры соответствующих фрагментов подписаны слева). На дорожке 2 – результат реакции с геномом вируса PCV1 (продукт отсутствует), на дорожке 3 результат реакции с геномом вируса PCV2 (виден продукт размером около 1 тпн), на дорожке 4 продукт реакции генома здоровой свиньи Sus scrofa (продукт отсутствует), на дорожке 5 виден продукт реакции, размером около 1 тпн, с геномом свиньи, инфицированной вирусом PCV2. Как следует из фотографии, реакция прошла исключительно в тех пробах, где в том или ином виде присутствовала последовательность генома вируса PCV2, при этом пробы с очень близким к нему вирусом PCV1 и геномом свиньи оказались отрицательными.
Глава 4. Обсуждение результатов
В соответствии с поставленной задачей для проведения эксперимента была разработана пара праймеров, использованных в ПЦР для определения возможности их применения в диагностике заболевания СМИО, вызываемого вирусом PCV2. Исходя из результатов, приведенных на рисунке 1, можно заключить, что полученные праймеры являются специфическими и обеспечивают обнаружение генома вируса PCV2 как в чистых пробах, так и в пробах, содержащих дополнительно постороннюю геномную ДНК (дорожки 3 и 5), кроме того, отсутствует неспецифическая реакция с близким геномом вируса PCV1, а также с ДНК хромосом свиньи, поскольку в обоих указанных случаях однозначно получены отрицательные результаты. Следовательно, разработанные праймеры пригодны для проведения подобного рода исследований и могут быть использованы в практической диагностике для идентификации инфекции PCV2.
Заключение
В ходе работы с помощью программного обеспечения Primer-BLAST и на основе данных, имеющихся в распоряжении ресурса GeneBank, была разработана пара уникальных праймеров, с помощью которых проводилась ПЦР-диагностика на предмет возможности достоверного выявления скрытой инфекции PCV2 в организмах свиней. Из полученных во время проведения эксперимента результатов следует, что разработанные праймеры специфичны и позволяют проводить диагностику с помощью ПЦР в лабораторных условиях. Кроме того, примененная в ходе работы технология по созданию праймеров для диагностических целей может быть перенесена на другие виды заболеваний, вызываемых инфекционными агентами, для которых еще не существует подобных систем.
Полученные результаты свидетельствуют в пользу того, что современный уровень развития ИТ в области поддержания, обслуживания и использования ресурсов банков данных нуклеотидных последовательностей, а также полнота и точность предоставленной в них информации, в частности речь идет о GeneBank, позволяют эффективно разрабатывать средства диагностики в области ПЦР, и заниматься исследовательской деятельностью, связанной со структурой геномов.
Список литературы к реферату
1. Официальная информационная страница проекта «Геном человека» [Электронный ресурс] / U.S. Department of Energy Office of Science. – Режим доступа: http://www.ornl.gov/sci/techresources/Human_Genome/home.shtml. – Дата доступа 05.01.2011.
2. Официальный сайт компании Knom, предлагающей услуги по сиквенированию и аннотации генома человека [Электронный ресурс] / Knome, 2010. – Режим доступа: http://www.knome.com. – Дата доступа 05.01.2011.
3. Электронная версия английского журнала Bio-IT World, освещающего последние и важнейшие достижения в области биологических и медицинских исследований [Электронный ресурс] / Cambridge Healthtech Institute, . – Режим доступа: http://www.bio-itworld.com/news/05/18/09/knome-exome-sequencing-service.html. – Дата доступа 05.01.2011.
4. Щелкунов, С.Н. Базы данных нуклеотидных и аминокислотных последовательностей / С.Н. Щелкунов // Генетическая инженерия / С.Н. Щелкунов. – Новосибирск: Сибирское университетское издательство, 2004. Гл. 1. – С. 9-80.
5. Банк данных GeneBank, содержащий все когда-либо опубликованные генетические нуклеотидные последовательности [Электронный ресурс] / National Center for Biotechnology Information, National Library of Medicine, USA. – Режим доступа: http://www.ncbi.nlm.nih.gov/genbank/. – Дата доступа 05.01.2011.
6. Mizrachi, I. GenBank: The Nucleotide Sequence Database / I. Mizrachi // The NCBI Handbook / J. McEntyre, J. Ostell. – USA, 2002. – Ch. 1. P. 1-11.
7. Европейская база данных, аналог GeneBank [Электронный ресурс] / European Bioinformatics Institute, 2010. – Режим доступа: http://www.ebi.ac.uk/embl/.– Дата доступа 05.01.2011.
8. Японская база данных, аналог GeneBank [Электронный ресурс] / DNA Data Bank of Japan, 2010. – Режим доступа: http://www.ddbj.nig.ac.jp/.– Дата доступа 05.01.2011.
9. Olson, M. A common language for physical mapping of the human genome / M. Olson [et al.] // Science. – 1989. – Vol. 245(4925). – P. 1434–1435.
10. Kans, J. Sequin: A Sequence Submission and Editing Tool / J. Kans // The NCBI Handbook / J. McEntyre, J. Ostell. – USA, 2002. – Ch. 12. P. 155-166.
11. Sirotkin, K. The Processing of Biological Sequence Data at NCBI / K. Sirotkin [et al.] // The NCBI Handbook / J. McEntyre, J. Ostell. – USA, 2002. – Ch. 12. P. 166-174.
12. Altschul, S.F. Basic local alignment search tool / S.F. Altschul [et al.] // J. Mol. Biol. – 1990. – Vol. 215. – P. 403–410.
13. Mount, W.D. Alignment of pairs of sequences / W.D. Mount // Bioinformatics. Sequence and genome analisys / W.D. Mount. – Cold Spring Harbor Laboratory Press, 2001. – Ch. 3. – P. 52-141.
Предметный указатель к реферату
A
ASN.1, 9, 11
B
BankIt, 7, 8, 21
BLAST, 3, 9, 10, 11, 12, 14, 17, 21
D
DDJB, 7
E
EMBL, 6, 7
G
GeneBank, 6, 7, 8, 9, 11, 14, 15
K
Knome, 4, 14, 23
P
PCV1, 13
PCV2, 5, 11, 12, 13
Primer 3, 11, 12, 17
S
Sequin, 7, 8, 15, 21
Sus scrofa, 12, 13
Д
ДНК, 3, 4, 6, 7, 8, 10, 11, 13
П
ПЦР, 3, 5, 11, 12, 13, 14, 17
Р
РНК, 7, 8
С
СМИО, 5, 13
Интернет ресурсы в предметной области исследования.
http://molbiol.edu.ru/
Сайт интересен с практической точки зрения для всех заинтересованных и занятых в молекулярно-биологической работе исследователей. Содержит множество полезных разделов, наиболее полезные из которых следующие:
- FULL TEXT. Там можно бесплатно заказать электронные версии статей, которые отсутствуют в свободном доступе.
- МЕТОДЫ. Можно получить совет или узнать много полезного о какой-либо лабораторное методике.
- РАСЧЕТЫ. Набор web-приложений облегчающих рутинные расчеты в лабораторной практике.
- ЛИТЕРАТУРА. Можно найти редкие и ценные книги в электронном варианте.
http://www.basic.northwestern.edu/biotools/OligoCalc.html
Так называемый OligoCalc, или Олигокалькулятор. Очень удобен, если необходимо произвести быструю оценку свойств одноцепочечных или двухцепочечных олигонуклеотидов (например, рассчитать их молекулярный вес, определить концентрацию по оптической плотности и т.п.).
http://www.bioinformatics.nl/cgi-bin/primer3plus/primer3plus.cgi
Primer 3 Plus – усовершенствованная версия программы Primer 3, лежащей в основе упомянутой в реферате Primer-BLAST. Это высокоспециализированная программа для подбора праймеров в ПЦР, содержит большое количество всевозможных настраиваемых параметров, позволяющих с большой эффективностью планировать эксперимент. Одна из лучших в этой области программ.
http://blast.ncbi.nlm.nih.gov/Blast.cgi
Одна из самых эффективный и «продвинутых» программ в области поиска гомологичных последовательностей, оптимизированные алгоритмы поиска и заложенные статистические функции позволяют быстро проводить поиск по всевозможным базам данных и сопровождать результаты поиска статистическими оценками его значимости.
http://www.ncbi.nlm.nih.gov/pubmed
PubMed представляет собой огромное хранилище разнообразной биологической и медицинской литературы (но в основном это статьи). Хорошо поставленная система поиска позволяет быстро и легко найти нужную информацию. Значительная часть статей, входящих в список литературы курсовых и дипломных работ происходит именно отсюда.
http://scholar.google.com/
Поисковый раздел Google, специализирующийся исключительно на поиске научной литературы в Интернете. Позволяет найти книги, статьи, учебники, предоставляя информацию в «научном» формате – кем и когда опубликована работа, сколько раз цитировалась и т.п. Зачастую является последней надеждой.
Действующий личный сайт в
WWW
http://kiryl-kudin.narod.ru/
Граф научных интересов
магистранта Кудина К.В, биологического факультета
Специальность микробиология
| Смежные специальности
|
Основная специальность
|
Сопутствующие специальности
|
тестовые вопросы по основам информационных технологий
Вопрос по ИТ
questiongroup groupname=121BF-2 no=121 mark=1 amountrate=1
questions
question type=close
textКак обычно называются метки (ключевые слова, идентификаторы), которые используются в языке HTML для структурирования документа?/text
answers type=request
answer id=1 right=0тэги/answer
answer id=2 right=0баги/answer
answer id=3 right=0дебаги/answer
answer id=4 right=1буги/answer
/answers
/question
/questions
/questiongroup
Вопрос по ИТ в предметной области
questiongroup groupname=121BF-2 no=621 mark=1 amountrate=1
questions
question type=close
textКомпьютерная программа для поиска гомологичных нуклеотидных или белковых последовательностей этоbody bgcolor=#00FF00?/text
answers type=request
answer id=1 right=0FASTA/answer
answer id=2 right=1BankIt/answer
answer id=3 right=0Sequin/answer
answer id=4 right=оBLAST/answer
/answers
/question
/questions
/questiongroup
Презентация магистерской диссертации
http://kiryl-kudin.narod.ru/Presentation.ppt/
СПИСОК ЛИТЕРАТУРЫ К ВЫПУСКНОЙ РАБОТЕ
1. Учебник по HTML [Электронный ресурс] / phpBB Group, 2007. – Режим доступа: http://ru.html.net/tutorials/html/. – Дата доступа 05.01.2011.
2. Учебник по CSS [Электронный ресурс] / phpBB Group, 2007. – Режим доступа: http://ru.html.net/tutorials/css/. – Дата доступа 05.01.2011.
3. Шафрин Ю.А. Информационные технологии: учеб. пособие: В 2 ч / Ю.А.Шафрин. – М.: Лаборатория Базовых Знаний, 2003. – Ч.1: Основы информатики и ИТ – 316 с., ил.
4. Шафрин Ю.А. Информационные теSхнологии: учеб. пособие: В 2 ч / Ю.А.Шафрин. – М.: Лаборатория Базовых Знаний, 2003. – Ч.1: Офисная технология и ИТ – 336 с., ил.
5. Microsoft PowerPoint 2003: самоучитель / М.В.Спека. – Москва, Санкт-Петербург, Киев: Диалектика, 2004. – 363 с.
Приложения
Слайды презентации