Хранилища данных и OLAP-средства
СОДЕРЖАНИЕ: Вечное хранение данных. Сущность и значение средства OLAP (On-line Analytical Processing). Базы и хранилища данных, их характеристика. Структура, архитектура хранения данных, их поставщики. Несколько советов по повышению производительности OLAP-кубов.СОДЕРЖАНИЕ
Введение
1 Вечное хранение данных
2 Важная терминология
3 Базы и хранилища данных
4 Неизменный спутник хранилищ данных
5 Некоторые аспекты хранения данных
5.1 Структуры хранения данных
5.2 Поставщики
6 Несколько советов по повышению производительности OLAP-кубов
Вывод
Литература
Введение
Тема контрольной работы «Хранилища данных и OLAP- средства».
Сегодня во многих организациях проблема использования большого объема собранных за многие годы данных ощущается все острее. В течение многих лет на предприятиях накапливаются и хранятся огромнейшие массивы информации, но при этом ее большая часть не может быть использована аналитиками и руководителями. Чаще всего эта информация доступна лишь тем подразделениям, в которых она накапливается. Поэтому и возникает потребность в системах, позволяющих получать необходимую «аналитику». Хотя в современных бизнес-приложениях все больше и больше появляется средств для аналитического анализа информации, тем не менее, достаточно много «аналитики» скрыто в данных предшествующих периодов деятельности, когда на предприятиях еще не было современных информационных систем.
1 Вечное хранение данных
Кроме оперативных баз данных (БД), источником информации в хранилищах данных (ХД) являются текстовые файлы. «Очищенные» данные, попадающие в ХД, не используются напрямую системами представления и анализа. Для этих целей используются витрины данных, позволяющих пользователям работать только с теми данными, которые им нужны. При этом повышается безопасность доступа к данным, а их структура отражает требования пользователя и снижается нагрузка на основное ХД.
Предметная ориентация - ключевое отличие оперативных БД от ХД. Разные приложения БД могут описывать одну и ту же предметную область с разных точек зрения и решение, принятое на основе данных, отражающих только одну сторону вопроса, могут быть неэффективными, а порой и просто неверными.
В оперативных БД информация может добавляться, удаляться и изменяться, а в ХД данные могут только загружаться и читаться. При этом все данные в ХД данных делятся на три основных категории:
2 Важная терминология
Хранилище данных( Data Warehouse ). Предметно-ориентированный, интегрированный, неизменяемый, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений (по определению основателя хранилищ данных Б. Инмона). Более просто: это база данных, хранящая данные, агрегированные по многим измерениям.
Витрина (или киоск) данных ( Data Mart ). Небольшое хранилище, а конечные пользователи могут создавать собственные структуры данных в нем.
Информационная система руководителя (ИСР) ( Executive Information System ([ EIS )). Приложения, созданные для использования руководителями.
Средства OLAP ( On - line Analytical Processing ). Инструментарий навигации по многомерным данным.
MOLAP ( Multidimensional OLAP ). Детальные данные и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
ROLAP( Relational OLAP ). Детальные данные остаются на своем месте (в реляционной БД), агрегаты хранятся в той же БД в специально созданных служебных таблицах.
HOLAP( Hybrid OLAP ). Детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Оперативные БД. Этот термин обозначает традиционные БД и введен для того, чтобы подчеркнуть их существенное отличие от БД, используемых для реализации ХД.
Средства анализа.Приложения для конечного пользователя, включая средства принятия решений, средства OLAP и другие специализированные средства анализа, прогноза и представления данных.
3 Базы и хранилища данных
Ни для кого не секрет, что одним из основных факторов успеха в бизнесе и управлении является скорость и качество принимаемых решений. А вот в основе этих решений лежит имеющаяся информация. В эпоху глобальной компьютеризации информация получается из данных, которые хранятся в электронном виде в файлах различных форматов. Для эффективного хранения данных сегодня используются базы данных (БД), а точнее СУБД - системы управления базами данных. В составе любой базы данных имеются таблицы, между полями которой существуют связи (реляции, отношения). Отсюда и название «реляционные БД». Именно с их помощью можно структурировать информацию и обеспечивать быстрый и удобный доступ к ней.
Исходя из этого, до недавнего времени предприниматель, руководитель предприятия или любой другой человек, принимающий ответственные решения, получал сведения, не всегда удовлетворявшие его требования.
Во-первых, большая часть информации стандартизована и представляется в стандартных формах отчетности. Во-вторых, эта информация имеет разную степень детализации: от подробных сведений, например, о ежедневных продажах, до сводных квартальных отчетов. В-третьих, все данные поставляются по фиксированным датам: в конце дня, месяца, квартала, года. Но самое неприятное заключается в том, что такая регламентированность работы с информацией не позволяет обеспечить своевременное принятие нестандартных решений.
Несомненно, базы данных - это незаменимый источник информации. Кроме того, они используются как в локальных финансово-учетных системах, так и MRP- и ERP-системах. Но ведь обычная БД обслуживает не только руководителей, принимающих решения, но и других пользователей непосредственно работающих с данными, что сказывается на скорости обработки информационных потоков.
Частота запросов к БД связана с детализацией требуемых данных: для ускорения доступа к данным нужна отдельная БД, работающая только в режиме чтения и хранящая агрегированные (интегрированные) данные. Кроме того, сложные аналитические запросы к оперативной информации тормозят текущую работу информационной системы предприятия, блокируя таблицы БД и захватывая ресурсы сервера.
Вот поэтому все чаще взоры экспертов и аналитиков обращены к хранилищам данных (ХД) - оптимально организованной БД, хранящей данные, агрегированные по многим измерениям, и обеспечивающей максимально быстрый доступ к информации, необходимой для принятия управленческих решений. Данные в ХД попадают из оперативных БД и систем, которые предназначены для автоматизации бизнес-процессов. Кроме того, ХД может пополняться из внешних источников, например, статистических отчетов. Резонный вопрос: чем ХД лучше БД? Ведь они содержат заведомо избыточную информацию, которая хранится в БД или файлах оперативных систем? Анализировать данные оперативных систем непосредственно невозможно или, по крайней мере, весьма затруднительно, так как данные хранятся в форматах различных СУБД и на разных носителях в корпоративной сети.
Пополнение ХД происходит периодически, при этом автоматически формируются новые агрегаты данных, зависящие от старых, т. е. в одном месте и в простой структуре хранится «сырье» для анализа (рис. 1).
Если до недавнего времени для анализа имеющихся данных применялась схема: БД - Средство анализа,то в быстро развивающаяся концепция хранилищ данных (ХД) предлагает изменить эту схему: БД - объекты ХД - Средство анализа.Это и есть суть информационная система нового поколения.
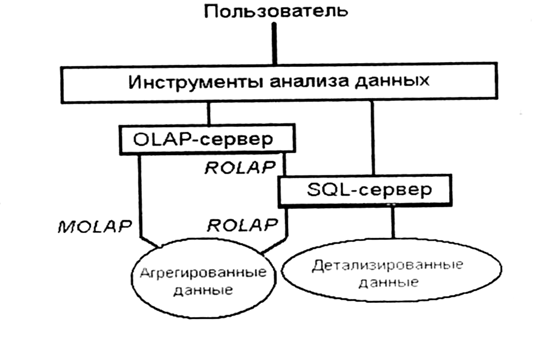 |
Рис. 1. Архитектура интеллектуального извлечения данных из ХД
4 Неизменный спутник хранилищ данных
Централизация и удобное структурирование данных - это далеко не все, что нужно аналитику. Традиционные отчеты, даже построенные на основе единого хранилища, лишены гибкости. Они не позволяют
получать множество срезов и разрезов данных. Чем больше срезов и разрезов видит аналитик, тем больше у него идей. Для этих целей используется такой инструмент, как OLAP.
Не вдаваясь в сложную теорию определяющих принципов OLAP, сформулированных Е. Коддом - «изобретателем» реляционных БД, приведем следующее определение OLAP: Быстрый Анализ Разделяемой Многомерной Информации - FASMI (FastAnalysisofSharedMultidimensionalInformation). Fast означает, что система должна обеспечивать выдачу большинства ответов пользователям в пределах 5 секунд. Analysis означает, что система может справляться с любым логическим и статистическим анализом. Shared означает, что система осуществляет все требования конфиденциальности (возможно до уровня записи), а при доступе нескольких пользователей обеспечивает блокировку изменений на соответствующем уровне. Multidimensional - система должна обеспечить многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий данных. И, наконец, Information - это все, с чем мы работаем каждый день и пытаемся на ее основе получить прогнозируемые результаты.
OLAP предоставляет пользователю быстродействующие средства доступа, просмотра и анализа бизнес-информации. Пользователь получает интуитивно понятную модель данных, организуя их в виде многомерных кубов. Оси многомерной системы координат - основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, населенный пункт, категория покупателей. В качестве одного из измерений используется время. На пересечениях осей-измерений находятся данные, количественно характеризующие процесс-меры. Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе и т. п. Пользователь, анализирующий информацию, может «разрезать» куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции.
5 Некоторые аспекты хранения данных
5.1 Структуры хранения данных
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Дело в том, что в любом ХД наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные (агрегированные) показатели (агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде, чтобы ускорить выполнение запросов, так как аналитиков в большинстве случаев интересуют не детальные, а обобщенные данные. К тому, если каждый раз для вычисления суммы продаж за год пришлось бы суммировать десятки и сотни тысяч продаж, то скорость была бы абсолютно неприемлемой. Хотя при этом за скорость приходится «расплачиваться» объемом данных.
Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления агрегатов и различные многомерные преобразования по любому из измерений.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то большая часть куба будет пустовать, хотя место будет занято.
5.2 Поставщики
Прежде всего отметим принципиальные отличия OLAP-систем. Это программное обеспечение, предоставляющее пользователю возможность в режиме реального времени получать ответы на произвольные аналитические запросы. К классу OLAP-систем относят только те программы, которые в качестве внешнего интерфейса предоставляют пользователю многомерную изменяемую таблицу. Эта таблица позволяет пользователю менять местами столбцы и строки, задавать условия фильтрации и при этом она автоматически вычисляет промежуточные итоги в группах данных и окончательные итоги. Неотъемлемой частью OLAP-анализа является графическое отображение данных.
Программная реализация OLAP-решения предполагает наличие машины вычислений (OLAP-сервера) и многомерной базы данных (MO-LAP), к которой обращаются клиентские программы с запросами на получение данных и выполнение вычислений. Любое конечное решение содержит OLAP-компоненту, которая является интерфейсом пользователя. Эти компоненты похожи друг на друга. Их визуальная часть состоит из элементов управления и элементов отображения данных.
Среди поставщиков этого класса программного обеспечения - прежде всего, известные поставщики серверов баз данных. К их числу относятся Oracle (со своим OLAP-продуктом Express ), IBM(DB2 OLAPServer), Microsoft(OLAPServices), Informix(MetaCube).
Кроме того, достаточно интересны и решения известных игроков смежных рынков - SASInstitute(MDDBи CFOCFOVision), SAP(BW), HyperionSolutions(Essbase), CA(InfoBeacon).
Еще недавно поставщики OLAP-серверов продавали свои продукты по очень высоким ценам. Например, приобретение OracleExpress обошлось бы в $95000 за рабочие места двух аналитиков и двух администраторов. Поэтому многие управленцы для решения таких аналитических задач использовали всем известное приложение Excel из состава офисного пакета от Microsoft. Хотя эта популярная программа годится только для одного пользователя, тем не менее, при правильной организации работы и интеграции с внешними приложениями можно достичь хороших результатов в получении «аналитики». По сути, появление OLAP-функциональности ознаменовало появление особого класса продуктов - настольных OLAP (DOLAP - DesktopOLAP).
По способу получения данных такие программы можно разделить на локальные и корпоративные:
- локальные манипулируют данными таблиц MSExcel или настольных СУБД, например Access, Paradox;
- корпоративные DOLAP имеют доступ к SQL-серверам или многомерным базам данных и, в свою очередь тоже делятся на две категории.
DOLAP-программы поставляются самими разработчиками баз данных, многомерных и реляционных. ЭтоSAS Corporate Reporter, Oracle Discovery,комплекспрограммMS Pivot ServicesиPivot Tableидругие. Имеются и разработки российских компаний, например Контур Стандарт от IntersoftLab или разработка компании ПиБи - OLAP 7.7 - инструмент оперативного анализа данных для семейства программ 1С:Предприятие 7.7. Так, применение OLAP 7.7 позволяет выявлять наилучших или наихудших поставщиков и покупателей, определять закономерности объемов продаж по периодам и регионам, применять его для выявления «узких» мест ведения бизнеса и учитывать это при принятии управленческих решений.
Достаточно интересные продукты предлагает компания IntersoftLab (www.iso.ru).
Продукты Контурпредставлены:
- Платформой Хранилищ данных (ContourDataWarehousePlatform), предназначенной для создания единого информационного пространства и поддержки корпоративного управления;
- Аналитической платформой (ContourAnalysisPlatform), предназначенной для бизнес-анализа и публикации данных.
Также необходимо упомянуть и о пакете Deductor (www.basegr-oup.ru), который обеспечивает моделирование, прогнозирование, поиск закономерностей и другие технологии обнаружения знаний (KnowledgeDiscoveryinDatabases) и добычи данных (DataMining). В его состав входят:
- Cube Analyzer - настольный OLAP-модуль, реализующий технологию многомерного анализа в простой и удобной форме;
- RawData Analyzer - система, ориентированная на предварительную обработку данных для последующего их анализа. Технологии, реализованные в RawDataAnalyzer, позволяют провести весь комплекс действий - сглаживание, очистка от шумов, редактирование аномальных значений, заполнение пропусков, устранение незначащих факторов, понижение размерности;
- Tree Analyzer - программа, позволяющая проводить анализ данных на основе деревьев решений;
- SOMap Analyzer - программа, позволяющая проводить анализ данных на основе самоорганизующихся карт Кохонена;
- Neural Analyzer - программа, реализующая многослойные нейронные и RBF-сети. При помощи них решаются задачи прогнозирования, моделирования и управления динамическими системами.
6 Несколько советов по повышению производительности OLAP -кубов
1.Для достижения максимальной производительности следует правильно выбрать режим хранения - MOLAP, HOLAP, или ROLAP. Производительность при использовании MOLAP или HOLAP примерно одинакова, а применение ROLAP в любом случае ее понизит. MOLAP требует больших объемов дискового пространства, чем HOLAP и ROLAP, хотя для HOLAP необходимо меньше оперативной памяти.
2. Выбирая уровень агрегирования для кубов, не рекомендуется выходить за интервал от 25 % до 60 %. Уровни агрегирования выше 60 %, как правило, требуют огромных объемов дискового пространства и в большинстве случаев не приводят к существенному увеличению скорости обработки запросов.
3. Для достижения наивысшей производительности SQL-сервер с хранилищем или витриной данных и OLAP-сервер должны быть на разных компьютерах.
4. Если OLAP-кубы очень большие по размеру или часто используются, то их желательно разместить их на отдельных серверах, тем самым распределив нагрузку. Для наиболее часто используемого куба можно создать его копии на нескольких серверах.
5. Обновление информации в кубах желательно выполнять в периоды наименьшей загрузки сервера.
6. По умолчанию объем памяти, используемый OLAP-сервером, равен половине объема оперативной памяти сервера. Если сервер используется для обработки одного из нескольких кубов, то значение минимально доступной памяти должно составлять 90% памяти сервера.
7. Помните, что максимальное количество обрабатываемых OLAPService нитей (процессов) равно 1000. Исходя из этого, с помощью монитора производительности можно определить нагрузку процессоров.
8. Проводите качественные анализ и проектирование систем. Это позволит при разработке OLAP-кубов не включать в них меры или измерения, которые не будут использоваться.
9. При создании OLAP-куб, используйте мастер анализа, чтобы проанализировать обрабатываемые запросы, и мастер оптимизации, чтобы повысить производительность.
10. В случае корпоративной версии SQL-сервера для повышения производительности OLAP-кубы можно поделить на партиции (отдельно управляемые элементы хранения). Каждая партиция может иметь свой режим хранения данных и уровень агрегирования. Использование партиций позволяет размещать их на разных дисках и повысить интенсивность их использования.
11. Чтобы уменьшить время обработки куба, необходимо отключить опцию оптимизации схемы, тем самым уменьшив количество ненужных связей и значительно снизив время обработки куба.
Вывод
В процессе выполнения контрольной работы мы ознакомились с важной терминологией вечного хранения данных и понятием данного термина, с базой данных и хранилищами данных, с простейшими аспектами хранения данных и структурой хранения данных, а так же привели несколько советов относительно повышения производительности OLAP-кубов и др.
Литература
1. Антонов А.В. Системный анализ. Методология. Построение модели: Учеб. пособие. — Обникс: ИАТЭ, 2001. — 272 с.
2. Богданов А.А. Тетология: В 3 т. — М., 1905—1924.
3. Венда В.Ф. Системы гибридного интеллекта: эволюция, психология, информатика. — М.: Машиностроение, 1990. — 448 с.
4. Волова В.Н. Основы теории систем и системного анализа/В.Н. Волова, А.А. Денисов. — СПб.: СПбГТУ, 1997. — 510 с.
5. Волова В.Н. Методы формализованного представления систем/ В.Н. Волова, А.А. Денисов, Ф.Е. Темнигов. — СПб.:СПбГТУ, 1993. — 108 с.
6. Гасаров Д.В. Интеллетальные информационные системы. —М.: Высш. ш., 2003. — 431 с.
7. Гелшов В.М. Введение в АСУ. — Киев: Техника, 1974.
8. Дегтярев Ю.И. Системный анализ и исследования операций. — М.: Высш. ш., 1996. — 335 с.
9. Корячов В.П. Теоретичесие основы САПР: Учеб. для взов/В.П. Корячо, В.М. Крейчи, И.П. Норенов. — М.: Энергоатомиздат, 1987. — 400 с.
10. Мамионов А.Г. Основы построения АСУ: Учеб. для взов. — М.: Высш. ш., 1981. — 248 с.
11. Меньов А.В. Теоретичесие основы автоматизированного управления: Учеб. пособие. — М.: МГУП, 2002. — 176 с.
12. Острейовский В.А. Автоматизированные информационные системы в экономике: Учеб. пособие. — Ср т: СрГУ, 2000. — 165 с.
13. Острейовский В.А. Современные информационные технологии экономистам: Учеб. пособие. Ч. 1. Введение в автоматизированные информационные технологии. — Ср т:СрГУ, 2000. — 72 с.
14. Автоматизированные информационные технологии в экономике/Под ред. проф. Г.А. Титоренко. — М.: Компьютер, ЮНИТИ, 1998.— 400 с.
15. Автоматизированные информационные технологии в банковской деятельности / Под ред. проф. Г.А. Титоренко. — М.: Финстатинформ, 1997.
16. АСУ на промышленном предприятии: Методы создания: Справочник / С.Б. Михалев, Р.С. Седенов, А.С. Гринбер и др. — М.: Энергоатомиздат, 1989. — 400 с.