Корреляционный анализ для ранговых шкал
СОДЕРЖАНИЕ: Реальным содержанием измерений в ранговых шкалах является тот порядок, в котором выстраиваются объекты по степени выраженности измеряемого признака..
С.В. Усатиков, кандидат физ-мат наук, доцент; С.П. Грушевский, кандидат физ-мат наук, доцент; М.М. Кириченко, кандидат социологических наук
Продолжаем исследовать объекты, обладающие двумя и более признаками, и уже выяснили, что гипотезу о их независимости можно смело отбросить. Как же теперь предсказывать значение одного признака по значению другого? Насколько вообще сильна эта зависимость?
Для изучения способностей человека к умственной или физической деятельности нередко прибегают к специально организованным пробам и тестам. Результатом такого теста является число, называемое тестовым баллом. При замене теста другим подобным тестовые баллы испытуемого изменяются, но ведь объект измерения тот же, что и прежде. Следовательно, для этих чисел имеют смысл только понятия “больше” или “меньше”. Для тестовых баллов, как и для школьных оценок, допустимы только их сравнения. Операции вроде сложения или вычитания для этих шкал не имеют смысла, поскольку нет единицы измерения. Например, нельзя сказать, что получивший оценку 4 знает предмет на 1 балл лучше, чем получивший 3. Ясно только, что получивший 4 знает этот предмет лучше, чем тречник.
Итак, реальным содержанием измерений в ранговых шкалах является тот порядок, в котором выстраиваются объекты по степени выраженности измеряемого признака. Например, для изучения двигательных возможностей группы детей мы предложили каждому ребенку сложить что-то определенное из кубиков и палочек. Ясно, что время, затраченное на выполнение задания, тем больше, чем менее развиты способности к тонким движениям рук и пальцев. Поэтому упорядочение испытуемых по затраченному времени совпадает с их упорядочением по развитию этих способностей. При другом подобном задании затраченное время будет другим, но порядок сохранится (конечно, с учетом влияния случайных обстоятельств).
Первым решение подобных проблем предложил психолог Ч.Спирмен в 1900 году, обсуждавший, например, связь между способностями к музыке и математике.
Пусть проведено n испытаний с изменениями двух признаков и получено n пар чисел (Xi,Yi), где1Ј iЈ n. Упорядочим эти пары по возрастанию чисел Xi и их порядковый номер j (1Ј jЈ n) назовем рангом чисел Xi. Если несколько чисел совпадают по величине, то каждому из них присваивается ранг, равный среднему арифметическому их номеров. Порядок чисел Yi также, естественно, изменится. Если отдельно упорядочить числа yi по возрастанию, то их порядковый номер r тоже становится рангом чисел Yi. Но поскольку эти числа имеют смысл только в паре между собой, ранги r чисел Yi перемещаются и получается пар n чисел рангов (j, rj), где 1Ј jЈ n.
Если признаки взаимосвязаны, то возрастание j влияет на порядок, в котором следуют ранги rj : например, они чаще возрастают, чем убывают, либо наоборот. Еще два случая однозначной зависимости признаков: с возрастанием j ранги rj либо только возрастают, либо только убывают. В этом случае число
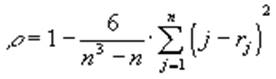
называемое коэффициентом ранговой корреляции Спирмена, равно либо 1 либо -1. Во всех остальных случаях величина r может колебаться от +1 до -1 и в случае независимости признаков (т.е. полного “хаоса” среди рангов rj) r =0. Если число r отрицательное, то говорят об отрицательной корреляции, т.е. при возрастании одного признака второй в основном убывает. Если число r положительное , то говорят о положительной корреляции, т.е. при возрастании одного признака второй в основном тоже возрастает. Величина жеЅ r Ѕ Ј 1 показывает в долях меру зависимости признаков. ЕслиЅ r Ѕ близка к 1, говорят о сильной корреляции, т.е. зависимость признаков почти однозначная и случайные отклонения редки. Если Ѕ r Ѕ близка к 0, то говорят о слабой корреляции, т.е. при возрастании одного признака рост или уменьшение другого почти совсем хаотичны и непредсказуемы.
В заключении вернемся к вопросу о значимости вычисленного коэффициента r , т.е. к проверке гипотезы о независимости признаков. В данном случае это можно сделать проще. А именно, число
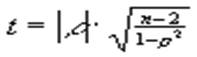
подчиняется t- закону Стьюдента с n =n -2 степенями свободы. Поэтому если, например, уровень значимости a =0,2 (или 20%), то заведомо tЈ 3 при верной нулевой гипотезе. Следовательно, если t3, то гипотезу о независимости можно отбросить и считать величину r значимой.
При других уровнях значимости a и числе степеней свободы n необходимо брать критическое значение t из таблицы распределения Стьюдента в статистических справочниках или учебниках.
Коэффициент Спирмена относится к числу достаточно распространенных измерительных процедур. Одна из причин этой популярности - его “всеядность” - он может быть использован для анализа шкал всех типов (считается, вообще-то, что он предназначен только для шкал ранговых, но и номинальную шкалу можно рассмотреть как ранговую, если рангом считать % ответов по каждой позиции вопроса с номинальной шкалой). С другой стороны, этот достаточно простой коэффициент эффективен для такой, часто весьма необходимой в исследовании, процедуры, как установление степени гомогенности группы. Например, в анкете используются вопросы, касающиеся системы ценностей и жизненных планов выпускников. Позиции вопроса (получение высшего образования, решение жилищного вопроса, удачный брак и дети и т.д. и т.п.) можно проранжировать по степени значимости для всей выпускной группы. Но этот ранговый ряд будет усреднением суммы всех индивидуальных оценок, его составляющих. Поэтому как контрольный прием может быть использована попарное сравнение всех ранговых рядов. Каждая подгруппа выборки принимается за 100%, и в них устанавливаются ранги произведенных оценок. Затем попарно рассчитываются значения r . Недостатком этого приема является то обстоятельство, что использование более чем 10 групп затруднительно - число необходимых парныхъ расчетов переваливает за четыре десятка. Рассмотрим эту процедуру на конкретном примере. В ходе исследования (10-11.1995) политических установок и избирательской активности населения Кубани в анкете применялся вопрос: “Изменилась ли Ваша материальное положение за первую половину 1995 года?”
| Ответы | % | Ранги |
| 1. Значительно улучшилось | 2,8 | 5 |
| 2. Несколько улучшилось | 8,8 | 4 |
| 3. Осталось без изменений | 27,4 | 2 |
| 4. Несколько ухудшилось | 25,4 | 3 |
| 5. Значительно ухудшилось | 35,5 | 1 |
Однако при выделении основных, по роду занятий подгрупп, картина стала уже более пестрой (р - ранг)
| Рабочие | Крес- тьяне | ИТР, служащие | Пред- прини-матели | Пенсионе-ры | Все-го | |||||||||
| % | р | % | р | % | р | % | р | % | р | |||||
| Значительно улучшилось | 3,8 | 5 | 0 | 5 | 3,0 | 5 | 0 | 4,5 | 4 | 5 | 5 | |||
| Несколько улучшилось | 9,6 | 4 | 10,7 | 4 | 4,5 | 4 | 60 | 1 | 8 | 4 | 4 | |||
| Осталось без изменений | 25 | 3 | 32,1 | 1,5 | 27,8 | 2 | 30 | 2 | 24 | 2,5 | 2 | |||
| Несколько ухудшилось | 30,8 | 1,5 | 32,1 | 1,5 | 24,1 | 3 | 0 | 4,5 | 24 | 2,5 | 3 | |||
| Значительно ухудшилось | 30,8 | 1,5 | 25 | 3 | 40,6 | 1 | 10 | 3 | 40 | 1 | 1 | |||
Затем по приведенной выше формуле производятся расчеты. Для групп рабочих и крестьян это будет выглядеть следующим образом:![]()
Произведя все необходимые вычисления (в данном примере их должно быть 10), можно построить диагональную матрицу связи:
| Рабочие | Крестьяне | ИТР, служащие | Предпри- ниматели |
Пенсионе-ры | |
| Рабочие | * | 0,775 | 0,875 | -0,075 | 0,925 |
| Крестьяне | * | 0,675 | 0,575 | 0,700 | |
| ИТР, служащие | * | 0,275 | 0,975 | ||
Предпри ниматели |
* | 0,125 | |||
| Пенсионеры | * |
Для простоты она переформировывается в таблицу степени совпадения r .
| Рабочие | Крестьяне | ИТР, служащие | Предпри- ниматели |
Пенсионеры | |
| Рабочие | * | 4 | 3 | 10 | 2 |
| Крестьяне | * | 6 | 7 | 5 | |
| ИТР, служащие | * | 8 | 1 | ||
Предпри ниматели |
* | 9 | |||
| Пенсионеры | * |
Уже на основании этих таблиц можно делать, исходя из различий в проиведенных оценках, какие-либо выводы относительно социально-психологических установыок групп и причин, их определяющих.
Необходимо каснуться некоторых недостатков r , так как на ряде процедур анализа этот коэффициент может ”не срабатывать” или исказить результаты. Во-первых, это дефект присущий всем ранговым (в отличии от интервальных) шкалам. Ранги устанавливаются по убыванию / возрвстанию незвасимо от степени разрыва между двумя позициями. В принципе возможен вариант, когда r зафиксирует полную идентичность (r = +1) двух сильно различающихся рядов, например, таких:
| Группа 1 | Группа 2 | |||
| % ответов | ранг | % ответов | ранг | |
| Позиция 1 | 80 | 1 | 20 | 1 |
| Позиция 2 | 10 | 2 | 19 | 2 |
| Позиция 3 | 4 | 3 | 17 | 3 |
| Позиция 4 | 3 | 4 | 16 | 4 |
| Позиция 5 | 2 | 5 | 15 | 5 |
| Позиция 6 | 1 | 6 | 13 | 6 |
Кроме того, характер парных корреляций не учитывает размера группы. Если Ваши расчеты не автоматизированы, а в программу ЭВМ не заложено ограничение на численность группы, то “умная” машина может абсурдно проранжировать группу из одного человека, присвоив отмеченной одиночной позиции ранг №1, а всем остальным - срединный (для примера табл. 5 это был бы номер 4- срединный между второй и шестой позициями).
Однако, прежде чем делать выводы относительно тесноты парных связей подгрупп (и гомогенности группы в целом), необходима проверка значимости коэффициента, установления того “порогового барьера” a , за которым мы можем говорить о наличии занчимой корреляции. По приведенной выше формуле расчета t находим, что для групп предпринимателей и пенсионеров (r =0,125), значение t равно:
![]() = 0,216
= 0,216
что в несколько раз меньше критического (2,353 для a =0,1 и 1,638 для a =0,2). В такой ситуации остается лишь признать связь рядов статистически малозначимой и сильно завысить степень возможной ошибки при повторных замерах (a =0,4-0,5).
В заключение остановимся еще на одном коэффециенте ранговой корреляции, не менее употребимом, чем r . Это множественный коэффициент корреляции W, или, как его еще часто называют, коэффициент конкордации. Предназначаемый, как и r , для измерения степени связи ранжированных переменных, он основывается на несколько иной логике анализа. Если коэффициент Спирмена предназначается для анализа степени совпадения/расхождения отдельных групп, составояющих выборочную совокупность, то для коэффициента W объектом оценивания является, как правило, согласованность мнений всей выборочной совокупности. В первом случае употребляется индуктивный метод анализа - от частных фактов (отдельные подгруппы) к общему умозаключяению (степень гомогенности выборочной совокупности). Коэффициент W используется тогда, когда задачи, гипотезы исследования требуют обратного дедуктивного движения. Например, по 5-7 вопросам анкеты расчитывается коэффициент W. Наименьшие значения W свидетельствуют о максимуме расхождения мнения в подгруппах; спускаясь от общего к частному, исследователь выделяет те подгруппы, которые внесли наибольший диссонанс в общую картину и выдвигает гипотезы относительно причин данной ситуации.
Коэффициент W, подобно r , принимает значения от -1 до +1 и рассчитывается по формуле:
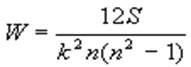
где k - число переменных, n- число ранжируемых позиций,
S- сумма сумм рангов по строке минус среднее, возведенных в квадрат.
Рассмотрим применение W на том- же примере, что и r :
Среднее из суммы рангов равно 75 : 5 = 15. Значение S соответственно будет равно
![]() . Отсюда
. Отсюда
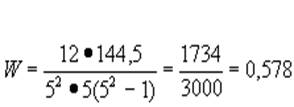
| Рабочие | Крестья не | ИТР, слу жащие | Предпри нимате-ли | Пенсио-неры | Сумма рангов по строке | |
| Значительно улучшилось | 5 | 5 | 5 | 4,5 | 5 | 24,5 |
| Несколько улучшилось | 4 | 4 | 4 | 1 | 4 | 17 |
| Осталось без изменений | 3 | 1,5 | 2 | 2 | 2,5 | 11 |
| Несколько ухудшилось | 1,5 | 1,5 | 3 | 4,5 | 2,5 | 13 |
| Значительно ухудшилось | 1,5 | 3 | 1 | 3 | 1 | 9,5 |
| n = 5 | Итого: | 75 |
Значимость полученного значения W проверяется по критерию c 2
c 2=![]() ,
,
со степенью свободы n-1, что для нашего случая даст величину c 2=11,56. Для уровня доверительной вероятности a = 0.05 критическое значение c 2=9,488, при a = 0.02 c 2= 11,668. Наблюдаемое значение(11,56) превышает пятипроцентный уровень, но не укладывается в пределы a = 0.02. Поэтому утверждение о наличии существенной связи между переменныи мы можем принять в интервале 0.05 a 0.02, т.е. с вероятностью » 96-97%.