Критерии согласия
СОДЕРЖАНИЕ: Суть понятия критерии согласия. Критерии согласия Колмогорова и омега-квадрат в случае простой гипотезы. Критерии согласия Пирсона для простой гипотезы, Фишера для сложной гипотезы. Теоретическое обоснование и практическое применение критерия согласия.МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
АЗОВСКИЙ РЕГИОНАЛЬНЫЙ ИНСТИТУТ УПРАВЛЕНИЯ
ЗАПОРОЖСКОГО НАЦИОНАЛЬНОГО ТЕХНИЧЕСКОГО УНИВЕРСИТЕТА
Кафедра математики
КУРСОВАЯ РАБОТА
З дисциплины «СТАТИСТИКА»
На тему: «КРИТЕРИИ СОГЛАСИЯ»
студентки 2-го курса
группы 207 факультета управления
Батуры Татьяны Олеговны
Научный руководитель
доцент Косенков О. И.
Бердянск – 2009г.
Содержание
ВВЕДЕНИЕ
РАЗДЕЛ I. ТЕОРЕТИЧЕСКОЕ ОБОСНОВАНИЕ КРИТЕРИЯ СОГЛАСИЯ
1.1 Критерии согласия Колмогорова и омега-квадрат в случае простой гипотезы
1.2 Критерии согласия 2 Пирсона для простой гипотезы
1.3 Критерии согласия для сложной гипотезы
1.4 Критерии согласия 2 Фишера для сложной гипотезы
1.5 Другие критерии согласия. Критерии согласия для распределения Пуассона
РАЗДЕЛ II. ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ КРИТЕРИЯ СОГЛАСИЯ
ВЫВОД
ПРИЛОЖЕНИЯ
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
ВВЕДЕНИЕ
В данной курсовой работе рассказано о наиболее распространенных критериях согласия – омега-квадрат, хи-квадрат, Колмогорова и Колмогорова-Смирнова. Особенное внимание уделено случаю, когда необходимо проверить принадлежность распределения данных некоторому параметрическому семейству, например, нормальному. Эта весьма распространенная на практике ситуация из-за своей сложности исследована не до конца и не полностью отражена в учебной и справочной литературе.
Критериями согласия называют статистические критерии, предназначенные для проверки согласия опытных данных и теоретической модели. Лучше всего этот вопрос разработан, если наблюдения представляют случайную выборку. Теоретическая модель в этом случае описывает закон распределения.
Теоретическое распределение – это то распределение вероятностей, которое управляет случайным выбором. Представления о нем может дать не только теория. Источниками знаний здесь могут быть и традиция, и прошлый опыт, и предыдущие наблюдения. Надо лишь подчеркнуть, что это распределение должно быть выбрано независимо от тех данных, по которым мы собираемся его проверять. Иначе говоря, недопустимо сначала «подогнать» по выборке некоторый закон распределения, а потом пытаться проверить согласие с полученным законом по этой же выборке.
Простые и сложные гипотезы. Говоря о теоретическом законе распределения, которому гипотетически должны бы следовать элементы данной выборки, надо различать простые и сложные гипотезы об этом законе:
· простая гипотеза прямо указывает некий определенный закон вероятностей (распределение вероятностей), по которому возникли выборочные значения;
· сложная гипотеза указывает на единственное распределение, а какое-то их множество (например, параметрическое семейство).
Критерии согласия основаны на использовании различных мер расстояний между анализируемым эмпирическим распределением и функцией распределения признака в генеральной совокупности.
Непараметрические критерии согласия Колмогорова, Смирнова, омега квадрат широко используются. Однако с ними связаны и широко распространенные ошибки в применении статистических методов.
Дело в том, что перечисленные критерии были разработаны для проверки согласия с полностью известным теоретическим распределением. Расчетные формулы, таблицы распределений и критических значений широко распространены. Основная идея критериев Колмогорова, омега квадрат и аналогичных им состоит в измерении расстояния между функцией эмпирического распределения и функцией теоретического распределения. Различаются эти критерии видом расстояний в пространстве функций распределения.
Приступая к выполнению данной курсовой работы, я поставила себе за цель, узнать какие существуют критерии согласия, разобраться для чего же они нужны. Для осуществления этой цели необходимо выполнить следующие задания:
1. Раскрыть суть понятия “критерии согласия”;
2. Определить какие критерии согласия существуют, изучить их по отдельности;
3. Сделать выводы по проведенной работе.
РАЗДЕЛ I. ТЕОРЕТИЧЕСКОЕ ОБОСНОВАНИЕ КРИТЕРИЯ СОГЛАСИЯ
1.1 Критерии согласия Колмогорова и омега-квадрат в случае простой гипотезы
Простая гипотеза. Рассмотрим ситуацию, когда измеряемые данные являются числами, иначе говоря, одномерными случайными величинами. Распределение одномерных случайных величин может быть полностью описано указанием их функций распределения. И многие критерии согласия основаны на проверке близости теоретической и эмпирической (выборочной) функций распределения.
Предположим, что имеем выборку n. Обозначим истинную функцию распределения, которой подчиняются наблюдения, G(х), эмпирическую (выборочную) функцию распределения – Fn (х), а гипотетическую функцию распределения – F(х). Тогда гипотеза Н о том, что истинная функция распределения есть F(х), записывается в виде Н : G(·) = F(·).
Как проверить гипотезу H? Если Н верна, то Fn и F должны проявлять определенное сходство, и различие между ними должно убывать с увеличением n. Вследствие теоремы Бернулли Fn (х) F(х) при n . Для количественного выражения сходства функций Fn иF используют различные способы.
Для выражения сходства функций можно использовать то или иное расстояние между этими функциями. Например, можно сравнить Fn и F в равномерной метрике, т.е. рассмотреть величину:
![]() (1.1)
(1.1)
Статистику Dn называют статистикой Колмогорова.
Очевидно, что Dn - случайная величина, поскольку ее значение зависит от случайного объекта Fn . Если гипотеза Н0 справедлива и n , то Fn (x) F(x) при всяком х. Поэтому естественно, что при этих условиях Dn 0. Если же гипотеза Н0 неверна, то Fn G и G F, а потому sup-x |Fn (x) - F(x)| supx |G(x) - F(x)|. Эта ппоследняя величина положительна, так как G не совпадает с F. Такое различие в поведении Dn в зависимости от того, верна Н0 или нет, позволяет использовать Dn как статистику для проверки Н0 .
Как всегда при проверке гипотезы, рассуждаем так, как если бы гипотеза была верна. Ясно, что Н0 должна быть отвергнута, если полученное в эксперименте значение статистики Dn кажется неправдоподобно большим. Но для этого надо знать, как распределена статистика Dn при гипотезе Н: F= G при заданных n и G.
Замечательное свойство Dn состоит в том, что если G = F, т.е. если гипотетическое распределение указано правильно, то закон распределения статистики Dn оказывается одним и тем же для всех непрерывных функций G. Он зависит только от объема выборки n.
Доказательство этого факта основано на том, что статистика не изменяет своего значения при монотонных преобразованиях оси х. Таким преобразованием любое непрерывное распределение G можно превратить в равномерное на отрезке [0, 1]. При этом Fn (x) перейдет в функцию распределения выборки из этого равномерного распределения.
При малых п для статистики Dn
при гипотезе Н0
составлены таблицы процентных точек. При больших п распределение Dn
(при гипотезе Н0
) указывает найденная в 1933 г. А.Н.Колмогоровым предельная теорема. Она говорит о статистике ![]() (поскольку сама величина Dn
0 при Н0
, приходится умножать ее на неограниченно растущую величину, чтобы распределение стабилизировалось). Теорема Колмогорова утверждает, что при справедливости Н0
и если G непрерывна:
(поскольку сама величина Dn
0 при Н0
, приходится умножать ее на неограниченно растущую величину, чтобы распределение стабилизировалось). Теорема Колмогорова утверждает, что при справедливости Н0
и если G непрерывна:
![]() (1.2)
(1.2)
Эта сумма очень легко считается в Maple. Для проверки простой гипотезы Н0 : G = F требуется по исходной выборке вычислить значение статистики Dn . Для этого годится простая формула:
![]() (1.3)
(1.3)
Здесь через хk - элементы вариационного ряда, построенного по исходной выборке. Полученную величину Dn затем надо сравнить с извлеченными из таблиц или рассчитанными по асимптотической формуле критическими значениями. Гипотезу Н0 приходится отвергать (на выбранном уровне значимости), если полученное в опыте значение Dn превосходит выбранное критическое значение, соответствующее принятому уровню значимости.
Другой популярный критерий согласия получим, измеряя расстояние между Fn и F в интегральной метрике. Он основан на так называемой статистике омега-квадрат:
![]() (1.4)
(1.4)
Для его вычисления по реальным данным можно использовать формулу:
![]() (1.5)
(1.5)
При справедливости гипотезы Н0 и непрерывности функции G распределение статистики омега-квадрат, так же, как распределение статистики Dn , зависит только от n и не зависит от G.
Так же, как для Dn
, для ![]() при малых n имеются таблицы процентных точек, а для больших значений n следует использовать предельное (при n ) распределение статистики n
при малых n имеются таблицы процентных точек, а для больших значений n следует использовать предельное (при n ) распределение статистики n![]() . Здесь снова приходится умножать на неограниченно растущий множитель. Предельное распределение было найдено Н.В.Смирновым в 1939 г. Для него составлены подробные таблицы и вычислительные программы. Важное с теоретической точки зрения свойство критериев, основанных на Dn
и
. Здесь снова приходится умножать на неограниченно растущий множитель. Предельное распределение было найдено Н.В.Смирновым в 1939 г. Для него составлены подробные таблицы и вычислительные программы. Важное с теоретической точки зрения свойство критериев, основанных на Dn
и ![]() : они состоятельны против любой альтернативы G F.
: они состоятельны против любой альтернативы G F.
Статистический критерий для проверки гипотезы Н называют состоятельным против альтернативы Н, если вероятность с его помощью отвергнуть Н, когда на самом деле верна Н, стремится к 1 при неограниченном увеличении объема наблюдений.
Состоятельный против всех альтернатив критерий, в принципе, при большом числе наблюдений, способен обнаружить любое отступление от гипотезы. Таким образом, состоятельность критериев Колмогорова и омега-квадрат означает, что любое отличие распределения выборки от теоретического будет с их помощью обнаружено, если наблюдения будут продолжаться достаточно долго.
Практическую значимость свойства состоятельности не велика, так как трудно рассчитывать на получение большого числа наблюдений в неизменных условиях, а теоретическое представление о законе распределения, которому должна подчиняться выборка, всегда приближённое. Поэтому точность статистических проверок не должна превышать точность выбранной модели. Свойство состоятельности является желательным.
1.2 Критерии согласия 2 Пирсона для простой гипотезы
Теорема К. Пирсона относится к независимым испытаниям с конечным числом исходов, т.е. к испытаниям Бернулли (в несколько расширенном смысле). Она позволяет судить о том, согласуются ли наблюдения в большом числе испытаний частоты этих исходов с их предполагаемыми вероятностями.
Во многих практических задачах точный закон распределения неизвестен. Поэтому выдвигается гипотеза о соответствии имеющегося эмпирического закона, построенного по наблюдениям, некоторому теоретическому. Данная гипотеза требует статистической проверки по результатам которой будет либо подтверждена, либо опровергнута.
Пусть X – исследуемая случайная величина. Требуется проверить гипотезу H0 о том, что данная случайная величина подчиняется закону распределения F(x). Для этого необходимо произвести выборку из n независимых наблюдений и по ней построить эмпирический закон распределения F(x). Для сравнения эмпирического и гипотетического законов используется правило, называемое критерием согласия. Одним из популярных является критерий согласия хи-квадрат К. Пирсона.
В нем вычисляется статистика хи-квадрат:
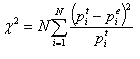 (2.1)
(2.1)
где N – число интервалов, по которому строился эмпирический закон распределения (число столбцов соответствующей гистограммы), i – номер интервала, pt i -вероятность попадания значения случайной величины в i-й интервал для теоретического закона распределения, pe i – вероятность попадания значения случайной величины в i-й интервал для эмпирического закона распределения. Она и должна подчиняться распределению хи-квадрат.
Если вычисленное значение статистики превосходит квантиль распределения хи-квадрат с k-p-1 степенями свободы для заданного уровня значимости, то гипотеза H0 отвергается. В противном случае она принимается на заданном уровне значимости. Здесь k – число наблюдений, p число оцениваемых параметров закона распределения.
Рассмотрим статистику:
![]() (2.2)
(2.2)
Статистика 2 называется статистикой хи-квадрат Пирсона для простой гипотезы.
Ясно, что 2 представляем собой квадрат некоего расстояния между двумя r-мерными векторами: вектором относительных частот (mi /n, …, mr /n) и вектором вероятностей (pi , …, pr ). От евклидового расстояния это расстояние отличается лишь тем, что разные координаты входят в него с разными весами.
Обсудим поведение статистики 2 в случае, когда гипотеза Н верна, и в случае, когда Н неверна. Если верна Н, то асимптотическое поведение 2 при n указывает теорема К. Пирсона. Чтобы понять, что происходит с (2.2), когда Н неверна, заметим, что по закону больших чисел mi /n pi при n , для i = 1, …, r. Поэтому при n :
![]() (2.3)
(2.3)
Эта величина равна 0. Поэтому если Н неверна, то 2 (при n ).
Из сказанного следует, что Н должна быть отвергнута, если полученное в опыте значение 2 слишком велико. Здесь, как всегда, слова «слишком велико» означают, что наблюденное значение 2 превосходит критическое значение, которое в данном случае можно взять из таблиц распределения хи-квадрат. Иначе говоря, вероятность Р(2 npi 2 ) – малая величина и, следовательно, маловероятно случайно получить такое же, как в опыте, или еще большее расхождение между вектором частот и вектором вероятностей.
Асимптотический характер теоремы К. Пирсона, лежащий в основе этого правила, требует осторожности при его практическом использовании. На него можно полагаться только при больших n. Судить же о том, достаточно ли n велико, надо с учетом вероятностей pi , …, pr . Поэтому нельзя сказать, к примеру, что ста наблюдений будет достаточно, поскольку не только n должно быть велико, но и произведения npi , …, npr (ожидаемые частоты) тоже не должны быть малы. Поэтому проблема аппроксимации 2 (непрерывное распределение) к статистике 2 , распределение которой дискретно, оказалась сложной. Совокупность теоретических и экспериментальных доводов привела к убеждению, что эта аппроксимация применима, если все ожидаемые частоты npi 10. если число r (число различных исходов) возрастает, граница для npi можетбыть снижена (до 5 или даже до 3, если r порядка нескольких десятков). Чтобы соблюсти эти требования, на практике порой приходится объединять несколько исходов, т.е. переходить к схеме Бернулли с меньшим r.
Описанный способ для проверки согласия можно прилагать не только к испытаниям Бернулли, но и к произвольным выборкам. Предварительно их наблюдения надо превратить в испытания Бернулли путем группировки. Делают это так: пространство наблюдений разбивают на конечное число непересекающихся областей, а затем для каждой области подсчитывают наблюденную частоту и гипотетическую вероятность.
В данном случае к перечисленным ранее трудностям аппроксимации прибавляется еще одна – выбор разумного разбиения исходного пространства. При этом надо заботится о том, чтобы в целом правило проверки гипотезы об исходном распределении выборки было достаточно чувствительным к возможным альтернативам. Наконец, отмечу, что статистические критерии, основные на редукции к схеме Бернулли, как правило, не являются состоятельными против всех альтернатив. Так что такой метод проверки согласия имеет ограниченную ценность.
1.3 Критерии согласия для сложной гипотезы
На практике задача о согласии данных наблюдений с некоторым совершенно конкретным распределением, встречается реже, чем задача проверки сложной гипотезы, которую мы рассматриваем ниже.
Более трудной, но более важной для приложений задачей является проверка гипотезы о том, что данная выборка подчиняется определенному параметрическому закону распределения, например нормальному закону. Параметры этого закона остаются неопределенными, так что эта гипотеза сложная.
Пусть x1 , …, xn – выборка из распределения с функцией распределения
F(x, ![]() ). Здесь
). Здесь ![]() - неизвестный параметр, не обязательно скалярный.[11] Обозначим его истинное значение через
- неизвестный параметр, не обязательно скалярный.[11] Обозначим его истинное значение через ![]() . Сейчас мы не можем сравнить выборочную функцию распределения Fn
(x) и теоретическую, поскольку эта последняя нам не вполне известна: в ее выражение F(x,
. Сейчас мы не можем сравнить выборочную функцию распределения Fn
(x) и теоретическую, поскольку эта последняя нам не вполне известна: в ее выражение F(x, ![]() ) входит неопределенный параметр
) входит неопределенный параметр ![]() . Мы, однако, можем найти для
. Мы, однако, можем найти для ![]() приближенное значение, основываясь на выборке x1
, …, xn
. Для этого можно использовать разные методы оценивания, но наиболее ясные и в определенном смысле наилучшие результаты получаются, если использовать метод наибольшего правдоподобия.
приближенное значение, основываясь на выборке x1
, …, xn
. Для этого можно использовать разные методы оценивания, но наиболее ясные и в определенном смысле наилучшие результаты получаются, если использовать метод наибольшего правдоподобия.
Итак, пусть ![]() n
– оценка наибольшего правдоподобия по выборке x1
, …, xn
для неизвестного параметра
n
– оценка наибольшего правдоподобия по выборке x1
, …, xn
для неизвестного параметра ![]() распределения F(x,
распределения F(x, ![]() ). Теперь для вычисления статистики Колмогорова вместо F(x,
). Теперь для вычисления статистики Колмогорова вместо F(x, ![]() ) мы можем использовать F(x,
) мы можем использовать F(x, ![]() n
) и ввести модифицированную статистику Колмогорова:
n
) и ввести модифицированную статистику Колмогорова:
![]() (3.1)
(3.1)
Аналогично, модифицированная статистика омега-квадрат есть:
![]() (3.2)
(3.2)
Свойства статистик Dn
и ![]() во многом повторяют отмеченные ранее свойства статистик Dn
и
во многом повторяют отмеченные ранее свойства статистик Dn
и ![]() . В частности,
. В частности, ![]() и n
и n![]() неограниченно возрастают, если проверяемая гипотеза неверна. Поэтому эту гипотезу следует отвергнуть, если наблюденное значение
неограниченно возрастают, если проверяемая гипотеза неверна. Поэтому эту гипотезу следует отвергнуть, если наблюденное значение ![]() (или n
(или n![]() , если применяется модифицированный критерий омега-квадрат) неправдоподобно велико, например, превосходит критическое значение, о котором будет сказано ниже.
, если применяется модифицированный критерий омега-квадрат) неправдоподобно велико, например, превосходит критическое значение, о котором будет сказано ниже.
Важно отметить, что статистика Dn
распределена иначе, чем Dn
(1.1), а статистика ![]() – иначе, чем
– иначе, чем ![]() (1.5). Причина в том, что из-за подбора
(1.5). Причина в том, что из-за подбора ![]() n
по выборке функций F(x) и F(x,
n
по выборке функций F(x) и F(x, ![]() n
) (в случае, если гипотеза о типе распределения верна) оказываются ближе к друг другу, чем F(x) и F(x,
n
) (в случае, если гипотеза о типе распределения верна) оказываются ближе к друг другу, чем F(x) и F(x, ![]() ). Поэтому при справедливости гипотезы статистика Dn,
как правило, будет принимать существенно меньше значения, чем Dn
. Аналогично соотносятся
). Поэтому при справедливости гипотезы статистика Dn,
как правило, будет принимать существенно меньше значения, чем Dn
. Аналогично соотносятся ![]() и
и ![]() .
.
Поскольку статистики (3.1), (3.2) при справедливости гипотезы имеют иные распределения, чем статистики Dn
и ![]() , для их применения необходимы таблицы распределений или хотя бы таблицы критических значений. К сожалению, модифицированные статистики (3.1), (3.2) не обладают столь привлекательным свойством «свободы от распределения выборки», как их прототипы, поэтому для каждого параметрического семейства распределений нужны свои таблицы. Более того, распределения (3.1), (3.2) могут зависеть и от истинного значения неизвестного параметра (параметров).[4] К счастью, для так называемых «масштабно-сдвиговых» семейств, к которым относятся нормальные, показательное и многие другие практически важные распределения, этого последнего осложнения не возникает.
, для их применения необходимы таблицы распределений или хотя бы таблицы критических значений. К сожалению, модифицированные статистики (3.1), (3.2) не обладают столь привлекательным свойством «свободы от распределения выборки», как их прототипы, поэтому для каждого параметрического семейства распределений нужны свои таблицы. Более того, распределения (3.1), (3.2) могут зависеть и от истинного значения неизвестного параметра (параметров).[4] К счастью, для так называемых «масштабно-сдвиговых» семейств, к которым относятся нормальные, показательное и многие другие практически важные распределения, этого последнего осложнения не возникает.
Таблицы распределений статистик (3.1), (3.2) к настоящему моменту составлены для многих семейств. Большинство из них рассчитаны методом случайных испытаний (методом Монте-Карло). Автор большинства этих расчетов М. Стефенс заметил, что зависимость результатов от объема выборки резко уменьшается, если вместо Dn
, ![]() использовать их несколько преобразованные варианты. Стефенс утверждает, что для этих форм зависимость от n практически перестает сказываться, начиная с n = 5. ниже приводятся некоторые таблицы Стефенса.
использовать их несколько преобразованные варианты. Стефенс утверждает, что для этих форм зависимость от n практически перестает сказываться, начиная с n = 5. ниже приводятся некоторые таблицы Стефенса.
Табл. 3.1 Модифицированные критерии для проверки нормальности, оба параметра неизвестны
| Статистика | Модифицированная форма | Верхние процентные точки 0.15 0.10 0.05 0.025 0.01 |
| Dn | 0.775 0.819 0.895 0.955 1.035 | |
| 0.091 0.104 0.126 0.148 0.178 |
Табл. 3.2 Модифицированные критерии для проверки экспоненциальности, параметр неизвестен
| Статистика | Модифицированная форма | Верхние процентные точки 0.15 0.10 0.05 0.025 0.01 |
| Dn | 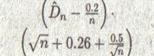 |
0.926 0.990 1.094 1.190 1.308 |
| 0.149 0.177 0.224 0.273 0.337 |
Предельное (при n ) распределение n![]() известно, но вычисляется довольно сложно. Предельное распределение для
известно, но вычисляется довольно сложно. Предельное распределение для ![]() найти не удалось, есть лишь приближенные формулы для критических значений, основанные на асимптотических разложениях. Сравнение расчетов по этим формулам с упомянутыми ранее таблицами показало их хорошее согласие. Как уже говорилось, для каждого параметрического семейства критические значения надо рассчитывать особо. Например, для нормального закона, оба параметра которого оцениваются по выборке, для больших z 0 (т.е. для z ).
найти не удалось, есть лишь приближенные формулы для критических значений, основанные на асимптотических разложениях. Сравнение расчетов по этим формулам с упомянутыми ранее таблицами показало их хорошее согласие. Как уже говорилось, для каждого параметрического семейства критические значения надо рассчитывать особо. Например, для нормального закона, оба параметра которого оцениваются по выборке, для больших z 0 (т.е. для z ).
![]() (3.3)
(3.3)
Если же математическое ожидание известно и равно, скажем, а, то по выборке приходится оценивать только дисперсию. В этом случае для больших z 0
![]() (3.4)
(3.4)
Эти приближенные формулы дают хорошие результаты для малых вероятностей и больших объемов выборок, то есть для вероятностей, начиная примерно с 0.20 (и меньше) и для объемов n, начиная примерно с 100 (и больше).
1.4 Критерии согласия 2 Фишера для сложной гипотезы
Для проверки сложных гипотез может быть использована и соответствующая модификация критерия хи-квадрат Пирсона. Главные заслуги здесь принадлежат Р. Фишеру. Приведу одну из его теорем (сохраняя обозначения из теоремы К. Пирсона).
Теорема Фишера. Пусть n – число независимых повторений опыта, который может заканчиваться одним из r (r – произвольное натуральное число) элементарных исходов, скажем, А1
, …, Аr
. Пусть вероятности этих элементарных исходов известны с точностью до некоторого неопределенного, скажем, k-мерного параметра ![]() = (
= (![]() 1
, …,
1
, …, ![]() k
). Тогда эти вероятности являются функциями от
k
). Тогда эти вероятности являются функциями от ![]() : Р(Аі
) = рі
(
: Р(Аі
) = рі
(![]() ). Будем предполагать, что функции р1
(
). Будем предполагать, что функции р1
(![]() ), …, рr
(
), …, рr
(![]() ) заданы, дифференцируемы,
) заданы, дифференцируемы, ![]() для всякого
для всякого ![]() , а параметр
, а параметр ![]() изменяется в ограниченной области пространства. Тогда при n статистика:
изменяется в ограниченной области пространства. Тогда при n статистика:
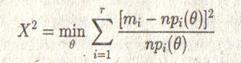 (4.1)
(4.1)
асимптотически распределена по закону 2 с r – k – l степенями свободы.
Существует много вариантов этой теоремы. Например, такое же, как выше, предельное распределение имеет статистика
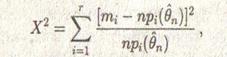 (4.2)
(4.2)
где ![]() n
– оценка наибольшего правдоподобия для параметра
n
– оценка наибольшего правдоподобия для параметра ![]() ,
найденная по частотам т1
, …, тr
. Поэтому значение (4.2) в дальнейшем можно использовать вместо (4.1). Далее, знаменатели прі
в (4.1) и (4.2) можно заменить на ті
, і = 1, …, r , и это не отразится на асимптотическом распределении 2
. Есть и другие возможности.
,
найденная по частотам т1
, …, тr
. Поэтому значение (4.2) в дальнейшем можно использовать вместо (4.1). Далее, знаменатели прі
в (4.1) и (4.2) можно заменить на ті
, і = 1, …, r , и это не отразится на асимптотическом распределении 2
. Есть и другие возможности.
Статистика 2 из (4.1) (и ее варианты) называется статистикой хи-квадрат Фишера для сложной гипотезы.
Статистику (4.1) (и ее варианты) можно использовать для проверки описанной выше сложной гипотезы о параметрическом виде вероятностей в схеме Бернулли
![]()
где р1
(·), …, рr
(·) – заданы, а параметр ![]() изменяется в заданной ограниченной области. Это можно делать так же, как мы делали с помощью статистики 2
в случае простой гипотезы.
изменяется в заданной ограниченной области. Это можно делать так же, как мы делали с помощью статистики 2
в случае простой гипотезы.
А именно, по наблюденным частотам т1
, …, тr
надо вычислить значение 2
(4.1) либо (4.2) и затем сравнить его с критическими значениями распределения 2
с числом степеней свободы (r – k – l), либо вычислить Р(2
2
). Однако для использования аппроксимации хи-квадрат для распределения 2
необходимо, чтобы число наблюдений было достаточно велико, и тем самым ожидаемые частоты прі
(![]() ) не были малыми.
) не были малыми.
Как следует из формулировки теоремы, объект ее применения – испытания с конечным числом исходов. Чтобы использовать ее в условиях другого эксперимента – например, для проверки гипотезы о типе непрерывного или дискретного распределения с бесконечным (или конечным, но большим) числом исходов – этот эксперимент надо предварительно превратить в схему Бернулли. Раньше уже говорилось, как это делается обычно – путем разбиения выборочного пространства на непересекающиеся области. Параметрический (зависящий от параметра ![]() ) закон распределения вероятностей во всем пространстве, соответствие которого нашей выборке мы хотим проверить, превращается при этом в параметрическое распределение вероятностей между выбранными r областями.
) закон распределения вероятностей во всем пространстве, соответствие которого нашей выборке мы хотим проверить, превращается при этом в параметрическое распределение вероятностей между выбранными r областями.
Понятно, что результат последующего применения критерия хи-квадрат (принять гипотезу, отвергнуть гипотезу) сильно зависит от описанного перехода. К этому следует добавить условие применимости распределения 2 , которое требует, чтобы ожидаемые частоты были достаточно большими. (условие на ожидаемые частоты часто приходиться заменять требованием, чтобы не были малы наблюдаемые частоты т1 , …, тr .) становится ясно, что подготовка к применению критерия хи-квадрат в несвойственных ему составляет деликатную и не всегда простую проблему. Возникает даже опасность невольной подгонки выбираемого разбиения к желательному результату. Поэтому, строго говоря, разбиение пространства на области должно идти вне зависимости от результатов случайного эксперимента, т.е. вне влияния подлежащей обработке выборки.
Как же после всех этих предостережений можно применить теорему Фишера к проверке гипотезы о типе выборки? Обсудим это на примере нормального распределения, параметры которого (а, 2 ) неизвестны.
Итак, есть выборка х1 , …, хп большого объема, проверить нормальность которой мы хотим с помощью (4.1) или (4.2) или их модификаций. Прежде всего мы должны разбить числовую прямую на r непересекающихся областей, а еще прежде – выбрать само число r. Сейчас существует убеждение (подкрепленное асимптотическими исследованиями), что против гладкой альтернативы лучше брать r небольшим – несколько единиц. Если же конкурируют с нормальным распределением все другие возможности, число r стоит взять таким большим, какое позволяет последующее использование аппроксимации хи-квадрат.
Допустим, что r уже выбрано, и можно переходить к разбиению пространства на области. При этом надо позаботится о том, чтобы ожидаемые частоты этих областей были достаточно велики для того, чтобы для 2 действовала аппроксимация 2 . поскольку истинное распределение вероятностей неизвестно, приходится опираться на какую-либо его оценку. В данном примере – на оценку
![]()
истинной функции распределения
![]()
Чтобы не ломать бесплодно голову над вопросом, какими должны быть вероятности этих областей, а точнее в данном случае – их приближенные значения, возьмем их одинаковыми. Иными словами, в качестве границ интервалов используем решения уравнений
![]() ,
, ![]()
Замечу, что в качестве оценки функций распределения можно использовать и выборочную функцию распределения Fn (х), и другие возможности. В этом случае границами интервалов разбиения будут служить выборочные квантили (порядковые статистики).
После того, как мы определили интервалы разбиения числовой прямой, подсчитываем частоты т1 , …, тr , по которым будем вычислять потом статистику 2 (4.1) или (4.2) или какую- либо эквивалентную.
Следует подчеркнуть, что согласно теореме Фишера, для вычисления участвующих в этих формулах вероятностей рі
(![]() ) следует использовать частоты т1
, …, тr
, и только их. Никакой другой информацией пользоваться нельзя! Нельзя, например, использовать
) следует использовать частоты т1
, …, тr
, и только их. Никакой другой информацией пользоваться нельзя! Нельзя, например, использовать ![]() составлены по всей выборке ,а должны быть – по частотам ті
.
составлены по всей выборке ,а должны быть – по частотам ті
.
Можно даже сказать, какие последствия повлечет за собой нарушение этого запрета. Статистика 2
не будет (асимптотически) следовать распределению 2
с r – l степенями свободы (как было бы при точно известных параметрах). Ее функция распределения пройдет несколько выше. В качестве иллюстрации на рис. 4.1 приведе6м графики функций распределения хи-квадрат с 8, 10, 18 и 20 степенями свободы. Графики, соответствующие первым двум распределениям, выделяют область в которой будет проходить график функции распределения 2
при r = 11, если для вычисления рі
(![]() ) использовались оценки
) использовались оценки ![]() . Последние два графика задают область нахождения функции распределения 2
при r = 21.
. Последние два графика задают область нахождения функции распределения 2
при r = 21.
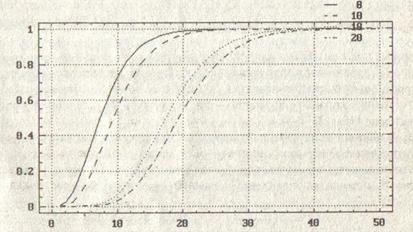
Рис. 4.1 функции распределения хи-квадрат с8,10,18 и 20 степенями свободы.
При больших r относительное развитие между квантилями распределений 2 с (r – 3) и (r – 1) степенями свободы невелико. Поэтому последствия такой ошибки не опасны. Но при r следует действовать «по теории».
Из-за всех этих сложностей, условий и оговорок можно сделать вывод, что для проверки гипотезы о нормальности выборки критерий Р. Фишера подходит плохо. Правильнее вместо этого использовать модификации критериев Колмогорова или омега-квадрат. Но для многих распределений вероятностей (например – дискретных) другой возможности, чем обсуждаемый критерий хи-квадрат Фишера, просто нет.
1.5 Другие критерии согласия. Критерии согласия для распределения Пуассона
Еще одна возможность для проверки согласия, которой тоже часто пользуются. Состоит она в том, что проверяют не исходную гипотезу целиком, а какие-либо ее последствие, которое считается важным. Для нормальной случайной величины коэффициент асимметрии равен нулю.
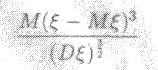 (5.1)
(5.1)
Поэтому коэффициент асимметрии выборки
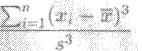 (5.2)
(5.2)
тоже должен быть близок к нулю, если эта выборка – нормальная.
Чтобы судить о том, значимо ли отличается от нуля выборочное значение (5.2), и тем самым, не нарушено ли обязательное для нормального закона соотношение (5.1), надо знать, как распределена статистика (5.2) при гипотезе. Для малых выборок исследование подобных вопросов возможно далеко не всегда и, во всяком случае, требует особого рассмотрения в каждом случае. Иное дело большие выборки.
Есть стандартная методика, которая позволяет справится с этой задачей. Покажем ее действие на другом примере, поскольку о нормальном законе говорилось лишком много. Посмотрим, как можно проверить согласие выборки с распределением Пуассона. Для случайной величины , распределенной по Пуассону
D/М = 1, (5.3)
так как для распределения Пуассона D = М = , где – параметр распределения. Поэтому если выборка х1 , …, хп извлечена из пуассоновской генеральной совокупности, то отношение должно быть близким к 1. Ниже пойдет речь о том как проверить.
![]() (5.4)
(5.4)
Но сначала одно замечание общего характера: такие проверки никак не могут доказать соответствия выборки теоретическому закону даже при неограниченном возрастании числа наблюдений. Причина в том, что соотношение типа (5.1) и (5.3) не являются характеристиками: даже если (5.1) справедливо, оно не означает, что непременно распределено нормально. Это свойство необходимо для нормальности распределения, но не достаточно. То же самое можно сказать о (5.3): это необходимое, но не достаточное условие для того, чтобы распределение было пуассоновским. После этого обсуждения обратимся к изучению свойств статистики (5.4). объем выборки п будет считать большим.
Воспользуемся тем, что при n случайные величины S2 – D и х – М стремятся к 0 (закон больших чисел). Поэтому для пуассоновской выборки:
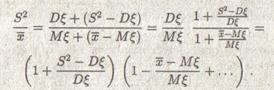
Многоточие заменяет случайную величину, убывающую как n-1 . раскрыв скобки, получаем, что:
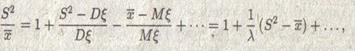
Исследуем при n поведение выражения
![]()
главной случайной составляющей дроби
![]()
Без ущерба для точности вывода вместо S2 можно взять случайную величину:
![]()
Тогда вместо S2 – х появляется:
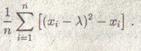
В силу центральной предельной теоремы эта сумма независимых и одинаково распределенных случайных величин распределена приблизительно нормально, с математическим ожиданием:
М[( – )2 – ] = 0 и дисперсией
![]()
Для вычисления последнего выражения надо знать, что четвертый и третий центральные моменты пуассоновского распределения равны соответственно
![]()
После этого подсчет дает, что D[( – )2
– ] = 22
. Следовательно, статистика (5.4) ![]() распределена приблизительно по закону N(1, 22
/ n).
распределена приблизительно по закону N(1, 22
/ n).
Зная распределение статистики (5.4) в случае справедливости нулевой гипотезы о принадлежности выборки к распределению Пуассона, можно указать пределы, в которые с вероятностью приблизительно, скажем, 0.99 должно попадать отношение ![]() в случае справедливости гипотезы:
в случае справедливости гипотезы:
![]() (5.5)
(5.5)
где, и0 обозначает квантиль уровня стандартного нормального распределения.
Если мы хотим использовать это соотношение для практической проверки гипотезы о пуассоновском распределении выборки, надо заметить неизвестное значение его оценкой по выборке. Для больших выборок наилучшей является оценка наибольшего правдоподобия. Которая для пуассоновского распределения равна х. следовательно, надо проверить по выборке, выполняется ли соотношение:
![]() (5.6)
(5.6)
Если это неравенство не выполняется, гипотезу о том, что выборка извлечена из распределения Пуассона, следует отвергать на уровне значимости (примерно) 0.01. понятно, что при другом уровне значимости в правой части (5.5) будет стоять другая квантиль и поэтому правая часть (5.6) тоже будет другой.
Поскольку этот способ проверки приближенный, то чем большего объема окажется выборка в нашем распоряжении, тем точнее будет соблюден номинальный уровень значимости. К сожалению, трудно сказать определенно, начиная с каждого n результат такой проверки заслуживает доверия; по-видимому, для этого требуется не менее сотни наблюдений.
Подобным образом может быть проверено любое свойство теоретического распределения, если только мы располагаем достаточно большой выборкой. Главное здесь – выбор самого свойства. Эта характеристика распределения должна быть существенна для дальнейшего. Как правило, знания о типе распределения нужны для того, чтобы на их основе сделать по выборочным данным те или инее выводы. Нередко оказывается, что для справедливости этих выводов особенно важны лишь ее которые свойства теоретического закона распределения. Именно эти свойства и надо в первую очередь проверить.
РАЗДЕЛ II. ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ КРИТЕРИЯ СОГЛАСИЯ
Все рассмотренные до сих пор критерии принято относить к группе так называемых параметрических критериев. Применение этих критериев требует знания типа распределения наблюдаемых случайных величин (нормальное, биномиальное, пуассоновское, двумерное нормальное или какое-либо иное) и проверяемая гипотеза касается параметров данных распределений. Прежде чем применять параметрические методы, необходимо убедиться в том, что мы действительно имеем дело с распределением требуемого типа.
Предположение о виде распределения случайной величины – это статистическая гипотеза, которую можно проверить с помощью экспериментальных данных. Критерии, позволяющие решать такого рода задачи, называются критериями согласия – согласия выборочных данных некоторому наперед заданному теоретическому распределению.
При проверке гипотезы о нормальности распределения с неизвестными средним и дисперсией критерий Колмогорова-Смирнова является более мощным, чем критерий ![]() .
.
При проведении данных исследований, в которых реализован ряд критериев проверки согласия эмпирического распределения с теоретической моделью: ![]() Пирсона, отношения правдоподобия, Колмогорова, Смирнова,
Пирсона, отношения правдоподобия, Колмогорова, Смирнова, ![]() и
и ![]() Мизеса, Никулина. Здесь и ниже, когда мы употребляем словосочетание “хорошее согласие”, то подразумеваем, что по всем критериям достигнутый уровень значимости, определяемый соотношением
Мизеса, Никулина. Здесь и ниже, когда мы употребляем словосочетание “хорошее согласие”, то подразумеваем, что по всем критериям достигнутый уровень значимости, определяемый соотношением
![]()
где ![]() - значение статистики критерия, вычисленное по наблюдаемой выборке,
- значение статистики критерия, вычисленное по наблюдаемой выборке, ![]() - плотность предельного распределения статистики соответствующего критерия при справедливости гипотезы
- плотность предельного распределения статистики соответствующего критерия при справедливости гипотезы ![]() , был очень высок:
, был очень высок:
![]() 0,6-0,9
0,6-0,9
Например, на (Приложения рис.2) представлены результаты моделирования распределения статистики ![]() при вычислении оптимальных L-оценок [5] двух параметров нормального распределения при числе интервалов
при вычислении оптимальных L-оценок [5] двух параметров нормального распределения при числе интервалов ![]() . На рисунке приведены построенная в результате моделирования эмпирическая функция распределения статистики
. На рисунке приведены построенная в результате моделирования эмпирическая функция распределения статистики ![]() , функция теоретического
, функция теоретического ![]() -распределения и значения достигнутого уровня значимости
-распределения и значения достигнутого уровня значимости ![]() при проверке согласия по каждому из используемых критериев.
при проверке согласия по каждому из используемых критериев.
Если же оценки параметров искать по точечным выборкам (по исходным негруппированным наблюдениям), то предельные распределения статистики ![]() не являются
не являются ![]() -распределениями. Более того, распределения статистики
-распределениями. Более того, распределения статистики ![]() становятся зависящими от того, как разбивается область определения случайной величины на интервалы [5]. Как выглядят распределения статистики
становятся зависящими от того, как разбивается область определения случайной величины на интервалы [5]. Как выглядят распределения статистики ![]() при использовании ОМП по точечным выборкам по сравнению с
при использовании ОМП по точечным выборкам по сравнению с ![]() -распределениями иллюстрирует (Приложения рис. 3), на котором приведены распределения
-распределениями иллюстрирует (Приложения рис. 3), на котором приведены распределения ![]() при асимптотически оптимальном группировании (АОГ) и при разбиении на интервалы равной вероятности (РВГ) в случае проверки согласия с нормальным распределением с оцениванием двух его параметров и числе интервалов
при асимптотически оптимальном группировании (АОГ) и при разбиении на интервалы равной вероятности (РВГ) в случае проверки согласия с нормальным распределением с оцениванием двух его параметров и числе интервалов ![]() . При оценивании параметров нормального закона по группированной выборке статистика
. При оценивании параметров нормального закона по группированной выборке статистика ![]() подчинялась бы в данном случае
подчинялась бы в данном случае ![]() -распределению. Как подчеркивает (Приложения рис. 3), распределения статистики
-распределению. Как подчеркивает (Приложения рис. 3), распределения статистики ![]() и
и ![]() очень существенно отличаются от
очень существенно отличаются от ![]() -распределения. Игнорирование этого факта на практике часто приводит к неоправданному отклонению проверяемой гипотезы, к увеличению вероятности ошибок первого рода.
-распределения. Игнорирование этого факта на практике часто приводит к неоправданному отклонению проверяемой гипотезы, к увеличению вероятности ошибок первого рода.
Зная предельные распределения ![]() и
и ![]() статистики
статистики ![]() , для любого заданного уровня значимости
, для любого заданного уровня значимости ![]() можно оценить мощность соответствующего критерия, рассматривая её как функцию от числа интервалов
можно оценить мощность соответствующего критерия, рассматривая её как функцию от числа интервалов ![]() при заданном объеме выборки
при заданном объеме выборки ![]() . Было проведено исследование мощности критериев Пирсона и Никулина как функции от
. Было проведено исследование мощности критериев Пирсона и Никулина как функции от ![]() и
и ![]() аналитически и методами статистического моделирования. Причем результаты аналитических вычислений оказались полностью подтвержденными оценками мощности, полученными на основании моделирования.
аналитически и методами статистического моделирования. Причем результаты аналитических вычислений оказались полностью подтвержденными оценками мощности, полученными на основании моделирования.
Величина мощности для критериев типа ![]() может быть вычислена в соответствии с выражением:
может быть вычислена в соответствии с выражением:
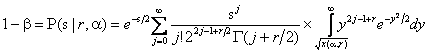
где ![]() - параметр нецентральности,
- параметр нецентральности, ![]() представляет собой
представляет собой ![]() - процентную точку
- процентную точку ![]() -распределения с
-распределения с ![]() степенями свободы (
степенями свободы (![]() - заданная вероятность ошибки первого рода,
- заданная вероятность ошибки первого рода, ![]() - вероятность ошибки второго рода). Все приводимые ниже функции мощности строились при уровне значимости
- вероятность ошибки второго рода). Все приводимые ниже функции мощности строились при уровне значимости ![]() .
.
На (Приложение рис. 4) в зависимости от числа интервалов ![]() при равновероятном и асимптотически оптимальном группировании для объема выборок
при равновероятном и асимптотически оптимальном группировании для объема выборок ![]() , равного 500 и 5000, представлены функции мощности критерия
, равного 500 и 5000, представлены функции мощности критерия ![]() Пирсона при проверке простой гипотезы о согласии с экспоненциальным законом (
Пирсона при проверке простой гипотезы о согласии с экспоненциальным законом (![]() :
: ![]() при
при ![]() ; против
; против ![]() :
: ![]() при
при ![]() ). И в том, и в другом случае с ростом
). И в том, и в другом случае с ростом ![]() мощность падает, но в случае асимптотически оптимального группирования она выше, чем при равновероятном.
мощность падает, но в случае асимптотически оптимального группирования она выше, чем при равновероятном.
Аналогично, на (Приложения рис. 5) приведены функции мощности критерия ![]() Пирсона как функции числа интервалов
Пирсона как функции числа интервалов ![]() для
для ![]() , равного 300 и 2000, при проверке простой гипотезы относительно нормального закона
, равного 300 и 2000, при проверке простой гипотезы относительно нормального закона
(![]() :
: ![]()
при ![]() ,
, ![]() ; против
; против ![]() : нормальный закон при
: нормальный закон при ![]() ,
, ![]() ).
).
На рис. 5 приведены функции мощности критерия ![]() Пирсона при проверке сложной гипотезы о согласии с распределением Вейбулла. Рассматривались гипотеза
Пирсона при проверке сложной гипотезы о согласии с распределением Вейбулла. Рассматривались гипотеза
![]() :
: 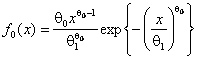
при ![]() ,
, ![]() и близкая альтернатива – распределение Накагами
и близкая альтернатива – распределение Накагами
![]() :
: 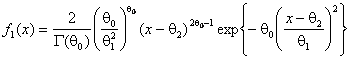
при ![]() ,
, ![]() ,
, ![]()
Рис. 7 иллюстрирует поведение функции мощности критерия типа ![]() Никулина при использовании равновероятного группирования и проверке сложной гипотезы о согласии с нормальным законом
Никулина при использовании равновероятного группирования и проверке сложной гипотезы о согласии с нормальным законом
![]() :
: ![]()
когда в качестве альтернативы рассматривается близкий ему логистический закон
![]() :
: 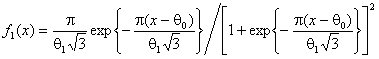
при значениях параметров ![]() ,
, ![]() .
.
Если для конкретной выборки мы отклоняем гипотезу о нормальности, и, следовательно, не имеем права пользоваться методами, основанными на нормальности, то для получения статистических выводов можно поступать разными способами. Например, если объем выборки достаточно велик, можно предпочесть использовать параметрические критерии как приближенные. Другой путь состоит в подборе замены переменной, приводящей к нормальному распределению[9]. Третий путь - применение непараметрических критериев.
Пример. Пусть получена следующая выборка 50 значений случайной величины ![]() с неизвестным распределением: (см. Таблица 1)
с неизвестным распределением: (см. Таблица 1)
Проверим гипотезу о том, что эта случайная величина имеет нормальное распределение. После разбиения области изменения выборочных значений на 5 равных интервалов получаем следующие наблюденные и гипотетические частоты:(см. Приложения Таблица 2)
Гипотетические частоты вычислялись для нормального распределения
![]()
с параметрами, оцененными по выборке - соответственно, число степеней свободы статистики критерия равно 5-1-2=2. Выборочное значение статистики равно ![]() , что не выходит за критический 5%-ный предел, равный
, что не выходит за критический 5%-ный предел, равный ![]() . Следовательно, у нас нет оснований отвергнуть гипотезу о нормальности.
. Следовательно, у нас нет оснований отвергнуть гипотезу о нормальности.
В действительности, выборка была получена с помощью датчика случайных чисел, равномерно распределенных на отрезке [0, 100]. Т.е. мы видим, что при данном числе наблюдений (в общем-то, конечно, небольшом для проверки гипотезы о типе распределения) критерий ![]() не обнаруживает отклонения от нормальности в направлении равномерности.
не обнаруживает отклонения от нормальности в направлении равномерности.
Величина статистики одновыборочного критерия Колмогорова - Смирнова равна D=0.11, что также не выходит за 5%-ный предел этого критерия в предположении, что гипотетические средние равны выборочным. Однако в случае неизвестных параметров гипотетического нормального распределения лучше пользоваться модификацией критерия Колмогорова - Смирнова, предложенной Cтефенсом (Лиллифорсом). Но в этом случае значение
![]()
т.е. нет оснований отвергнуть гипотезу и по этому критерию.
Пример. Расчеты, аналогичные предыдущим, проведенные для выборки объема 150 значений случайной величины, равномерно распределенной на отрезке [0, 100], дали значение ![]() , что позволило отвергнуть гипотезу о нормальности на уровне значимости 5%. По критерию Колмогорова - Смирнова гипотеза отвергалась лишь на уровне 10%, а по критерию Лиллифорса - на уровне 1%, что показывает неправомочность применения критерия Колмогорова - Смирнова в данной ситуации.
, что позволило отвергнуть гипотезу о нормальности на уровне значимости 5%. По критерию Колмогорова - Смирнова гипотеза отвергалась лишь на уровне 10%, а по критерию Лиллифорса - на уровне 1%, что показывает неправомочность применения критерия Колмогорова - Смирнова в данной ситуации.
Пример. Расчеты статистик критериев согласия для данных таблицы 1, содержащей 50 выборочных значений длины лепестка ириса разноцветного, приводят к значению статистики ![]() равному 2.1, и значению статистики
равному 2.1, и значению статистики ![]() , равному 0.117. В этом случае гипотеза о нормальности не отвергается ни критерием
, равному 0.117. В этом случае гипотеза о нормальности не отвергается ни критерием ![]() , ни критерием Колмогорова - Смирнова - Лиллифорса.
, ни критерием Колмогорова - Смирнова - Лиллифорса.
Пример. В некоторых классических экспериментах с селекцией гороха Мендель наблюдал частоты различных видов семян, получаемых при скрещивании растений с круглыми желтыми семенами и растений с морщинистыми зелеными семенами. Они приводятся ниже вместе с теоретическими вероятностями, вычисленными в соответствии с теорией наследственности Менделя. (см. Приложения Таблица 3)
В этом случае теоретическое распределение дискретно и известно полностью. Для проверки согласия экспериментальных данных теоретическому распределению используем критерий ![]() для простой гипотезы. Значение статистики, вычисленное по выборке равно
для простой гипотезы. Значение статистики, вычисленное по выборке равно
![]()
что меньше 5%-ного критического значения
![]()
Следовательно, теория наследственности Менделя не противоречит полученным экспериментальным данным.
Наряду с количественными статистическими критериями для определения типа распределения по выборочным данным используются графические методы.
Простейший способ – построение по имеющейся выборке гистограммы относительных частот и на том же графике и в том же масштабе, - кривой плотности нормального распределения с выборочным средним и выборочной дисперсией в качестве параметров. Значительные отклонения от нормальности (сильная асимметрия, бимодальность) легко обнаруживаются на графике.
Пример: Применим этот прием к рассмотренной выше модельной выборке объема n=50, извлеченной из равномерного распределения. На рис. 7 приведена гистограмма и кривая нормальной плотности. Можно сказать, что визуально отклонение от нормальности в пользу равномерности заметно (хотя, как мы видели, статистически значимо при таком числе наблюдений оно не подтверждается).
С точки зрения визуального обнаружения отклонений от нормальности сравнение эмпирической и гипотетической функций распределения гораздо менее наглядно, чем сравнение гистограммы с графиком плотности. Однако обычно сравнивают на сами функции распределения, а обратные нормальные преобразования от них, так называемые пробит-графики. Пробит-график от теоретической нормальной функции распределения представляет собой прямую, а пробит-график эмпирической функции распределения тем ближе к прямой, чем ближе она к нормальной. Этот прием позволяет на первом этапе анализа данных выявить их особенности, выдвинуть гипотезы о характере распределения, решить вопрос о целесообразности замены переменной. (см. Приложения Рис.1 Пример сравнения гистограммы и кривой нормальной плотности.)
Вывод
Критерии согласия основаны на использовании различных мер расстояния между анализируемым эмпирическим распределением и функцией распределения признака в генеральной совокупности. Критериями согласия называют статистические критерии, предназначенные для проверки согласия опытных данных и теоретической модели.
Существует несколько критерий согласия: критерий согласия Колмогорова и омега-квадрат, 2 Пирсона, 2 Фишера и другие. Состоятельность критериев Колмогорова и омега-квадрат означает, что любое отличие распределения выборки от теоретического будет с их помощью обнаружено, если наблюдения будут продолжаться достаточно долго. Практическую значимость свойства состоятельности не велика, так как трудно рассчитывать на получение большого числа наблюдений в неизменных условиях, а теоретическое представление о законе распределения, которому должна подчиняться выборка, всегда приближённое. Поэтому точность статистических проверок не должна превышать точность выбранной модели.
В данной курсовой работе было исследовано какие критерии согласия существуют и описано каждую по отдельности, применение критерий согласия на практике.
Приложения
Таблица 1
| 45 | 89 | 93 | 40 | 91 | 60 | 2 | 59 | 87 | 78 |
| 57 | 39 | 50 | 0 | 35 | 91 | 67 | 62 | 25 | 93 |
| 19 | 98 | 55 | 78 | 34 | 45 | 86 | 31 | 15 | 95 |
| 50 | 52 | 35 | 66 | 0 | 44 | 93 | 36 | 29 | 44 |
| 17 | 85 | 17 | 63 | 34 | 43 | 100 | 75 | 84 | 9 |
Таблица 2
| Интервал | (20, 40] | (40, 60] | (60, 80] | ||
| Наблюденная частота, nI | 8 |
10 |
12 |
7 |
13 |
Гипотетическая Частота, npi |
6.1 |
9.7 |
13.4 |
11.6 |
9.2 |
Таблица 3
| Семена | Наблюденная численность | Ожидаемая численность |
| Круглые и желтые | 315 | |
| Морщинистые и желтые | 101 | |
| Круглые и зеленые | 108 | |
| Морщинистые и зеленые | 32 | |
| Всего | 556 | 556 |
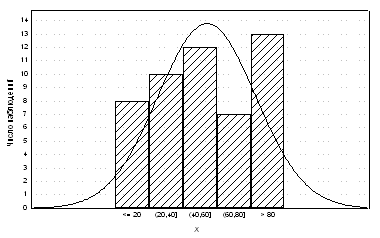
Рис. 1. Пример сравнения гистограммы и кривой нормальной плотности
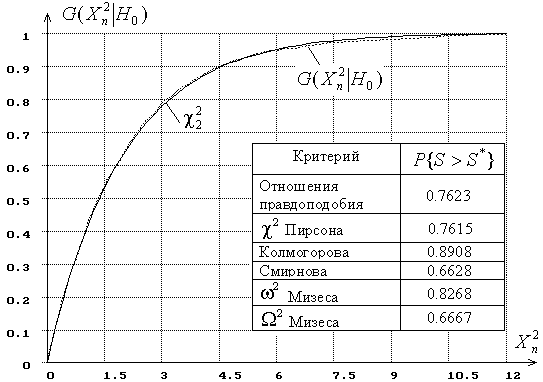
Рис. 2
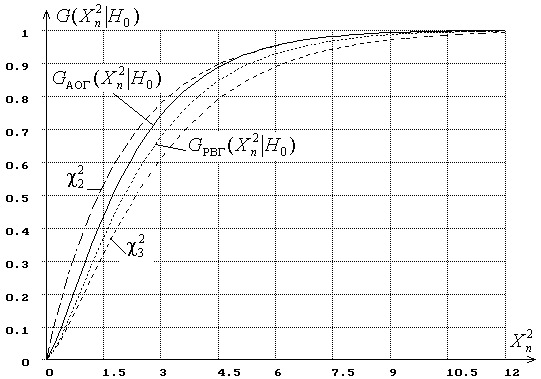
Рис. 3
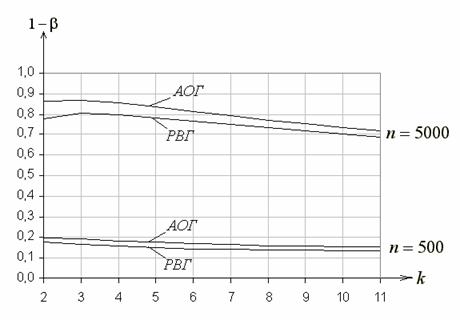
Рис. 4
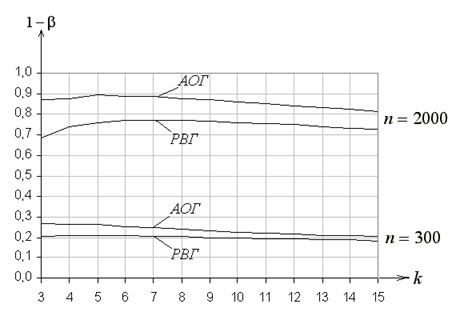
Рис. 5
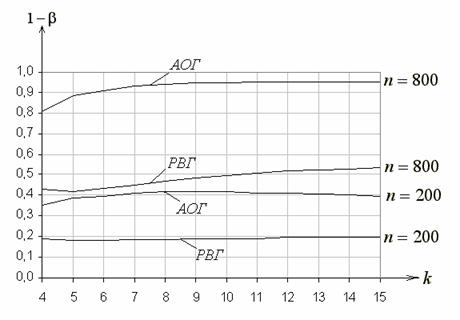
Рис. 6
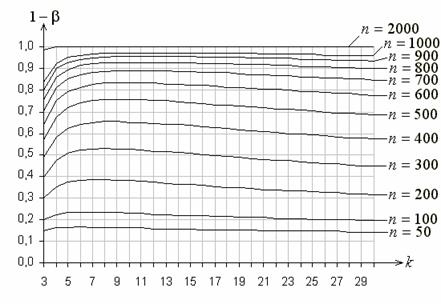
Рис. 7
Список использованной литературы
1. Тюрин Ю.Н., Макаров А.А. Анализ данных на компьютере /Под ред. В. Э. Фигурнова. – 3-е изд., перераб. и доп. – М.:ИНФРА – М. 2003. – 544 с., ил.
2. Электронный учебник по дисциплине Математическая статистика
В. В. Шеломовский, Мурманский федеральный государственный педагогический университет. http://www.exponenta.ru/educat/systemat/shelomovsky/lab/lab14.asp
3. BaseGroup Labs. Технологии анализа данных. http://www.basegroup.ru/glossary/definitions/chi_square_test/
4. Тюрин Ю.Н. Исследования по непараметрической статистике (непараметрические методы и линейная модель): Автореф. дисс. … д–ра физ.–мат. наук. – М., 1985. – 33 с. – (МГУ).
5. Лемешко Б.Ю., Постовалов С.Н. О зависимости предельных распределений статистик ![]() Пирсона и отношения правдоподобия от способа группирования данных // Заводская лаборатория. 1998. – Т. 64. – № 5. – С.56-63.
Пирсона и отношения правдоподобия от способа группирования данных // Заводская лаборатория. 1998. – Т. 64. – № 5. – С.56-63.
6. Общая теория статистики/ Под редакцией А. А. Спирина, О. Э. Башиной. 1995. – 295 с.
7. Кремер Н.Ш. Теория вероятностей и математическая статистика. – М.: Юнити, 2000. – 543 с.
8. Благовещенский Ю.Н., Самсонова В.П., Дмитриев Е.А. Непараметрические методы в почвенных исследованиях. М.: Наука, 1987.
9. Ширяев А.Н. Вероятность. -- М.: Наука, 1989.
10. Майков Е.В. Математический анализ: Числовые ряды. -- М.: Изд-во МГУ, 1999.
11. Бондарев Б.В. О проверке сложных статистических гипотез // Заводская лаборатория. – 1986. – Т. 52. – № 10. – С. 62-63