Курс лекций Математические методы в психологии
СОДЕРЖАНИЕ: 2008 г. В лекциях были использованы материалы следующих авторов. Годфруа Ж Куликов Л. В Немов Р. С 1999 Практикум. Сидоренко Е. В.
Материалы к курсу
«МАТЕМАТИЧЕСКИЕ МЕТ ОДЫ В ПСИХОЛОГИИ»
ЧАСТЬ 1
@Преподаватель: Голев Сергей Васильевич, адъюнкт-профессор психологии (доцент).
@Ассистент: Голева Ольга Сергеевна, магистр психологии
(ОМУРЧ «Украина» ХФ. – 2008 г.)
ИПИС ХГУ - 2008 г. )
В лекциях были использованы материалы следующих авторов:
Годфруа Ж. Что такое психология? М.: Мир, 1996. Т 2 . Куликов Л. В. Психологическое исследование: методические рекомендаций по проведению. - СПб., 1995. Немов Р.С. Психология: Экспериментальная педагогическая психология и психодиагностика. - М., 1999.- Т. 3. Практикум по общей экспериментальной психологии / Под ред. А.А. Крылова. - Л. ЛГУ, 1987. Сидоренко Е.В . Методы математической обработки в психологии. –СПб.: ООО «Речь», 2000. -350 с. Шевандрин Н.И. Психодиагностика, коррекция и развитие личности. - М.: Владос, 1998.-С.123. Суходольский Г.В. Математические методы в психологии. – Харьков: Изд-во Гуманитарный Центр, 2004. – 284 с.
Курс «Математические методы в психологии»
(Материалы для самостоятельного изучения студентами)
Лекция № 1
ВВЕДЕНИЕ В КУРС «МАТЕМАТИЧЕСКИЕ МЕТОДЫ В ПСИХОЛОГИИ»
Вопросы:
1.Математика и психология
2.Методологические вопросы применения математики в психологии
3.Математическая психология
3.1.Введение
3.2.История развития
3.3.Психологические измерения
3.4.Нетрадиционные методы моделирования
4.Словарь по математическим методам в психологии
5.Список рекомендованной литературы по курсу
Вопрос 1. МАТЕМАТИКА И ПСИХОЛОГИЯ
Существует мнение, неоднократно высказывавшееся крупными учеными прошлого: область знания становится наукой, лишь применяя математику. С этим мнением, возможно, не согласятся многие гуманитарии. А зря: именно математика позволяет количественно сравнивать явления, проверять правильность словесных утверждений и тем самым добираться до истины либо приближаться к ней. Математика делает обозримыми длинные и подчас туманные словесные описания, проясняет и экономит мысль.
Математические методы позволяют обоснованно прогнозировать будущие события, вместо того, чтобы гадать на кофейной гуще или как-либо иначе. В общем, польза от применения математики велика, но и труда на ее освоение требуется много. Однако он окупается сполна.
Психология в своем научном становлении неизбежно должна была пройти и прошла путь математизации, хотя не во всех странах и не в полной мере. Точной даты начала пути математизации, пожалуй, не знает ни одна наука. Однако для психологии в качестве условной даты начата этого пути можно принять 18 апреля
1822 г . Именно тогда в Королевском немецком научном обществе Иоганн Фридрих Гербарт прочел доклад «О возможности и необходимости применять в психологии математику». Основная идея доклада сводилась к упомянутому выше мнению: если психология хочет быть наукой, подобно физике, в ней нужно и можно применять математику.
Спустя два года после этого программного по своей сути доклада И. Ф. Гербарт издал книгу «Психология как наука, заново основанная на опыте, метафизике и математике». Эта книга примечательна во многих отношениях. Она, на мой взгляд (см. Г.В Суходольский, [8]), явилась первой попыткой создания психологической теории, опирающейся на тот круг явлений, которые непосредственно доступны каждому субъекту, а именно на поток представлений, сменяющих друг друга в сознании. Никаких эмпирических данных о характеристиках этого потока, полученных, подобно физике, экспериментальным путем, тогда не существовало. Поэтому Гербарт в отсутствие этих данных, как он сам писал, должен был придумывать гипотетические модели борьбы всплывающих и исчезающих в сознании представлений. Облекая эти модели в аналитическую форму,например =(l-exp[-t]) ,где t—время, —скорость изменения представлений, и — константы, зависящие от опыта, Гербарт, манипулируя числовыми значениями параметров, пытался описать возможные характеристики смены представлений.
По-видимому, И. Ф. Гербарту первому принадлежит мысль о том, что свойства потока сознания — это величины и, следовательно, они в дальнейшем развитии научной психологии подлежат измерению. Ему также принадлежит идея «порога сознания», и он первый употребил выражение «математическая психология».
У И. Ф. Гербарта в Лейпцигском университете нашелся ученик и последователь, позднее ставший профессором философии и математики, — Мориц-Вильгельм Дробиш. Он воспринял, развил и по-своему реализовал программную идею учителя. В словаре Брокгауза и Ефрона о Дробише сказано, что еще в 30-х годах Х1Х века он занимался исследованиями по математике и психологии и публиковался на латинском языке. Но в 1842г . М.В.Дробиш издал в Лейпциге на немецком языке монографию под недвусмысленным названием: «Эмпирическая психология согласно естественнонаучному методу».
На мой взгляд, эта книга М.-В. Дробиша дает замечательный пример первичной формализации знаний в области психологии сознания. Там нет математики в смысле формул, символики и расчетов, но там есть четкая система понятий о характеристиках потока представлений в сознании как взаимосвязанных величинах. Уже в предисловии М.-В. Дробиш написал, что эта книга предваряет другую, уже готовую, — имеется в виду книга по математической психологии. Но поскольку его коллеги-психологи недостаточно подготовлены в математике, постольку он счел необходимым продемонстрировать эмпирическую психологию сначала безо всякой математики, а лишь на твердых естественнонаучных основах.
Не знаю, подействовала ли эта книга на тогдашних философов и богословов, занимавшихся психологией. Скорее всего — нет. Но она, несомненно, подействовала, как и работы И. Ф. Гербарта, на лейпцигских ученых с естественнонаучным образованием.
Лишь через восемь лет, в 1850 г . в Лейпциге вышла в свет вторая основополагающая книга М.-В. Дробиша—«Первоосновы математической психологии». Таким образом, у этой психологической дисциплины тоже есть точная дата появления в науке. Некоторые современные психологи, пишущие в области математической психологии, ухитряются начинать ее развитие с американского журнала, появившегося в 1963 г. Воистину, «все новое — это хорошо забытое старое». Целое столетие до американцев развивалась математическая психология, точнее — математизированная психология. И начало процессу математизации нашей науки положили И. Ф. Гербарт и М.-В. Дробиш.
Надо сказать, что по части новаций математическая психология Дробиша уступает сделанному его учителем — Гербартом. Правда, Дробиш к двум борющимся в сознании представлениям добавил третье, а это сильно усложнило решения. Но главное, по-моему, в другом. Большую часть объема книги составляют примеры численного моделирования. К сожалению, ни современники, ни потомки не поняли и не оценили научного подвига, совершенного М.-В. Дробишем: у него ведь не было компьютера для численного моделирования. А в современной психологии математическое моделирование — это продукт второй половины XX века. В предисловии к нечаевскому переводу гербартианской психологии российский профессор А. И. Введенский, знаменитый своей «психологией без всякой метафизики», весьма пренебрежительно отозвался о попытке Гербарта применять в психологии математику. Но не такова была реакция естествоиспытателей. И психофизики, в частности Теодор Фехнер, и знаменитый Вильгельм Вундт, работавшие в Лейпциге, не могли пройти мимо основополагающих публикаций И.Ф.Гербартаи М.-В. Дробиша. Ведь именно они математически реализовали в психологии идеи Гербарта о психологических величинах, порогах сознания, времени реакций сознания человека, причем реализовали с использованием современной им математики.
Основные методы тогдашней математики—дифференциальное и интегральное исчисления, уравнения сравнительно несложных зависимостей — оказались вполне пригодными для выявления и описания простейших психофизических законов и различных реакций человека Но они не годились для изучения сложных психических явлений и сущностей. Не зря В.Вундт категорически отрицал возможность эмпирической психологии исследовать высшие психические функции. Они оставались, по Вундту, в ведении особой, по сути метафизической, психологии народов.
Математические средства для изучения сложных многомерных объектов, в том числе высших психических функции — интеллекта, способностей, личности, стали создавать англоязычные ученые. Среди других результатов оказалось, что рост потомков как бы стремится возвратиться к среднему росту предков. Появилось понятие «регрессия», и были получены уравнения, выражающие эту зависимость. Был усовершенствован коэффициент, раньше предложенный французом Бравэ. Этот коэффициент количественно выражает соотношение двух изменяющихся переменных, т. е. корреляцию. Теперь этот коэффициент — одно из важнейших средств многомерного анализа данных, дажесимвол сохранил аббревиатурный: малое латинское «г» от английского relation — отношение.
Еще будучи студентом Кембриджа, Фрэнсис Гальтон заметил, что рейтинг успешности сдачи экзаменов по математике,—а это был выпускной экзамен, —- изменяется от нескольких тысяч до немногих сотен баллов. Позднее, связав это с распределением талантов, Гальтон пришел к мысли о том, что специальные испытания позволяют прогнозировать дальнейшие жизненные успехи людей. Так в 80-х гг. XIX века родился гальтоновский метод тестов.
Идею тестов подхватили и развили французы—А. Бит, В. Анри и другие, создавшие первые тесты для селекции социально отсталых детей. Это послужило началом психологической тестологии, что, в свою очередь, повлекло за собой развитие психологических измерений.
Большие массивы числовых результатов измерений по тестам— в баллах, стали объектом многочисленных исследований, в том числе математико-психологических. Особая роль здесь принадлежит английскому инженеру, работавшему в Америке, —Чарльзу Спирмену
Во-первых , Ч. Спирмен, полагавший, что для вычисления корреляции между рядами целочисленных баллов, или рангов, нужна специальная мера, перепробовав разные варианты (я читал его объемную статью в Американском психологическом журнале за 1904 г.), остановился, наконец, на той форме коэффициента корреляции рангов, которая с тех пор носит его имя.
Во-вторых , имея дело с большими массивами числовых результатов по тестам и корреляций между этими результатами, Ч. Спирмен предположил, что эти корреляции вовсе не выражают взаимовлияние результатов, а эксплицируют их совместную изменчивость под влиянием обшей латентной психической причины, или фактора, например интеллекта. Соответственно этому Спирмен предложил теорию «генерального» фактора, определяющего совместную изменчивость переменных тестовых результатов, а также разработал метод выявления этого фактора по корреляционной матрице. Это был первый метод факторного анализа, созданный в психологии и для психологических целей.
У однофакторной теории Ч. Спирмена быстро нашлись оппоненты. Противоположную, многофакторную теорию, объясняющую корреляции, предложил Леон Терстоун. Ему же принадлежит первый метод мультифакторного анализа, основанный на применении линейной алгебры. После Ч. Спирмена и Л. Терстоуна факторный анализ, не только стал одним из важнейших математических методов многомерного анализа данных в психологии, но и вышел далеко за ее пределы, превратился в общенаучный метод анализа, данных.
С конца 20-х гг XX века математические методы все шире проникают в психологию и творчески используются в ней. Интенсивно развивается психологическая теория измерений. На основе аппарата цепей Маркова разрабатываются стохастические модели научения в психологии поведения. Созданный в области биологии Рональдом Фишером дисперсионный анализ становится основным математическим методом в генетической психологии. Математические модели из теории автоматического регулирования и шенноновская теория информации широко применяются в инженерной и общей психологии. В итоге современная научная психология во многих своих отраслях математизирована значительным образом. При этом вновь появляющиеся математические новации нередко заимствуются психологами для своих целей. К примеру, появление алгоритмического языка для задач управления, предложенного А. А. Ляпуновым и Г. А. Шестопалом, почти сразу же бьшо использовано В.Н.Пушкиным для составления алгоритмов деятельности железнодорожного диспетчера.
Должен возникнуть вопрос: какими особыми свойствами обладает математика, если одни и те же математические методы успешно применяются в различных науках. Отвечая на этот вопрос, следует обратиться к предмету математики и ее объектам.
На протяжении многих столетий считалось, что предметом математики является все сущее — природа в широком смысле. Математики древности полагали, что математические формы имеют божественное происхождение. Так, Платон рассматривал геометрические фигуры как идеальные эйдосы, т. е. образы, созданные высшими богами для копирования людьми, конечно, уже не в той совершенной форме. А знаменитый Пифагор видел в числах и определенных числовых сочетаниях предустановленную гармонию небесных сфер.
Религиозное мировоззрение людей веками связывало божественное творение мира с математическими средствами, с помощью которых выражаются законы природы. Глубоко религиозный сэр Исаак Ньютон верил, что «книга природы написана на языке математики», и широко использовал математические методы в своей натуральной философии.
Надо сказать, что, даже отказавшись от веры в божественное творение мира, многие математики продолжали считать природу предметом математики. Нам широко известна формулировка, данная в свое время Ф. Энгельсом : «Предметом математики служат пространственные формы и количественные отношения материального мира». Еще и сегодня можно встретить эту формулировку в учебной литературе. Правда, появились и другие трактовки предмета — как наиболее абстрактных моделей всего сущего. Но здесь, намой взгляд, предмет математики опять-таки сужен до служебной функции — моделирования и снова природы в широком смысле.
Спрашивается, а правильно ли это, отказавшись от идеи творения, по-прежнему считать природу предметом математики? Ведь это не только не последовательно. Дело в том, что один и тот же природный закон можно выразить математически по-разному и в пределах научной точности нельзя доказать, какое из выражений истинно. Примером могут служить логарифмический закон Вебера—Фехнера и степенной закон Стивенса, которые, как показал Ю. М. Забродин, оба выводятся при определенных допущениях из некоего обобщенного психофизического закона. То обстоятельство, что один и тот же математический метод описывает явления из разных наук, тоже свидетельствует не в пользу природы как предмета математики.
Так если не природа, то что же является предметом математики? Мой ответ, несомненно, крайне удивит многих представителей физико-математических наук: предметом математики является ее собственный продукт—те математические объекты, из которых состоит математика как наука.
Математический объект — это продукт человеческой мысли, материализованный хотя бы в одной из пяти основных форм: вербальной, графической, табличной, символической или аналитической. Конечно, древний мыслитель мог найти в природе аналоги математическим объектам — геометрическим формам, числам, как-либо физически воплощенным (прямая тростинка, пять камней и т. п.). Но ведь математическую сущность надо было абстрагировать от материальной природной формы. Лишь после этого она становилась математической, а не физической (биологической и т.д.). И сделать это мог только человек. В длинном ряду поколений — и для практических целей, и ради интереса — люди создавали тот мир математических объектов (включая отношения и операции над объектами, которые тоже суть математические объекты), который называется математикой.
Подобно психологии, математика — это обширная и бурно развивающаяся область знаний. Но она также далеко не однородна: в ее составе выделяются не только многочисленные отрасли, но и «разные математики». Существуют «чистая» и прикладная, «непрерывная» и дискретная, «не конструктивная» и конструктивная, формально-логическая и содержательная математики.
Пожалуй, так же как нет психолога, знающего все отрасли психологии, так нет и математика, знающего все отрасли и направления современной математики. Ведь даже энциклопедии и справочники наряду с классическими, традиционными разделами, общими для всех, содержат различные дополнительные, причем отнюдь не новые разделы математических сведений. Обилие и разнообразие математических теорий и методов порождает проблемы выбора и практического использования математики за ее пределами, в том числе в психологии. Но об этом мы поговорим в последней главе книги.
Абстрактный характер математики, ее независимость от природы в широком смысле и позволяют использовать математические методы в самых разных приложениях. Разумеется, при этом важно, чтобы метод был адекватен объекту, для изучения которого применяется.
Для того чтобы завершить рассмотрение общих вопросов, остановимся на том, что понимается под математическими методами.
В каждой науке, помимо ее предмета, предполагают существующими особые, свойственные данной науке методы. Так, для современной психологии характерным является метод тестов. Используемые в ней методы наблюдения, беседы, эксперимента и т.д., о которых пишется в учебниках, не являются специфичными для психологии и широко используются в других науках. Вообще, за редким исключением, современные научные методы универсальны и применяются везде, где можно.
Аналогично обстоит дело с математикой. И хотя большинство математиков убеждены в специфичности аксиоматического подхода, математической индукции и доказательств, на самом деле все эти методы используются и за пределами математики.
Как я уже отмечал, математические объекты существуют в текстах и мыслях думающих о них людей в одной, нескольких или всех из пяти основных форм — словесной, графической, табличной, символической и аналитической. Это названия объектов, геометрические фигуры или чертежи и графики, различные таблицы, символы объектов, операций и отношений, наконец, различные формулы, которыми выражаются отношения между объектами. Так вот математические методы представляют собой правила или процедуры построения, преобразования, метризации и вычисления математических объектов—всего четыре основных типа методов. Среди каждого из них есть простые и сложные, как, например, суммирование двух чисел и факторизация корреляционной матрицы. Пятый тип — комбинированный из основных — открывает неограниченные возможности конструирования новых математических методов, необходимых для определенных научных приложений.
Заканчивая, отмечу, что многие методы играют служебную роль в самой математике, как, в частности, доказательства теорем или определенные строгости изложения, так приветствуемые математиками. Для практических приложений математических методов за пределами математики, в том числе в психологии, математические строгости и тонкости не нужны: они затеняют суть результатов, в которых математика должна находиться на заднем плане, как, например, логарифмическая основа психофизического закона Вебера—Фехнера.
Вопрос 2. МЕТОДОЛОГИЧЕСКИЕ ВОПРОСЫ ПРИМЕНЕНИЯ МАТЕМАТИКИ В ПСИХОЛОГИИ
Маститые психологи, имеющие базовое гуманитарное образование, критически относятся к применению математических методов в психологии, сомневаются в их полезности. Их аргументы таковы: математические методы создавались в науках, объекты которых не сравнимы по сложности с психологическими объектами; психология слишком специфична, что бы в ней была польза от математики.
Первый аргумент в определенной мере справедлив. Поэтому именно в психологии создавались математические методы, специально рассчитанные на сложные объекты, например, корреляционный и факторный анализы. Но второй аргумент явно ошибочен: психология не специфичнее многих других наук, где применяется математика. И сама история психологии подтверждает это. Вспомним идеи И. Гербарта и М.-В. Дробиша, да и весь путь развития современной психологии. Он подтверждает расхожую истину: область знания становится наукой, когда начинает применять математику.
Остапук Ю. В., Суходольский Г. В. Об индивидных, субъектных и личностных проявленияхиндивидуальнойтревожности//Ананьевскиечтения - 2003. СПб., Изд-во СПбГУ. С. 58-59.
В психологии всегда было много мигрантов из естественных наук, а в XX веке — из наук технических. Неплохо подготовленные в области математики мигранты, естественно, применяли доступную им математику в новой психологической области, не достаточно учитывая существенную психологическую специфику, которая, конечно, существует в психологии, как и в любой науке. В результате в психологических отраслях появилась масса математических моделей, малоадекватных в содержательном отношении. Особенно это относится к психометрии и инженерной психологии, но и к общей, социальной и другим «популярным» психологическим отраслям.
Малоадекватные математические формализмы отталкивают от себя гуманитарно ориентированных психологов и подрывают доверие к математическим методам. А между тем мигранты в психологию из естественных и технических наук уверены в необходимости математизации психологии вплоть до такого уровня, когда само существо психики будет выражено математически. При этом считается, что в математике достаточно методов для психологического использования и психологам нужно только выучить математику.
В основе этих воззрений лежит ошибочная, как я считаю, мысль о всесилии математики, о ее способности, так сказать, вооружившись пером и бумагой, открывать новые тайны, подобно тому, как в физике был предсказан позитрон.
При всем моем уважении и даже любви к математическим методам, должен сказать, что математика не всесильна; она является одной из наук, но, благодаря абстрактности своих объектов, легко и с пользой применимой в других науках. Действительно , в любой науке полезен расчет, и важно представлять закономерности в лаконичной символической форме, использовать наглядные схемы и чертежи. Однако, применение математических методов за пределами математики должно приводить к утрате математической специфики.
Идущая из глубины веков вера в то, что «книга природы написана на языке математики», идущем от господа Бога — создавшего всего и вся, привела к тому, что и в языке и в мышлении ученых закрепились выражения «математические модели», «математические методы» в экономике, биологии, психологии, физике, но как могут существовать математические модели в физике? Ведь в ней должны быть и, конечно, существуют физические модели, построенные с помощью математики. И создают их физики, владеющие математикой, или математики, владеющие физикой.
Короче говоря, в математической физике должны быть математико-физические модели и методы, а в математической психологии — математико-психологические. Иначе, в традиционном варианте «математических моделей» имеет место математический редукционизм.
Редукционизм вообще является одной из основ математической культуры: всегда сводить неизвестную, новую задачу к известной и решать ее апробированными методами. Именно математический редукционизм служит причиной появления малоадекватных моделей в психологии и других науках.
Еще недавно среди наших психологов было распространенным мнение: психолога должны формулировать задачи для математиков, которые смогут их корректно решить. Это мнение явно ошибочное: решать специфические задачи могут лишь специалисты, но являются ли таковыми в психологии математики, — нет, конечно. Рискну утверждать, что математикам также трудно решать психологические задачи, как психологам — задачи математические: ведь надо изучать ту научную область, к которой задача относится, а на это годы нужны и еще интерес к «чужой» научной области, в которой иные критерии научных достижений. Так, математику для научной стратификации необходимо совершать «математические» открытия—доказывать новые теоремы. Причем же здесь психологические задачи? Их должны решать сами психологи, которым надо научиться использовать подходящие математические методы. Таким образом, снова возвращаемся к вопросу об адекватности и полезности математических методов в психологии.
Не только в психологии, но в любой науке, полезность математики состоит в том, что ее методы обеспечивают возможность количественных сравнений, лаконичные символические интерпретации, обоснованность прогнозов и решений, экспликацию правил управления. Но все это — при условии адекватности применяемых математических методов.
Адекватность — это соответствие: метод должен соответствовать содержанию, причем соответствовать в том смысле, что бы отображение не математического содержания математическими средствами было гомоморфным. К примеру, обычные множества не адекватны для описания процессов познания: в них не отображается частота необходимых повторений. Адекватными здесь будут лишь мультимножества. Читатель, познакомившийся с содержанием текста предыдущих глав, легко поймет, что рассмотренные математические методы в целом адекватны для психологических приложений, а в деталях адекватность нужно оценивать конкретно.
Общее правило таково: если психологический объект характеризуется конечным набором свойств, то адекватный метод отобразит весь набор, а если, что-то не отобразится, то и адекватность снижается. Таким образом, мерой адекватности служит количество отображаемых методом содержательных свойств. При этом важны два обстоятельства: наличие конкурирующих, эквивалентных по возможности применения, методов и возможность взаимных вербально-символических, табличных, графических и аналитических отображений результатов.
Среди конкурирующих методов следует выбирать наиболее простые, либо понятные, и желательно проверять результат разными методами. Например, дисперсионным анализом и математическим планированием эксперимента можно обоснованно выявлять зависимости в науке.
Не следует ограничиваться одной-двумя из математических форм, нужно, по видимости (а она всегда существует) использовать их все, создавая определенную избыточность в математическом описании результатов.
Важнейшим условием конкретного применения математических методов является, — помимо их понимания, разумеется, — содержательная и формальная интерпретация. В психологии следует различать и уметь выполнять четыре вида интерпретаций; психолого-психологические, психолого-математические, математико-математические и (обратные) математико-психологические. Они организованы в цикл.
Любая научно-исследовательская или практическая задача в психологии сначала подвергается психолого-психологическим интерпретациям, посредством которых от теоретических воззрений переходят к операционально определяемым понятиям и эмпирическим процедурам. Затем наступает черед психолого-математических интерпретаций, с помощью которых выбираются и реализуются математические методы эмпирического исследования. Полученные данные надо обработать и в процессе обработки осуществляются математико-математические интерпретации. Наконец, результаты обработки следует интерпретировать содержательно, т. е. выполнить математико-психологическую интерпретацию уровней значимости, аппроксимированных зависимостей и т. д. Цикл замкнулся, и либо задача решена и можно переходить к другой, либо необходимо уточнить предыдущую и повторить исследование. Такова логика действий в применении математики, — и не только в психологии, но и в других науках.
И последнее. Нельзя досконально изучить все рассмотренные в этой книге математические методы впрок, раз и навсегда. Для овладения любым достаточно сложным методам нужны многие десятки, а то и сотни обучающих попыток. Но познакомится с методами и попытаться их понять в общем и целом нужно впрок, а с деталями можно познакомится в дальнейшем, по мере надобности.
Вопрос 3. Математическая психология
3.1. Введение
Математическая психология — это раздел теоретической психологии, использующий для построения теорий и моделей математический аппарат.
«В рамках математической психологии должен осуществляться принцип абстрактно-аналитического исследования, в котором изучается не конкретное содержание субъективных моделей действительности, а общие формы и закономерности психической деятельности» [Крылов, 1995].
Объект математической психологии : естественные системы, обладающие психическими свойствами; содержательные психологические теории и математические модели таких систем. Предмет — разработка и применение формального аппарата для адекватного моделирования систем, обладающих психическими свойствами. Метод — математическое моделирование.
Процесс математизации психологии начался с момента ее выделения в экспериментальную дисциплину. Этот процесс проходит ряд этапов.
Первый — применение математических методов для анализа и обработки результатов экспериментального исследования, а также выведение простых законов (конец XIX в. — начало XX в.). Это время разработки закона научения, психофизического закона, метода факторного анализа.
Второй (40-50-е гг.) — создание моделей психических процессов и поведения человека с использованием ранее разработанного математического аппарата.
Третий (60-е гг. по настоящее время) — выделение математической психологии в отдельную дисциплину, основная цель которой — разработка математического аппарата для моделирования психических процессов и анализа данных психологического эксперимента.
Четвертый этап еще не наступил. Этот период должен характеризоваться становлением психологии теоретической и отмиранием — математической.
Часто математическую психологию отождествляют с математическими методами, что является ошибочным. Математическая психология и математические методы соотносятся друг с другом так же, как теоретическая и экспериментальная психология.
3.2. История развития
Термин «математическая психология» стал применяться с появлением в 1963 г. в США «Руководства по математической психологии» [Handbook, 1963]. В эти же годы здесь начинает издаваться журнал «Journal of Mathematical Psychology».
Проведенный в лаборатории математической психологии ИП РАН анализ работ позволил выделить основные тенденции развития математической психологии.
В 60—70-е гг. получили широкое распространение работы по моделированию обучения, памяти, обнаружения сигналов, поведения, принятия решений. Для их разработки использовался математический аппарат вероятностных процессов, теории игр, теории полезности и др. Было завершено создание математической теории обучения. Наиболее известны модели Р. Буша, Ф. Мостеллера, Г. Бауэра, В. Эс-теса, Р. Аткинсона. (В последующие годы наблюдается снижение количества работ по данной проблематике.) Появляется множество математических моделей по психофизике, например С. Стивенса, Д. Экмана, Ю. Забродина, Дж. Светса, Д. Грина, М. Михайлевской, Р. Льюса (см. разд. 3.1). В работах по моделированию группового и индивидуального поведения, в том числе в ситуации неопределенности, использовались теории полезности, игр, риска и стохастические процессы. Это модели Дж. Неймана, М. Цетлина, В. Крылова, А. Тверского, Р. Льюса. В рассматриваемый период создавались глобальные математические модели основных психических процессов.
В период до 80-х гг. появляются первые работы по психологическим измерениям: осуществляется разработка методов факторного анализа, аксиоматики и моделей измерения, предлагаются различные классификации шкал, ведется работа над созданием методов классификации и геометрического представления данных,
строятся модели, основанные на лингвистической переменной (Л. Заде).
В 80-е гг. особое внимание уделяется уточнению и развитию моделей, связанных с разработкой аксиоматики различных теорий.
В психофизике это: современная теория обнаружения сигналов (Д. Свете, Д. Грин), структуры сенсорных пространств (Ю. Забродин, Ч. Измайлов), случайных блужданий (Р. Льюс, 1986), различения Линка и др.
В области моделирова ния группового и индивидуального поведения : модель решения и действия в психомоторных актах (Г. Коренев, 1980), модель целенаправленной системы (Г. Коренев), «деревья» предпочтения А. Тверского, модели системы знаний (Дж. Грино), вероятностная модель научения (А. Дрынков, 1985), модель поведения в диадном взаимодействии (Т. Савченко, 1986) моделирование процессов поиска и извлечения информации из памяти (Р. Шифрин, 1974), моделирование стратегий принятия решений в процессе обучения (В. Венда, 1982) и др.
В теории измерения:
• множество моделей многомерного шкалирования (МШ), в которых прослеживается тенденция к снижению точности описания сложных систем — модели предпочтения, неметрическое шкалирование, шкалирование в псевдоевклидовом пространстве, МШ на «размытых» множествах (Р. Шепард, К. Кумбс, Д. Краскал, В. Крылов, Г Головина, А. Дрынков);
• модели классификации: иерархические, дендритные, на «размытых» множествах (А. Дрынков, Т. Савченко, В. Плюта);
• модели конфирматорного анализа, позволяющие формировать культуру проведения экспериментального исследования;
• применение математичеекого моделирования в психодиагностике (А. Анастази, П. Клайн, Д. Кендалл, В. Дружинин)
В 90-х гг. глобальные математические модели психических процессов практически не разрабатываются, однако значительно возрастает количество работ по уточнению и дополнению существующих моделей, продолжает интенсивно развиваться теория измерений, теория конструирования тестов; разрабатываются новые шкалы, более адеквантые реальности (Д. Льюс, П. Саппес, А. Тверски, А. Марли); широко внедряется в психологию синергетический подход к моделированию.
Если в 70-е гг. работы по математической психологии в основном появлялись в США, то в 80-е наблюдается бурный рост ее развития в России, в настоящее время, к сожалению, заметно снизившийся из-за недостаточного финансирования фундаментальной науки.
Наиболее значимые модели появились в 70-е-начале 80-х гг., далее они дополнялись и уточнялись. В 80-е гг. интенсивно развивалась теория измерений. Эта работа продолжается и сегодня. Особенно важно, что многие методы многомерного анализа получили широкое применение в экспериментальных исследованиях; появляется множество специально ориентированных на психологов программ анализа данных психологического тестирования.
В США большое внимание уделяется чисто математическим вопросам моделирования. В России же, наоборот, математические модели зачастую не обладают достаточной строгостью, что приводит к неадекватному описанию реальности.
Математические модели в психологии. В математической психологии принято выделять два направления: математические модели и математические методы. Мы нарушили эту традицию, так как считаем, что нет необходимости выделять отдельно методы анализа данных психологического эксперимента. Они являются средством построения моделей: классификации, латентных структур, семантических пространств и др.
3.3. Психологические измерения
В основе применения математических методов и моделей в любой науке лежит измерение. В психологии объектами измерения являются свойства системы психики или ее подсистем, таких, как восприятие, память, направленность личности, способности и т.д. Измерение — это приписывание объектам числовых значений, отражающих меру наличия свойства у данного объекта.
Назовем три важнейших свойства пси хологических измерений.
1. Существование семейства шкал, допускающих различные группы преобразований.
2. Сильное влияние процедуры измерения на значение измеряемой величины.
3. Многомерность измеряемых психологических величин, т. е. существенная их зависимость от большого числа параметров.
В психологических измерениях используются различные классификации типов шкал. Тип шкалы определяется природой измеряемой величины.
Общая концепция измерения впервые была в достаточно развитом виде сформулирована Д. Скоттом и П. Суппесом. Дальнейшее развитие она получила в работах П. Суппеса и Дж. Зиннеса, Д. Льюса и Е. Галантера и др. В последнее время общая теория измерений интенсивно развивается И. Пфанцаглем, а также Д. Льюсом и Л. Неренсом. В этой концепции широко используется понятие реляционной системы (системы с отношениями), введенное А. Тверским.
С. Стивенс пытался создать свою систему шкальных типов, основываясь на понятиях эмпирической операции и математической структуры. Он различает четыре вида шкал: наименований, порядка, интервалов и отношений.
Типы шкал обусловливаются видом функции f, осуществляющей допустимые преобразования = f ().
*Если f — монотонная функция, то соответствующая шкала является шкалой порядка;
*если f — линейная функция, то соответствующая шкала — это шкала интервалов;
*если f определяет преобразование подобия, то соответствующая шкала — шкала отношений.
К. Кумбс расширяет классификацию Стивенса введением шкал, частично упорядоченных и сложных (комбинированных из двух частей: объектов и расстояний). Он различает три основных типа неметрических шкал и девять типов сложных, однако если рассматривать лишь сами объекты, то комбинированные шкалы тождественны номинальным.
Классификация Торгенсона, как и Кумбса, опирается на предположение о том, что шкальные типы следует трактовать как формальные математические модели. Его классификация включает следующие типы шкал: порядковые — без начала отсчета и с началом отсчета, интервальные — без начала отсчета и с началом отсчета.
Суппес и Зиннес переосмыслили теорию классификации Стивенса в терминах классов числового приписывания: для дифференциации шкал существенны лишь свойства числовых приписываний с точки зрения допустимых преобразований, но никак не эмпирические операции. К. Берка (1987) считает, что вполне достаточно различать метрические и неметрические типы шкал, которые представляют два эмпирико-математических метода шкалирования и измерения. Таким образом, интервальную шкалу можно трактовать как специфический вариант шкалы порядка, т. е. шкалы неметрического типа.
Американские авторы в публикациях 90-х гг. (см. журнал «Journal of Mathematical Psychology») описывают множество работ по применению теории измерений к разработке шкал для ранжирования и выбора альтернатив (В. Malakooty,1991), для измерения нетранзитивного аддитивного объединения (P. Fishburn, 1991) и экспериментов с использованием попарного сравнения по шкалам отношений (I. Basak, 1992). Полемика вокруг основ измерений не прекращается.
Анализ существующих методов прямых оценок различия показал, что шкалы, с которыми работает испытуемый, не соответствуют природе психологического механизма, лежащего в основе оценивания. Поэтому был предложен подход, основанный на «нечетких» множествах (Л. Заде, 1974). Суть его в том , что используются так называемые «лингвистические» переменные вместо числовых переменных или в дополнение к ним; отношения между переменными описываются «нечеткими» («размытыми») высказываниями, а сложные отношения описываются «нечеткими» алгоритмами.
Первая — создание теории однородных сред, элементами которых являются устройства, подобные нейронам.
Вторая — компьютерная графика, помогающая решать задачи с помощью актуализации образного мышления. Когнитивная интерактивная компьютерная графика является средством воздействия на правополушарное мышление человека в процессе научного творчества.
Третья — специалисты различных направлений в области ИИ считают важным развитие работ, касающихся представлений знаний и манипулирования ими (экспертные системы).
4.4.Нетрадиционные методы моделирования
Моделирование на «размытых» множествах
Нетрадиционный подход к моделированию связан с приписыванием элементу некоторой числовой оценки, которая не может объясняться объективной или субъективной вероятностью, а трактуется как степень принадлежности элемента к тому или иному множеству. Множество таких элементов называется «нечетким», или «размытым» множеством.
Каждое слово х естественного языка можно рассматривать как сжатое описание нечеткого подмножества М(х) полного множества области рассуждений U, где М(х) есть значение х. В этом смысле весь язык как целое рассматривается в качестве системы, в соответствии с которой нечетким подмножествам множества U приписываются элементарные или составные символы (т. е. слова, группы слов и предложения). Так, цвет объекта как некоторую переменную, значения этой переменной (красный, синий, желтый, зеленый и т. д.) можно интерпретировать как символы нечетких подмножеств полного множества всех объектов. В этом смысле цвет является нечеткой переменной, т. е. переменной, значениями которой являются символы нечетких множеств. Если значения переменных — это предложения в некотором специальном языке, то в данном случае соответствующие переменные называются лингвистическими (Л. Заде, Ю. Шрейдер).
Синергетика в психологии
Еще одна альтернатива традиционному математическому аппарату — синергетический подход, в котором математическая идеализация проявляется чувствительностью к начальным условиям и непредсказуемостью исхода для системы. Поведение можно описать с помощью апериодических и поэтому непредсказуемых временных рядов, не ограничиваясь при моделировании стохастическими процессами. Беспорядок в обществе может предшествовать появлению новой структуры, в то время как стохастические системы имеют низкую вероятность порождения интересных структур. Именно апериодические решения детерминированных уравнений, описывающих самоорганизующиеся структуры, помогут прийти к пониманию психологических механизмов самоорганизации (Фриман, 1992). В этих работах разум рассматривается как «странный аттрактор», управляемый уравнением сознания. Математически «странный аттрактор» — это множество точек, к которому приближается траектория после затухания переходных процессов.
В основе большинства традиционных моделей психотерапии лежит концепция равновесия. Согласно синергетическому подходу, разум является нелинейной системой, которая при далеких от равновесия условиях превращается в части сложных аттракторов, а равновесие — лишь предельный случай. Этот тезис развивают теоретики психотерапии, выбирая тот или иной аспект теории хаоса. Так, например, выделяется феномен хаотического в психофизиологической саморегуляции (Stephen, Franes, 1992) и обнаруживаются аттракторы в паттернах семейного взаимодействия (L. Chamber, 1991).
Вопрос 4. СЛОВНИК к курсу «МАТЕМАТИЧНІ МЕТОДИ В ПСИХОЛОГІЇ»
ВЫБОРКА — группа людей, на которой проводится исследование. В противоположность в. генеральной совокупностью называют множество людей, на которых распространяются результаты исследования. В. является частью генеральной совокупности.
ВЫБОРКА ПРЕДСТАВИТЕЛЬНАЯ - такая выборка (см.), которая произведена по правилам, т. е. отражает специфику генеральной совокупности как по составу, так и по индивидуальным характеристикам включенных в нее людей.
ВЫБОРОЧНАЯ ДИСПЕРСИЯ — дисперсия (см.) или разброс данных, характеризующих выборку (см.).
ВЫБОРОЧНОЕ ОТКЛОНЕНИЕ — корень квадратный из величины дисперсии (см.). Определяется по формуле:
ВЫБОРОЧНОЕ РАСПРЕДЕЛЕНИЕ (в математической статистике) — упорядоченное расположение измеренных в эксперименте или в результате проведенной психодиагностики величин от наименьшей к наибольшей, сопровождаемое данными о каждой величине и частоте ее встречаемости в выборке (см.). В. р. нередко представляется в виде соответствующего графика.
ВЫБОРОЧНОЕ СРЕДНЕЕ — среднее значение некоторой величины, определенное по имеющейся выборке ее частных значений. Устанавливается по формуле:
ГИПОТЕЗА — научно обоснованное, вполне вероятное предположение, требующее, однако, специального доказательств для своего окончательного утверждения в качестве теоретического положения Г провернется на истинность в экспериментальном или эмпирическом научном исследовании.
ГИСТОГРАММА — специальное графическое изображение распределения нескольких дискретных величин в выборке (см.). Представляет собой совокупность расположенных рядом друг с другом и вытянутых вверх прямоугольников или прямоугольных в сечении столбиков, высота которых пропорциональна частоте встречаемости каждого из значений переменной в выборке.
ДИСПЕРСИЯ ВЫБОРОЧНАЯ — математико-статистический показатель разброса экспериментальных или психодиагностических данных, характеризующий среднюю величину отклонения индивидуальных показателей от среднего значения переменной по выборке. Д. определяется по формуле:
ДИСПЕРСИОННЫЙ АНАЛИЗ — совокупность методов математико-статистического анализа, объектом рассмотрения которых являются дисперсии (см.) случайных величин. Д. а. позволяет оценивать и сравнивать между собой дисперсии различных выборок, отвечая на вопросы о том, каковы эти дисперсии, являются они одинаковыми или разными и др.
ИНТЕРВАЛ (в математической статистике) — упорядоченный набор величин, находящихся в заданных числовых границах и характеризуемых их средней величиной (см.).
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ — метод математико-статистического анализа, связанный с вычислением и изучением коэффициентов корреляций (см.) между переменными.
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ - математико-статистический показатель связи или зависимости, существующей между переменными величинами. Изменяется в пределах от —1 (абсолютная обратно пропорциональная зависимость) через 0 (отсутствие какой-либо зависимости) до +1 (абсолютная прямо пропорциональная зависимость).
КРИТЕРИЙ ФИШЕРА — математико-статистический критерий, пользуясь которым можно судить о сходстве и различиях в дисперсиях (см.) случайных величин.
МАТЕМАТИЧЕСКАЯ СТАТИСТИКА - область современной математики, основанная на теории вероятностей (см.) и занятая поиском законов изменения и способов измерения случайных величин, обоснованием методов расчетов, производимых с такими величинами.
МЕДИАНА — величина, разделяющая ряд упорядоченных значении на две равные по количеству входящих в них значений половины, так что справа и слева от м. оказываются одинаковые количества значений.
МЕТОДЫ СРАВНЕНИЯ ВЫБОРОЧНЫХ ДАННЫХ - методы математической статистики (см.), предполагающие анализ, обобщение и сравнение между собой данных, полученных на некоторой выборке испытуемых или на нескольких разных выборках.
МОДА (в математической статистике) — числовое значение изучаемого признака, наиболее часто встречающееся в изученной выборке (см.).
ОБЪЕКТ ИССЛЕДОВАНИЯ — тот объект, на котором проводится научное исследование. Объектом психологического исследования, например, является человек или группа людей.
ОБЪЕМ ПОНЯТИЯ — класс или классы объектов, явлений и т. п., к которым относится или которые включает в себя данное понятие.
ОПЕРАЦИОНАЛИЗАЦИЯ — требование, предъявляемое к научным понятиям. О. понятия предполагает указание на конкретные операции или действия, выполнив которые человек может убедиться в том, что данное понятие не является пустым, т. е. в том, что включенные в него явления действительно существуют.
РЕГРЕССИОННЫЙ АНАЛИЗ — метод математической статистики, позволяющий свести множество частных зависимостей между отдельными значениями переменных к их непрерывной линейной зависимости. В результате р. а. получают прямую линию, которая наилучшим образом иллюстрирует (аппроксимирует — говоря математическим языком) общий характер зависимости между изучаемыми переменными величинами.
СТАТИСТИКА — термин, имеющий два основных значения:
а) область математических или практических знаний, в которой представлены способы статистического анализа или обобщенные количественные данные о чем-либо;
б) частный показатель, с помощью которого эти данные представляются.
ТЕОРИЯ ВЕРОЯТНОСТЕЙ — раздел современной математики, рассматривающий случайные величины, а также законы, характеризующие множества и отношения случайных величин.
ТОЧНОСТЬ ПСИХОДИАГНОСТИЧЕСКОЙ МЕТОДИКИ - способность данной методики достаточно точно оценивать степень развития у человека тех психологических качеств, для диагностики которых она предназначена. Чем больше различных градаций уровня развития данных качеств позволяет получать методика, тем она точнее.
ФАКТОР — математико-статистическое понятие, означающее общую причину многих случайных изменений совокупности переменных величин, событий и т. п. Ф. выявляется при помощи специальной математической процедуры, называемой факторным анализом (см.).
ФАКТОРНЫЙ АНАЛИЗ — процедура или метод математической статистики, основанный на анализе корреляций случайных величин и направленный на то, чтобы выявлять группы случайных величин, взаимнокоррелирующих друг с другом. Математико-статистическая основа выявляемых таким образом корреляций называется фактором (см.).
Х критерий — математико-статистический критерий, на основе которого судят о статистической значимости связей, существующих между двумя или несколькими переменными, часть которых рассматривается как причина, часть — как следствия наблюдаемых изменений.
ЭКСПЕРИМЕНТ — метод научного исследования, предполагающий создание некоторых искусственных (экспериментальных) условий и направленный на выявление причинно-следственных зависимостей, существующих между изучаемыми переменными.
Вопрос 5. СПИСОК РЕКОМЕНДОВАНОЇ ЛІТЕРАТУРИ З КУРСУ
А) Перелік підручників та посібників (основна література)
1. Бурлачук Л.Ф. Словарь-справочник по психодиагностике. –СПб.: Питер Ком, 1999. – 528 с. (Серия «Мастера психологии»).
2. Годфруа Ж. Что такое психология? М.: Мир, 1996. Т 2
3. Куликов Л. В. Психологическое исследование: методические рекомендаций по проведению. - СПб., 1995.
4. Немов Р.С. Психология: Экспериментальная педагогическая психология и психодиагностика. - М., 1999.- Т. 3.
5. Практикум по общей экспериментальной психологии / Под ред. А.А. Крылова. - Л. ЛГУ, 1987.
6. Сидоренко Е.В . Методы математической обработки в психологии. –СПб.: ООО «Речь», 2000. -350 с.
7. Шевандрин Н.И. Психодиагностика, коррекция и развитие личности. - М.: Владос, 1998.-С.123.
8. Суходольский Г.В. Математические методы в психологии. – Харьков: Изд-во Гуманитарный Центр, 2004. – 284 с.
Б) Додаткова література
1. Введение в научное исследование по педагогике / Под ред. В. И. Журавлева. М.: 1988.
2. Гершунский Б.С. Педагогическая прогностика. - К., 1986.
3. Гласс Дж., Стенли Дж. Статические методы в педагогике и психологии - М.: 1976.
4. Грабарь М.И., Краснянская К.А. Применение математической статистики в педагогических исследованиях. Непараметрические методы. - М.: Педагогика, 1977.
5. Закс Л. Статистическое оценивание. - М.: Статистика, 1976.
6. Интерпретация и анализ данных в социологических исследованиях / Под ред. В.Г. Андресикова - М.: Наука, 1987.
7. Клименюк А.В. и др. Методология и методика педагогического исследования. Постановка цели и задач исследования. - К., 1988.
8. Крылов В.Ю. Геометрическое представление данных в психологических исследованиях. - М.: Наука, 1990.
9. Кузьмина Н.В. Методы системного педагогического исследования. - Л., 1980.
10. Методичні рекомендації до виконання дипломних робіт студентами педагогічного інституту. - К., 1986.
11. Михеев В.И. Моделирование и методы в теории измерений в педагогике М., 1987.
12. Скалкова Я. Методология и методы педагогического исследования: Пер. с чеш.-М., 1989.
13. Скаткин М.Н. Методология и методика педагогических исследований: в помощь начинающему исследователю. - М., 1986.
14. Сорокин Н.А. Дипломные работы в педагогических вузах: Уч. пос. для студентов пед. вузов-М., 1986.
В) БІБЛІОГРАФІЯ ПО КУРСУ “МАТЕМАТИЧНІ МЕТОДИ В ПСИХОЛОГІЇ”
1 Алимов Ю.И. Альтернатива методу математической статистики. М.: Знание, 1986. 64 с.
2 Ананьев Б.Г. Человек как предмет познания. Л.:ЛГУ. 1969. 339 с.
3 Ананьев Б.Г. О методах современной психологии // Психодиагностические методы (в комплексном лонгитюдном исследовании студентов). Л.: ЛГУ, 1976. С. 13-35.
4 Андреенков В.Г., Аргунова К.Д. и др. Математические методы анализа и интерпретация социологических данных. // Под ред. В.Г. Андреенкова, Ю.Н. Толстовой. М.: Наука, 1989. 171 с.
5 Артемьева Е.Ю; Мартынов Е.М. Вероятностные методы в психологии. М.: МГУ, 1985. 206 с.
6 Ашмарин И.П.. Васильев Н.Н.. Амбросов ВА. Быстрые методы статистической обработки и планирование экспериментов. Л.: ЛГУ, 1974. 76 с.
7 Бадасова А. Личностные факторы суггестора, способствующие внушающему воздействию. Дипломная работа выпускницы специального факультета социальной психологии СПбГУ. СПб. 1994. 75 с.
8 Бергер Н.А., Логинова Н.А. К проблеме соотношения некоторых содержательных и структурных характеристик интеллекта (по методике Векслера)// Современные психолого-педагогические проблемы высшей школы. Л.: ЛГУ, 1974.-С. 63-66.
9 Берн Э. Игры, в которые играют люди. Психология человеческих взаимоотношений; Люди, которые играют в игры. Психология человеческой судьбы. / Пер. с англ. // Общ. ред. М.С. Мацковского. СПб.: Лениздат, 1992. 400 с.
10 Большев Л. Н.. Смирнов Н.В. Таблицы математической статистики. М.: Наука. Главн. редакция физико-математ. литературы, 1983. 416 с.
11 Бурлачук Л.Ф., Морозов СМ Словарь-справочник по математической диагностике. Киев.: Наук. думка, 1989. 200 с.
12 Ван дер Варден В.Л. Математическая статистика. М., 1960. 434 с.
13 Гайда В.К., Захаров В.П. Психологическое тестирование. Учебное пособие. Л.: ЛГУ, 1982. 101с.
14 Ганзен ВА, Балин В.Д. Теория и методология психологического исследования. Практическое руководство. СПб.: СПбГУ, 1991. 74 с.
15 Геодакян В.А. Дифференциальная смертность и норма реакции мужского и женского пола. Онтогенетическая и филогенетическая пластичность. // Журнал общей биологии, 1974, т.35, №3. С. 376-385.
16 Геодакян В.А. Асинхронная асимметрия (половая и латеральная дифференциация — следствие асинхронной эволюции). //Журнал ВНД, 1993, т.43. Вып.З. С. 543-561.
17 Гласс Дж., Стенли Дж. Статистические методы в педагогике и психологии. / Пер. с англ. под общ. ред. Ю.П. Адлера. М.: Прогресс, 1976. 495 с.
18 Гоголь Н.В. Избранные произведения. М.: ДетГИЗ, 1959. С. 473-500.
19 Грекова И. Методологические особенности прикладной математики на современном этапе ее развития. // Вопросы философии, 1976, №6, С. 104-114.
20 Гублер Е.В. Вычислительные методы анализа и распознавания патологических последствий. Л.: Медицина, 1978. 296 с.
21 Гублер Е.В., Генкин А А. Применение непараметрических критериев статистики в медико-биологических исследованиях. Л.: Медицина, 1973. 142 с.
22 Девятко И.Ф. Диагностическая процедура в социологии. Очерки истории и теории. М.: Наука, 1993. 173 с.
23 Дворяшина М.Д., Пехлецкий И. Д. Основные математические процедуры психодиагностического исследования.// Психодиагностические методы (в комплексном лонгитюдном исследовании студентов). Л.: ЛГУ, 1976. С. 35-51.
24. Доброхотова Т.А., Брагина Н.Н . Левши. М.: Книга, 1994. – 230 с.
25 Езекиэл М., Фокс К.А. Методы анализа корреляций и регрессий (линейных и криволинейных).// Пер. с англ. Л.С. Кучаева. М.: Статистика, 1966. 559 с.
26 Захаров В.П. Применение математических методов в социально-психологических исследованиях. Учебное пособие. Л.: ЛГУ, 1985. 64 с.
27 Ивантер Э.В.. Коросов А.В. Основы биометрии: Введение в статистический анализ биологических явлений и процессов. Учебное пособие. Петрозаводск: ПТУ. 1992. 163 с.
28 Ильин Е.П. Психофизиология физического воспитания. Деятельность и состояния. Учебное пособие для студентов факультетов физического воспитания педагогических институтов. М.: Просвещение, 1980. 199 с.
29 Ильина М.Н. Способность к проявлению терпения при мышечном утомлении как отражение общего волевого фактора. / Психомоторика. Сборник ученых трудов. // Под ред. Б.А. Ашмарина и проф Е.П. Ильина (научн. ред.). Л.: ЛГПИ, 1976. С. 49-50.
30 Кендалл М.Дж., Стюарт А. Статистические алгоритмы в социологических исследованиях. Новосибирск: Наука, 1985. 207 с.
31 Кенуй М.Г. Быстрые статистические вычисления. Упрощенные методы оценивания и проверки. / Пер. с англ. и предисловие Д.А. Астринского. М.: Статистика, 1979. 69 с.
32 Королькова НА. Возможности психологической коррекции у болезненных детей. Дипломная работа выпускницы кафедры социальной психологии факультета психологии СПбГУ. СПб., 1994. 72 с.
33 Кузнецов С .А. Стили реагирования на вербальную агрессию. Дипломная работа выпускника кафедры социальной психологии факультета психологии СПбГУ. СПб., 1991. 33с.
34 Кулева Е.Б. Влияние традиционных и православных текстов внушения на процесс аутогенной тренировки. Дипломная работа выпускницы кафедры социальной психологии факультета психологии СПбГУ. СПб., 1990. 45 с-
35 Курочкин МА„ Сидоренко Е.В., Чураков ЮА. ( Kurochkin М.. Chumkou U., Sidorenko E.). Opportunities for Leadership in Healthcare. General Practiciner» Research Project for Lilly Industries. Manchester: Manchester Business School, 1992. 22 p.
36 Дашков К.В., Поляков Л.Е. Непараметрические методы медико-статистических исследований. / Методологические вопросы санитарной статистики. Ученые записки по статистике, т. IX. М.: Наука, 1965. С. 136-184.
37 Логвиненко А.Д. Измерения в психологии М.: МГУ. 1993. 480 с.
38 Математические методы анализа и интерпретация социологических данных. // Отв. ред. В.Г. Андреенков, Ю.Н. Толстова. М.: Наука, 1989. - 171 с.
39 Математические методы психолого-педагогнческих исследований. Методические рекомендации. СПб.: Образование. 1994. 28 с.
40 Мельников В.М„ Ямпольский Л.Т. Введение в экспериментальную психологию личности. Учебное пособие для слушателей ИПК преподавателей педагогических дисциплин университетов и педагогических институтов. М.: Просвещение, 1985. 319с.
41 Методы современной биометрии. М.: МГУ, 1978. С. 108-179.
42 Митрополъский А.К. Техника статистических вычислений. М.: Наука, Главная редакция физико-математической литературы., 1971. 576 с.
43 Михеев В.Н. Методика получения и обработки экспериментальных данных в психолого-педагогических исследованиях. М.: УДН, 1986. 84 с.
44 Налимов В. В. Теория эксперимента. М.: Наука, 1975.207 с.
45 Налимов В. В., Голикова Т. И. Логические основания планирования эксперимента. Изд. 2-е. М.: Металлургия, 1981.152 с.
46 Нискина Н.П. Непараметрические методы математической статистики и решение задач проверки гипотез./ Проблемы компьютеризации и статистики в прикладных науках. Сборник трудов. М.: ВНИИСИ, 1990. С. 73-89.
47 Носенко И.А. Начала статистики для лингвистов. М.: Высшая школа, 1981. 157с.
48 Оуэн Д.Б. Сборник статистических таблиц. / Пер. с англ. Л.Н. Большева и В.Ф. Котельниковой. Изд. 2-е, исправл. М.: Вычислительный центр АН СССР. 1973. 586 с.
49 Паповян С.С. Математические методы в социальной психологии. М.: Наука, 1983. 343 с.
50 Плохинский НА. Дисперсионный анализ. / Под ред. чл.-корр. АН СССР Н.П. Дубинина. Новосибирск: Сиб. Отд. АН СССР, 1960. 124 с.
51 Плохинскии НА. Биометрия. 2-е изд. М.: МГУ, 1970. 368 с.
52 Пуни А.Ц. Психологические основы волевой подготовки в спорте. Учебное пособие. Л.: ГИФК,1977.48с.
53 Пустыльник Е.И. Статистические методы анализа и обработки наблюдений. М : Наука, 1968. 185с.
54 Рахова М.Э. Личностная предрасположенность к определенным видам страха. Дипломная работа выпускницы кафедры социальной психологии факультета психологии СПбГУ. СПб., 1994. 54 с.
55 Роджерс К. Взгляд на психотерапию. Становление человека. / Пер. с англ. / /Общ. ред. и предисл. Е.И.Исениной. М.: Прогресс, Универс. 1994. 480 с.
56 Рунион Р. Справочник по непараметрической статистике. М.: Финансы и статистика, 1982. 198с.
57 Сидоренко (Маркова) Е.В. Связь мотивации достижения с индивидными и личностными свойствами / Вопросы экспериментальной и прикладной психологии. Сборник аспирантских работ. Л.: ЛГУ, 1980. Деп. в ВНТИ №435-80 от 7 февр. 1980. С. 64-72
58 Сидоренко (Маркова) Е.В. Исследование психодиагностических возможностей проективной методики Хекхаузена. / Личность в системе коллективных отношений. Тезисы докладов Всесоюзной конференции в г.Курске. Курск: 1980. С. 43-45
59 Сидоренко (Маркова) Е.В. Мотивационно-волевые особенности личности как фактор успешной деятельности. Дисс. на соискание учен. степ. канд. психол. наук. Л.: ЛГУ. 1984. 262с.
60 Сидоренко (Маркова) Е.В. Психодраматический и недирективный подходы в групповой работе с людьми. Методические описания и комментарии. СПб.: Центр психологической поддержки учителя, 1992. 72 с.
61 Сидоренко Е.В . Экспериментальная групповая психология. Комплекс неполноценности и анализ ранних воспоминаний в концепции Альфреда Адлера. Учебное пособие. СПб.: СПбГУ, 1993. 152 с.
62 Сидоренко Е.В. Опыты реоритационного тренинга. СПб.: Институт тренинга, 1995. 248 с.
63 Сидоренко Е.В.. Дерманова И.Б.. Анисимова О.М„ Витснберг Е.В., Шулыга А.П. Разработка методики отбора и подготовки кадров в представительные органы муниципальной власти. СПб.: Гуманистический и политологический Центр Стратегия, 1994. 26 с.
64 Сочивко Л.Б.. Якунин В.А. Математические модели в психолого- педагогических исследованиях. Учебное пособие. Л.: ЛГУ, 1988. 68 с.
65 Справочник по прикладной статистике. В 2-х т. Т.2 / Пер. с англ. под ред. Э.Ллойда, У. Ледермана, С.А. Айвазяна, Ю.Н. Тюрина. М.: Финансы и статистика, 1990. 526 с.
66 Стан Н.В. Социально-психологическое исследование стереотипов мужественности. Дипломная работа выпускницы кафедры социальной психологии факультета психологии СПбГУ. СПб., 1992. 58 с.
67 Стивенс С. Математика, измерение и психофизика // Экспериментальная психология (Под ред. С.С. Стивенса). // Пер. с англ под ред. действ, чл. АМН СССР П.К. Анохина, докт. пед. наук В.А. Артемова. М.: Иностранная литература, 1960. т.1. С. 19-92.
68 Суходольский Г.В. Основы математической статистики для психологов. Л.: ЛГУ, 1972. 428 с.
69 Суходольский Г.В. Математико-психологические модели деятельности. СПб.: Петрополис,1994.64 с.
70 Тлегенова Г.А. Влияние агрессивности на проксемические характеристики невербального поведения. Дипломная работа выпускницы кафедры социальной психологии факультета психологии СПбГУ. СПб., 1990. 28 с.
71 Телешова Ю.Н. Логика математического анализа социологических данных. М.: Наука, 1991.112с.
72 Тюрин Ю.Н. Непараметрические методы статистики. М.: Знание, 1978. 64 с.
73 Тюрин Ю.Н., Макаров А.А, Анализ данных на компьютере. // Под ред. В.В. Фигурнова. М.: Финансы и статистика, 1995. 384 с.
74 Урбах В.Ю. Математическая статистика для биологов и медиков. М.: Академия наук СССР. 1963. 323 с.
75 Урбах В.Ю. Биометрические методы. Статистическая обработка опытных данных в биологии, сельском хозяйстве и медицине. М.: Наука, 1964. 415 с.
76 Урбах В.Ю. Статистический анализ в биологических и медицинских исследованиях. М.: Медицина, 1975. 295 с.
77 Фелингер А.Ф. Статистические алгоритмы в социологических исследованиях. Новосибирск: Наука, 1985. 385 с.
78 Холлендер М. Вулф Д.А. Непараметрические методы статистики. / Пер. с англ. под ред. Ю.П. Адлера и Ю.Н. Тюрина М.: Финансы и статистика, 1983. 518с.
79 Чиркина Р.Т. Психодннамические факторы памяти. Дипломная работа выпускницы кафедры социальной психологии факультета психологии СПбГУ. СПб., 1995. 80 с.
80 Шеффс Г. Дисперсионный анализ. М.: Наука, 1980. 512с.
Курс «Математические методы в психологии»
(Материалы для самостоятельного изучения студентам психологам и социальным работникам)
Лекция № 2
СТАТИСТИЧЕСКИЙ АНАЛИЗ
ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
Вопросы:
1. Методы первичной статистической обработки результатов эксперимента
2. Методы вторичной статистической обработки результатов эксперимента
Краткое содержание
Методы первичной статистической обработки результатов эксперимента.
Общее представление о методах статистического анализа экспериментальных данных, назначение этих методов. Деление статистических методов на первичные и вторичные. Основные показатели, получаемые в результате первичной обработки экспериментальных данных. Вычисление средней арифметической. Определение дисперсии. Установление примерного распределения данных. Определение моды. Характеристика нормального распределения. Вычисление интервалов.
Методы вторичной статистической обработки результатов эксперимента.
Способы вторичной статистической обработки результатов исследования. Регрессионное исчисление. Сравнение средних величин разных выборок. Сравнение частотных распределений данных. Сравнение дисперсий двух выборок. Установление корреляционных зависимостей и их интерпретация. Понятие о факторном анализе как методе статистической обработки.
Способы табличного и графического представления результатов эксперимента.
Виды таблиц и их построение. Графическое представление экспериментальных данных. Гистограммы и их применение на практике.
Вопрос 1
МЕТОДЫ ПЕРВИЧНОЙ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ РЕЗУЛЬТАТОВ ЭКСПЕРИМЕНТА
Методами статистической обработки результатов экспери мента называются математические приемы, формулы, способы количественных расчетов, с помощью которых показатели, по лучаемые в ходе эксперимента, можно обобщать, приводить в си стему, выявляя скрытые в них закономерности.
Речь идет о таких закономерностях статистического характера, которые существуют между изучаемыми в эксперименте переменными ве личинами .
1. Некоторые из методов математико-статистического анализа позволяют вычислять так называемые элементарные матема т ические статистики , характеризующие выборочное распреде ление данных , например
*выборочное среднее,
* выборочная диспер сия,
* мода,
* медиана и ряд других.
2. Иные методы математической статистики, например
дисперсионный анализ ,
регрессионный анализ, позволяют судить о динамике изменения отдельных статис тик выборки.
3. С помощью третьей группы методов , скажем,
*корреляционного анализа,
факторного анализа,
методов сравнения выборочныеа данных, можно достоверно судить о статистических связях,
существующих между переменными величинами, которые исследуют в данном эксперименте.
Все методы математико-статистического анализа условно де лятся на первичные и вторичные1 .
1 Приводимые здесь определения и высказывания не всегда являются достаточно строгими с точки зрения теории вероятностей и математической статистики как сложившихся областей современной математики. Это сделано для лучшего понимания данного текста студентами, не подготовленными в области математики:
Первичными называют методы, с помощью которых можно получить показатели, непосредственно отражающие результаты производимых в эксперименте измерений.
Соответственно под первичными статистическими показателями имеются в виду те, которые применяются в самих психодиагностических методиках и являются итогом начальной статистической обработки результатов психодиагностики.
Вторичными называются методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности.
К первичным методам статистической обработки относят , например,
* определение выборочной средней величины,
* выборочной дисперсии,
* выборочной моды и
* выборочной медианы.
В чис ло вторичных методов обычно включают
*корреляционный анализ,
*регрессионный анализ,
*методы сравнения первичных статистик у двух или нескольких выборок.
Рассмотрим методы вычисления элементарных математичес ких статистик, начав с выборочного среднего.
ВЫБОРОЧНОЕ СРЕДНЕЕ
Выборочное среднее значение как статистический показатель представляет собой среднюю оценку изучаемого в эксперименте психологического качества.
Эта оценка характеризует степень его развития в целом у той группы испытуемых, которая была подвергнута психодиагностическому обследованию. Сравнивая непосредственно средние значения двух или нескольких выборок, мы можем судить об относительной степени развития у людей, составляющих эти выборки, оцениваемого качества.
Выборочное среднее определяется при помощи следующей формулы:

где
хср —выборочная средняя величина или среднее арифметическое значение по выборке;
п — количество испытуемых в выборке или частных психодиагностических показателей, на основе которых вычисляется средняя величина;
xk — частные значения показателей у отдельных испытуемых. Всего таких показателей п, поэтому индекс k данной переменной принимает значения от 1 до п;
— принятый в математике знак суммирования величин тех переменных, которые находятся справа от этого знака.
Выражение 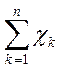 соответственно означает сумму всех х
с индексом k
от 1 до n.
соответственно означает сумму всех х
с индексом k
от 1 до n.
Пример. Допустим, что в результате применения психодиагностической методики для оценки некоторого психологического свойства у десяти испытуемых мы получили следующие частные показатели степени развитости данного свойства у отдельных испытуемых: х1 = 5, х2 = 4, х3 = 5, х4 = 6, х5 = 7, х6 = 3, х7 = 6, х8= 2, х9 = 8, х10 = 4. Следовательно, п = 10, а индекс k меняет свои значения от 1 до 10 в приведенной выше формуле. Для данной выборки среднее значение1 , вычисленное по этой формуле, будет равно:
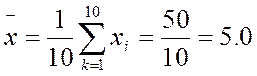
1 В дальнейшем, как это и принято в математической статистике, с целью сокращения текста мы будем опускать слова «выборочное» и «арифметическое» и просто говорить о «среднем» или «среднем значении».
В психодиагностике и в экспериментальных психолого-педагогических исследованиях среднее, как правило, не вычисля ется с точностью, превышающей один знак после запятой, т.е . с большей, чем десятые доли единицы.
В психодиагностических обследованиях большая точность расчетов не требуется и не имеет смысла, если принять во внимание приблизительность тех оценок, которые в них получаются, и достаточность таких оценок для производства сравнительно точных расчетов.
ДИСПЕРСИЯ
Дисперсия как статистическая, величина характеризует, насколько частные значения отклоняются от средней величины в данной выборке.
Чем больше дисперсия, тем больше отклонения или разброс данных. Прежде чем представлять формулу для расчетов дисперсии, рассмотрим пример. Воспользуемся теми первичными данными, которые были приведены ранее и на основе которых вычислялась в предыдущем примере средняя величина. Мы видим, что все они разные и отличаются не только друг от друга, но и от средней величины. Меру их общего отличия от средней величины и характеризует дисперсия. Ее определяют для того, чтобы можно было отличать друг от друга величины, имеющие одинаковую среднюю, но разный разброс.
Представим себе другую, отличную от предыдущей выборку первичных значений, например такую: 5, 4, 5, 6, 5, 6, 5, 4, 5, 5. Легко убедиться в том, что ее средняя величина также равна 5,0. Но в данной выборке ее отдельные частные значения отличаются от средней гораздо меньше, чем в первой выборке. Выразим степень этого отличия при помощи дисперсии, которая определяется по следую щей формуле:
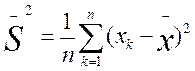
где ![]() —
выборочная дисперсия, или просто дисперсия;
—
выборочная дисперсия, или просто дисперсия;
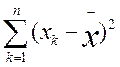 —
выражение, означающее, что для всех xk
от первого до последнего в данной выборке необходимо вычислить разности между частными и средними значениями, возвести эти разности в квадрат и просуммировать;
—
выражение, означающее, что для всех xk
от первого до последнего в данной выборке необходимо вычислить разности между частными и средними значениями, возвести эти разности в квадрат и просуммировать;
п — количество испытуемых в выборке или первичных значений, по которым вычисляется дисперсия.
Определим дисперсии для двух приведенных выше выборок частных значений, обозначив эти дисперсии соответственно индексами 1 и 2:
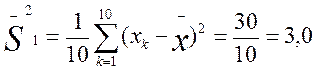
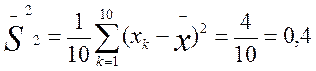
Мы видим, что дисперсия по второй выборке (0,4) значительно меньше дисперсии по первой выборке (3,0). Если бы не было дисперсии, то мы не в состоянии были бы различить данные выборки.
ВЫБОРОЧНОЕ ОТКЛОНЕНИЕ
Иногда вместо дисперсии для выявления разброса частных данных относительно средней используют производную от дисперсии величину, называемую выборочное отклонение. Оно равно квадратному корню, извлекаемому из дисперсии, и обозначается тем же
самым знаком, что и дисперсия, только без квадрата— 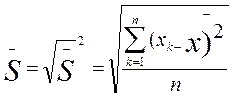
МЕДИАНА
Медианой называется значение изучаемого признака, которое делит выборку, упорядоченную по величине данного призна ка, пополам.
Справа и слева от медианы в упорядоченном ряду остается по одинаковому количеству признаков. Например, для выборки 2, 3,4, 4, 5, 6, 8, 7, 9 медианой будет значение 5, так как слева и справа от него остается по четыре показателя. Если ряд включает в себя четное число признаков, то медианой будет среднее, взятое как полусумма величин двух центральных значений ряда. Для следующего ряда 0, 1, 1, 2, 3, 4, 5, 5, 6, 7 медиана будет равна 3,5.
Знание медианы полезно для того, чтобы установить, является ли распределение частных значений изученного признака симметричным и приближающимся к так называемому нормаль ному распределению . Средняя и медиана для нормального распределения обычно совпадают или очень мало отличаются друг от друга.
Если выборочное распределение признаков нормально, то к нему можно применять методы вторичных статистичес ких расчетов, основанные на нормальном распределении данных. В противном случае этого делать нельзя, так как в расчеты могут вкрасться серьезные ошибки.
Если в книге по математической статистике, где описывается тот или иной метод статистической обработки, имеются указания на то, что его можно применять только к нормальному или близкому к нему распределению признаков, то необходимо неукоснительно следовать этому правилу и полученное эмпирическое распределение признаков проверять на нормальность .
Если такого указания нет, то статистика применима к любому распределению признаков. Приблизительно судить о том, является или не является полученное распределение близким к нормальному, можно, построив график распределения данных, похожий на те, которые представлены на рис. 72 . Если график оказывается более или менее симметричным, значит, к анализу данных можно применять статистики, предназначенные для нормального распределения. Во всяком случае, допустимая ошибка в расчетах в данном случае будет относительно небольшой.
Приблизительные картины симметричного и несимметричного распределений признаков показаны на рис. 72, где точками т1 и т2 на горизонтальной оси графика обозначены те величины признаков, которые соответствуют медианам, а х1 и х2 — те, которые соответствуют средним значениям.
|
|
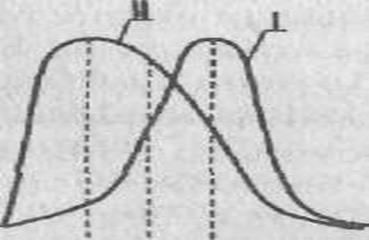
Рис. 72. Графики симметричного и несимметричного распределения признаков: 1 – симметричное распределение (все относящиеся к нему элементарные статистики обозначены с помощь индекса 1); 11 – несимметричное распределение (его первичные статистики отмечены на графике индексом 2).
МОДА
Мода еще одна элементарная математическая статистика и характеристика распределения опытных данных. Модой называют количественное значение исследуемого признака, наиболее часто встречающееся в выборке. На графиках, представленных на рис. 72, моде соответствуют самые верхние точки кривых, вернее, те значения этих точек, которые располагаются на горизонтальной оси.
Для симметричных распределений признаков, в том числе для нормального распределения, значения моды совпадают со значениям среднего и медианы. Для других типов распределений, несимметричных, это не характерно.
К примеру, в последовательности значений признаков 1, 2, 5, 2, 4, 2, 6, 7, 2 модой является значение 2, так как оно встречается чаще других значений — четыре раза.
ИНТЕРВАЛ
Иногда исходных частных первичных данных, которые подлежат статистической обработке, бывает довольно много, и они требуют проведения огромного количества элементарных арифметических операций. Для того чтобы сократить их число и вместе с тем сохранить нужную точность расчетов, иногда прибегают к замене исходной выборки частных эмпирических данных на интервалы.
Интервалом называется группа упорядоченных по ве личине значений признака, заменяемая в процессе расчетов сред ним значением.
Пример. Представим следующий ряд частных признаков: О, 1, 1, 2, 2, 3, 3, 3, 4, 4, 5, 5, 5, 5, 6, 6, 6, 7, 7, 8, 8, 8, 9, 9, 9, 10, 10, 11, 11, 11. Этот ряд включает в себя 30 значений.
Разобьем представленный ряд на шесть подгрупп по пять признаков в каждом.
*Пер вая подгруппа включит в себя первые пять цифр,
*вторая — следующие пять и т.д.
Вычислим средние значения для каждой из пяти образованных подгрупп чисел. Они соответственно будут равны 1,2; 3,4; 5,2; 6,8; 8,6; 10,6.
Таким образом, нам удалось свести исходный ряд, включающий тридцать значений, к ряду, содержащему всего шесть значений и представленному средними величинами. Это и будет интервальный ряд, а проведенная процедура — разделением исходного ряда на интервалы.
Теперь все статистические расчеты мы можем производить не с исходным рядом признаков, а с полученным интервальным рядом, и результаты в равной степени будут относиться к исходному ряду. Однако число производимых в ходе расчетов элементарных арифметических операций будет гораздо меньше, чем количество тех операций, которые с этой же целью пришлось бы проделать в отношении исходного ряда признаков.
На практике, составляя интервальный ряд, рекомендуется руководствоваться следующим правилом : если в исходном ряду признаков больше чем тридцать, то этот ряд целесообразно разделить на пять-шесть интервалов и в дальнейшем работать только с ними.
Для проверки сказанного проведем пробное вычисление среднего значения по приведенному выше ряду, составляющему тридцать чисел, и по ряду, включающему только интервальные средние значения. Полученные цифры с точностью до двух знаков после запятой будут соответственно равны 5,97 и 5,97, т.е. являются одинаковыми.
Вопрос 2 МЕТОДЫ ВТОРИЧНОЙ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ РЕЗУЛЬТАТОВ ЭКСПЕРИМЕНТА
С помощью вторичных методов статистической обработки экспериментальных данных непосредственно проверяются, доказываются или опровергаются гипотезы, связанные с экспериментом.
Эти методы, как правило, сложнее, чем методы первичной статистической обработки, и требуют от исследователя хорошей подготовки в области элементарной математики и статистики.
Обсуждаемую группу методов можно разделить на несколь ко подгрупп:
- Регрессионное исчисление.
- Методы сравнения между собой двух или нескольких элементарных статистик (средних, дисперсий и т.п.), относящихся к разным выборкам.
- Методы установления статистических взаимосвязей между переменными, например их корреляции друг с другом.
- Методы выявления внутренней статистической структуры эмпирических данных (например, факторный анализ).
Рассмотрим каждую из выделенных подгрупп методов вторичной статистической обработки на примерах.
1. Регрессионное исчисление — это метод математической статистики, позволяющий свести частные, разрозненные данные к некоторому линейному графику, приблизительно отражающему их внутреннюю взаимосвязь, и получить возможность по значению одной из переменных приблизительно оценивать вероятное значение другой переменной.
Воспользуемся для графического представления взаимосвязанных значений двух переменных х и у точками на графике (рис, 73). Поставим перед собой задачу: заменить точки на графике линией прямой регрессии, наилучшим образом представляющей взаимосвязь, существующую между данными переменными. Иными словами, задача заключается в том, чтобы через скопление точек, имеющихся на этом графике, провести прямую линию,
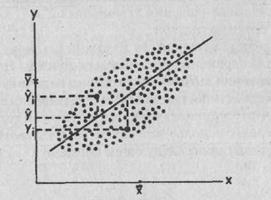
Рис. 73. Прямая регрессии Y no X. хср и уср — средние значения переменных. Отклонения отдельных значений от линии регрессии обозначены вертикальными пунктирными линиями. Величина у,-у является отклонением измеренного значения переменной yj от оценки, а величина у - у является отклонением оценки от среднего значения (Цит. по: Шерла К. Факторный анализ. М., 1980. С. 23).
пользуясь которой по значению одной из переменных, х или у, можно приблизительно судить о значении другой переменной. Для того чтобы решить эту задачу, необходимо правильно найти коэффициенты а и Ь в уравнении искомой прямой:
у = ах + b .
Это уравнение представляет прямую на графике и называется уравнением прямой регрессии.
Формулы для подсчета коэффициентов а и Ь являются следующими:
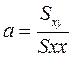
![]()
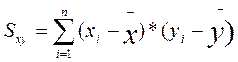

где х i у i - частные значения переменных X и Y , которым соответствуют точки на графике;
![]() —
средние значения тех же самых переменных;
—
средние значения тех же самых переменных;
п — число первичных значений или точек на графике.
Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, нередко используют t-критерий Стъюдента. Его основная формула выглядит следующим образом:
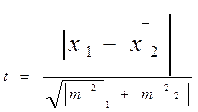
где
х1 — среднее значение переменной по одной выборке данных;
х2 — среднее значение переменной по другой выборке данных;
т1 и т2 — интегрированные показатели отклонений частных значений из двух сравниваемых выборок от соответствующих им средних величин.
т1 и т2 в свою очередь вычисляются по следующим формулам:
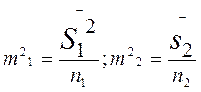
где ![]() — выборочная дисперсия первой переменной (по первой выборке);
— выборочная дисперсия первой переменной (по первой выборке);
![]() — выборочная дисперсия второй переменной (по второй выборке);
— выборочная дисперсия второй переменной (по второй выборке);
п] — число частных значений переменной в первой выборке;
п2 — число частных значений переменной по второй выборке.
После того как при помощи приведенной выше формулы вычислен показатель t , по таблице 32 для заданного числа степеней свободы, равного n 1 + п2 - 2, и избранной вероятности допустимой ошибки1 находят нужное табличное значение t и сравнива-
1 Степени свободы и вероятность допустимой ошибки — специальные математико-статистические термины, содержание которых мы здесь не будем рассматривать.
Таблица 32
Критические значения t-критерия Стъюдента
для заданного числа степеней свободы и вероятностей допустимых ошибок, равных 0,05; 0,01 и 0,001
| Число степеней свободы (n1 + n2 -2) |
Вероятность допустимой ошибки |
||
| 0,05 |
0,01 |
0,001 |
|
| Критические значения показателя t |
|||
| 4 |
2,78 |
5,60 |
8,61 |
| 5 |
2,58 |
4,03 |
6,87 |
| 6 |
2,45 |
3,71 |
5,96 |
| 7 |
2,37 |
3,50 |
5,41 |
| 8 |
2,31 |
3,36 |
5,04 |
| 9 |
2,26 |
3,25 |
4,78 |
| 10 |
2,23 |
3,17 |
4,59 |
| 11 |
2,20 |
3,11 |
4,44 |
| 12 |
2,18 |
3,05 |
4,32 |
| 13 |
2,16 |
3,01 |
4,22 |
| 14 |
2,14 |
2,98 |
4,14 |
| 15 |
2,13 |
2,96 |
4,07 |
| 16 |
2,12 |
2,92 |
4,02 |
| 17 |
2,11 |
2,90 |
3,97 |
| 18 |
2,10 |
2,88 |
3,92 |
| 19 |
2,09 |
2,86 |
3,88 |
| 20 |
2,09 |
2,85 |
3,85 |
| 21 |
2,08 |
2,83 |
3,82 |
| 22 |
2,07 |
2,82 |
3,79 |
| 23 |
2,07 |
2,81 |
3,77 |
| 24 |
2,06 |
2,80 |
3,75 |
| 25 |
2,06 |
2,79 |
3,73 |
| 26 |
2,06 |
2,78 |
3,71 |
| 27 |
2,05 |
2,77 |
3,69 |
| 28 |
2,05 |
2,76 |
3,67 |
| 29 |
2,05 |
2,76 |
3,66 |
| 30 |
2,04 |
2,75 |
3,65 |
| 40 |
2,02 |
2,70 |
3,55 |
| 50 |
2,01 |
2,68 |
3,50 |
| 60 |
2,00 |
2,66 |
3,46 |
| 80 |
1,99 |
2,64 |
3,42 |
| 100 |
1,98 |
2,63 |
3,39 |
ют с ними вычисленное значение t . Если вычисленное значение t больше или равно табличному, то делают вывод о том, что сравниваемые средние значения из двух выборок действительно статистически достоверно различаются с вероятностью допустимой ошибки, меньшей иди равной избранной. Рассмотрим процедуру вычисления t -критерия Стъюдента и определения на его основе разницы в средних величинах на конкретном примере.
Допустим, что имеются следующие две выборки экспериментальных данных: 2, 4, 5, 3, 2, 1, 3, 2, 6, 4 и 4, 5, 6, 4, 4, 3, 5, 2, 2, 7.
Средние значения по этим двум выборкам соответственно равны 3,2 и 4,2. Кажется, что они существенно друг от друга отличаются. Но так ли это и насколько статистически достоверны эти различия? На данный вопрос может точно ответить только статистический анализ с использованием описанного статистического критерия. Воспользуемся этим критерием.
Определим сначала выборочные дисперсии для двух сравниваемых выборок значений:
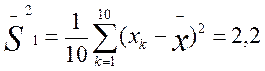
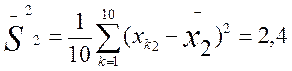
Поставим найденные значения дисперсий в формулу для под-
счета т и t и вычислим показатель t
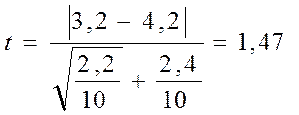
Сравним его значение с табличным для числа степеней свободы 10+10-2 = 18. Зададим вероятность допустимой ошибки, равной 0,05, и убедимся в том, что для данного числа степеней свободы и заданной вероятности допустимой ошибки значение t должно быть не меньше чем 2,10. У нас же этот показатель оказался равным 1,47, т.е. меньше табличного. Следовательно, гипотеза о том, что выборочные средние, равные в нашем случае 3,2 и 4,2, статистически достоверно отличаются друг от друга, не подтвердилась, хотя на первый взгляд казалось, что такие различия существуют.
Вероятность допустимой ошибки, равная и меньшая чем 0,05, считается достаточной для научно убедительных выводов. Чем меньше эта вероятность, тем точнее и убедительнее делаемые выводы. Например, избрав вероятность допустимой ошибки, равную 0,05, мы обеспечиваем точность расчетов 95% и допускаем ошибку, не превышающую 5%, а выбор вероятности допустимой ошибки 0,001 гарантирует точность расчетов, превышающую 99,99%, или ошибку, меньшую чем 0,01%.
Описанная методика сравнения средних величин по критерию Стъюдента в практике применяется тогда, когда необходимо, например, установить, удался или не удался эксперимент, оказал или не оказал он влияние на уровень развития того психологического качества, для изменения которого предназначался. Допустим, что в некотором учебном заведении вводится новая экспериментальная программа или методика обучения, рассчитанная на то, чтобы улучшить знания учащихся, повысить уровень их интеллектуального развития. В этом случае выясняется причинно-следственная связь между независимой переменной — программой или методикой и зависимой переменной — знаниями или уровнем интеллектуального развития. Соответствующая гипотеза гласит: «Введение новой учебной программы или методики обучения должно будет существенно улучшить знания или повысить уровень интеллектуального развития учащихся».
Предположим, что данный эксперимент проводится по схеме, предполагающей оценки зависимой переменной в начале и в конце эксперимента. Получив такие оценки и вычислив средние по всей изученной выборке испытуемых, мы можем воспользоваться критерием Стъюдента для точного установления наличия или отсутствия статистически достоверных различий между средними до и после эксперимента. Если окажется, что они действительно достоверно различаются, то можно будет сделать определенный вывод о том, что эксперимент удался. В противном случае нет убедительных оснований для такого вывода даже в том случае, если сами средние величины в начале и в конце эксперимента по своим абсолютным значениям различны.
Иногда в процессе проведения эксперимента возникает специальная задача сравнения не абсолютных средних значений некоторых величин до и после эксперимента, а частотных, например процентных, распределений данных. Допустим, что для экспериментального исследования была взята выборка из 100 учащихся и с ними проведен формирующий эксперимент. Предположим также, что до эксперимента 30 человек успевали на «удовлетворительно», 30 — на «хорошо», а остальные 40 — на «отлично». После эксперимента ситуация изменилась. Теперь на «удовлетворительно» успевают только 10 учащихся, на «хорошо» — 45 учащихся и на «отлично» — остальные 45 учащихся. Можно ли, опираясь на эти данные, утверждать, что формирующий эксперимент, направленный на улучшение успеваемости, удался?
Для ответа на данный вопрос можно воспользоваться статистикой, называемой 2 -критерий («хи-квадрат критерий»). Его формула выглядит следующим образом:
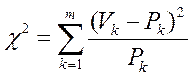
где Pk —. частоты результатов наблюдений до эксперимента;
Vk — частоты результатов наблюдений, сделанных после эксперимента;
т — общее число групп, на которые разделились результаты наблюдений.
Воспользуемся приведенным выше примером для того, чтобы показать, как работает хи-квадрат критерий. В данном примере переменная Рк принимает следующие значения: 30%, 30%, 40%, а переменная Vk — такие значения: 10%, 45%, 45%.
Подставим все эти значения в формулу для %2 и определим его величину:
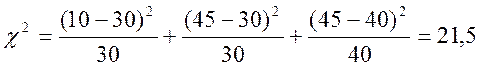
Воспользуемся теперь таблицей 33, где для заданного числа степеней свободы можно выяснить степень значимости образовавшихся различий до и после эксперимента в распределении оценок. Полученное нами значение 2 — 21,5 больше соответствующего табличного значения т - 1 = 2 степеней свободы, составляющего 13,82 при вероятности допустимой ошибки меньше чем 0,001. Следовательно, гипотеза о значимых изменениях, которые произошли в оценках учащихся в результате введения новой программы или новой методики обучения,
Таблица 33
Граничные (критические) значения c 2 -критерия,
соответствующие разным вероятностям допустимой ошибки
и разным степеням свободы
| Число степеней свободы (m-1) |
Вероятность допустимой ошибки |
||
| 0,05 |
0,01 |
0,001 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
3,84 5,99 7,81 9,49 11,07 12,59 14,07 15,51 16,92 18,31 19,68 21,03 22,36 23,68 25,00 |
6,64 9,21 11,34 13,28 15,09 16,81 18,48 20,09 21,67 23,21 24.72 26,05 27,69 29,14 30,58 |
10,83 13,82 16,27 18,46 20,52 22,46 24,32 26,12 27.88 29,59 31,26 32,91 34,53 36,12 37,70 |
экспериментально подтвердилась: успеваемость значительно улучшилась, и это мы можем утверждать, допуская ошибку, не превышающую 0,001%.
Иногда в психолого-педагогическом эксперименте возникает необходимость сравнить дисперсии двух выборок для того, чтобы решить, различаются ли эти дисперсии между собой. Допустим, что проводится эксперимент, в котором проверяется гипотеза о том, что одна из двух предлагаемых программ или методик обучения обеспечивает одинаково успешное усвоение знаний учащимися с разными способностями, а другая программа или методика этим свойством не обладает. Демонстрацией справедливости такой гипотезы было бы доказательство того, что индивидуальный разброс оценок учащихся по одной программе или методике больше (или меньше), чем индивидуальный разброс оценок по другой программе или методике.
Критерий Фишера
Подобного рода задачи решаются, в частности, при помощи критерия Фишера. Его формула выглядит следующим образом:
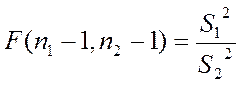
где n 1 — количество значения признака в первой из сравниваемых выборок;
п2 — количество значений признака во второй из сравниваемых выборок;
(п 1 — 1, п2 — 1) — число степеней свободы;
![]() — дисперсия по первой выборке;
— дисперсия по первой выборке;
![]() — дисперсия по второй выборке.
— дисперсия по второй выборке.
Вычисленное с помощью этой формулы значение F-критерия сравнивается с табличным (табл. 34), и если оно превосходит табличное для избранной вероятности допустимой ошибки и заданного числа степеней свободы, то делается вывод о том, что гипотеза о различиях в дисперсиях подтверждается. В противоположном случае такая гипотеза отвергается и дисперсии считаются одинаковыми1 .
Таблица 34
Граничные значения F-критерия для вероятности допустимой ошибки 0,05 и числа степеней свободы n1 и n2
| n2 n1 |
3 |
4 |
5 |
6 |
8 |
12 |
16 |
24 |
50 |
| 3 |
9,28 |
9,91 |
9,01 |
8,94 |
8,84 |
8,74 |
8,69 |
8,64 |
8,58 |
| 4 |
6,59 |
6,39 |
6,26 |
6,16 |
6,04 |
5,91 |
5,84 |
5,77 |
5,70 |
| 5 |
5,41 |
5,19 |
5,05 |
4,95 |
4,82 |
4,68 |
4,60 |
4,58 |
4,44 |
| 6 |
4,76 |
4,53 |
4,39 |
4,28 |
4,15 |
4,00 |
3,92 |
3,84 |
3,75 |
| 8 |
4,07 |
3,84 |
3,69 |
3,58 |
3,44 |
3,28 |
3,20 |
3,12 |
3,03 |
| 12 |
3,49 |
3,26 |
3,11 |
3,00 |
2,85 |
2,69 |
2,60 |
2,50 |
2,40 |
| 16 |
3,24 |
3,0 |
2,85 |
2,74 |
2,59 |
2,42 |
2,33 |
2,24 |
2,13 |
| 24 |
3,01 |
2,78 |
2,62 |
2,51 |
2,36 |
2,18 |
2,09 |
1,98 |
1,86 |
| 50 |
2,79 |
2,56 |
2,40 |
2,29 |
2,13 |
1,95 |
1,85 |
1,74 |
1,60 |
1. Если отношение выборочных дисперсий в формуле F-критерия оказывается меньше единицы, то числитель и знаменатель в этой формуле меняют местами и вновь определяют значения критерия.
Примечание. Таблица для граничных значений F-распределения приведена в сокращенном виде. Полностью ее можно найти в справочниках по математической статистике, в частности в тех, которые даны в списке дополнительной литературы представленной в Теме № 1..
Пример.
Сравним дисперсии следующих двух рядов цифр с целью определения статистически достоверных различий между ними.
Первый ряд: 4,6,5,7,3,4,5,6.
Второй ряд: 2,7,3,6,1,8,4,5.
Средние значения для двух этих рядов соответственно равны: 5,0 и 4,5. Их дисперсии составляют: 1,5 и 5,25. Частное от деления большей дисперсии на меньшую равно 3,5. Это и есть искомый показатель F . Сравнивая его с табличным граничным значением 3,44, приходим к выводу о том, что дисперсии двух сопоставляемых выборок действительно отличаются друг от друга на уровне значимости более 95% или с вероятностью допустимой ошибки не более 0,05%.
МЕТОД КОРЕЛЛЯЦИЙ
Следующий метод вторичной статистической обработки, посредством которого выясняется связь или прямая зависимость между двумя рядами экспериментальных данных, носит название метод корреляций . Он показывает, каким образом одно явление влияет на другое или связано с ним в своей динамике. Подобного рода зависимости существуют, к примеру, между величинами, находящимися в причинно-следственных связях друг с другом. Если выясняется, что два явления статистически достоверно коррелируют друг с другом и если при этом есть уверенность в том, что одно из них может выступать в качестве причины другого явления, то отсюда определенно следует вывод о наличии между ними причинно-следственной зависимости.
Имеется несколько разновидностей данного метода:
*линейный,
*ранговый,
*парный и
*множественный.
Линейный корреляционный анализ позволяет устанавливать прямые связи между переменными величинами по их абсолютным значениям. Эти связи графически выражаются прямой линией, отсюда название «линейный».
Ранговая корреляция определяет зависимость не между абсолютными значениями переменных, а между порядковыми местами, или рангами, занимаемыми ими в упорядоченном по величине ряду.
Парный корреляционный анализ включает изучение корреляционных зависимостей только между парами переменных, а множественный , или многомерный, — между многими переменными одновременно.
Распространенной в прикладной статистике формой многомерного корреляционного анализа является факторный анализ.
На рис. 74 в виде множества точек представлены различные виды зависимостей между двумя переменными X и У (различные поля корреляций между ними).
На фрагменте рис. 74, отмеченном буквой А, точки случайным образом разбросаны по координатной плоскости. Здесь по величине X нельзя делать какие-либо определенные выводы о величине Y . Если в данном случае подсчитать коэффициент корреляции, то он будет равен 0, что свидетельствует о том, что достоверная связь между X и У отсутствует (она может отсутствовать и тогда, когда коэффициент корреляции не равен 0, но близок к нему по величине).
На фрагменте Б рисунка все точки лежат на одной прямой, и каждому отдельному значению переменной X можно поставить в соответствие одно и только одно значение переменной У, причем, чем больше X , тем больше У. Такая связь между переменными X и У называется прямой, и если это прямая, соответствующая уравнению регрессии, то связанный с ней коэффициент корреляции будет равен +1. (Заметим, что в жизни такие случаи практически не встречаются; коэффициент корреляции почти никогда не достигает величины единицы.)
На фрагменте В рисунка коэффициент корреляции также будет равен единице, но с отрицательным знаком: -1. Это означает обратную зависимость между переменными X и У, т.е., чем больше одна из них, тем меньше другая.
На фрагменте Г рисунка точки также разбросаны не случайно, они имеют тенденцию группироваться в определенном направлении. Это направление приближенно может быть представлено уравнением прямой регрессии.
Такая же особенность, но с противоположным знаком, характерна для фрагмента Д . Соответствующие этим двум фрагментам коэффициенты корреляции приблизительно будут равны +0,50 и -0,30. Заметим, что крутизна графика, или линии регрессии, не оказывает влияния на величину коэффициента корреляции.
|
|
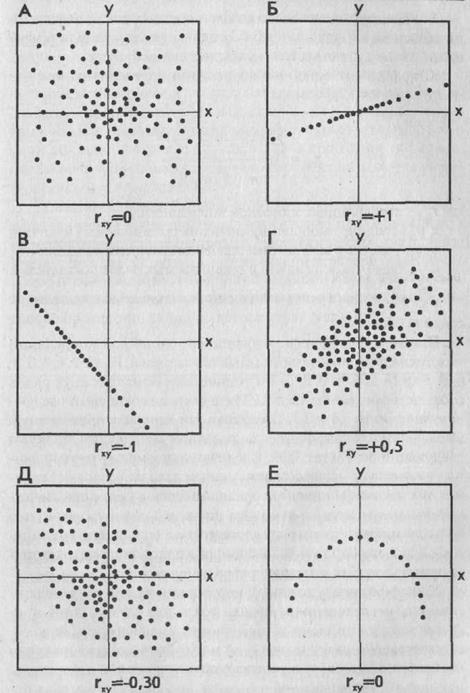
Рис. 74. Схематическое представление различных корреляционных зависимостей с соответствующими значениями коэффициента линейной корреляции (цит. по: Иберла К. Факторный анализ. М,, 1980).
Наконец, фрагмент Е дает коэффициент корреляции, равный или близкий к 0, так как в данном случае связь между переменными хотя и существует, но не является линейной.
Коэффициент линейной корреляции определяется при помощи следующей формулы:
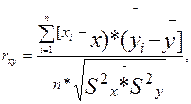
где rxy — коэффициент линейной корреляции;
х, у - средние выборочные значения сравниваемых величин;
х i ,у i — частные выборочные значения сравниваемых величин;
п — общее число величин в сравниваемых рядах показателей;
![]()
![]() —
дисперсии, отклонения сравниваемых величин от
—
дисперсии, отклонения сравниваемых величин от
средних значений.
Пример. Определим коэффициент линейной корреляции между следующими двумя рядами показателей.
Ряд 1: 2, 4, 4, 5, 3, б, 8.
Ряд II: 2, 5, 4, 6, 2, 5, 7.
Средние значения этих двух рядов соответственно равны 4,6 и 4,4.
Их дисперсии составляют следующие величины: 3,4 и 3,1. Подставив эти данные в приведенную выше формулу коэффициента линейной корреляции, получим следующий результат: 0,92. Следовательно, между рядами данных существует значимая связь, причем довольно явно выраженная, так как коэффициент корреляции близок к единице. Действительно, взглянув на эти ряды цифр, мы обнаруживаем, что большей цифре в одном ряду соответствует большая цифра в другом ряду и, наоборот, меньшей цифре в одном ряду соответствует примерно такая же малая цифра в другом ряду.
К коэффициенту ранговой корреляции в психолого-педагогических исследованиях обращаются в том случае, когда признаки, между которыми устанавливается зависимость, являются качественно различными и не могут быть достаточно точно оценены при помощи так называемой интервальной измерительной шкалы.
Интервальной называют такую шкалу, которая позволяет оценивать расстояния между ее значениями и судить о том, какое из них больше и насколько больше другого.
Напри мер , линейка, с помощью которой оцениваются и сравниваются длины объектов, является интервальной шкалой, так как, пользуясь ею, мы можем утверждать, что расстояние между двумя и шестью сантиметрами в два раза больше, чем расстояние между шестью и восемью сантиметрами. Если же, пользуясь некоторым измерительным инструментом, мы можем только утверждать, что одни показатели больше других, но не в состоянии сказать на сколько, то такой измерительный инструмент называется не интервальным, а порядковым .
Большинство показателей, которые получают в психолого-педагогических исследованиях, относятся к порядковым , а не к интервальным шкалам (например, оценки типа «да», «нет», «скорее нет, чем да» и другие, которые можно переводить в баллы), поэтому коэффициент линейной корреляции к ним неприменим . В этом случае обращаются к использованию коэффициента ранговой корреляции, формула которого следующая:
где Rs — коэффициент ранговой корреляции по Спирмену;
di — разница между рангами показателей одних и тех же испытуемых в упорядоченных рядах;
п — число испытуемых или цифровых данных (рангов) в коррелируемых рядах.
Пример. Допустим, что экспериментатора интересует, влияет ли интерес учащихся к учебному предмету на их успеваемость. Предположим, что с помощью некоторой психодиагностической методики удалось измерить величину интереса к учению и выразить его для десяти учащихся в следующих цифрах: 5, 6, 7, 8, 2, 4, 8, 7, 2, 9. Допустим также, что при помощи другой методики были определены средние оценки этих же учащихся по данному предмету, оказавшиеся соответственно равными: 3,2; 4,0; 4,1; 4,2; 2,5; 5,0; 3,0; 4,8; 4,6; 2,4.
Упорядочим оба ряда оценок по величине цифр и припишем каждому из учащихся по два ранга; один из них указывает на то, какое место среди остальных данных ученик занимает по успеваемости, а другой — на то, какое место среди них же он занимает по интересу к учебному предмету. Ниже приведены ряды цифр, два из которых (первый и третий) представляют исходные данные, а два других (второй и четвертый) — соответствующие ранги1 :
| 2-1,5 |
2,4-1 |
| 2-1,5 |
2,5-2 |
| 4-3 |
3,0-3 |
| 5-4 |
3,2-4 |
| 6-5 |
4,0-5 |
| 7-6,5 |
4,1-6 |
| 7-6,5 |
4,2-7 |
| 8-8,5 |
4,6-8 |
| 9-10 |
5,0-10 |
Определив сумму квадратов различий в рангах (d2 i ) и подставив нужное значение в числитель формулы, получаем, что коэффициент ранговой корреляции равен 0,97, т.е. достаточно высок, что и говорит о том, что между интересом к учебному предмету и успеваемостью учащихся действительно существует статистически достоверная зависимость.
Однако по абсолютным значениям коэффициентов корреляции не всегда можно делать однозначные выводы о том, являются ли они значимыми, т.е. достоверно свидетельствуют о существовании зависимости между сравниваемыми переменными. Может случиться так, что коэффициент корреляции, равный 0,50, не будет достоверным, а коэффициент корреляции, составивший 0,30, — достоверным. Многое в решении этого вопроса зависит от того, сколько показателей было в коррелируемых друг с другом рядах признаков: чем больше таких показателей, тем меньшим по величине может быть статистически достоверный коэффициент корреляции.
В табл. 35 представлены критические значения коэффициентов корреляции для различных степеней свободы.
1 Если исходные данные, которые ранжируются, одинаковы, то и их ранги также будут одинаковыми. Они получаются путем суммирования и деления пополам тех рангов, которые соответствуют этим данным.
Таблица 35
Критические значения коэффициентов корреляции
для различных степеней свободы ( n - 2) и разных вероятностей
допустимых ошибок
| Число степеней свободы |
Уровень значимости |
||
| 0,05 |
0,01 |
0,001 |
|
| 2 |
0,9500 |
0,9900 |
0,9900 |
| 3 |
8783 |
9587 |
9911 |
| 4 |
8114 |
9172 |
9741 |
| 5 |
0,7545 |
0,8745 |
0,9509 |
| 6 |
7067 |
8343 |
9249 |
| 7 |
6664 |
7977 |
8983 |
| 8 |
6319 |
7646 |
8721 |
| 9 |
6021 |
7348 |
8471 |
| 10 |
0,5760 |
0,7079 |
0,8233 |
| И |
5529 |
6833 |
8010 |
| 12 |
5324 |
6614 |
7800 |
| 13 |
5139 |
6411 |
7604 |
| 14 |
4973 |
6226 |
7419 |
| 15 |
0,4821 |
0,6055 |
0,7247 |
| 16 |
4683 |
5897 |
7084 |
| 17 |
4555 |
5751 |
6932 |
| 18 |
4438 |
5614 |
6788 |
| 19 |
4329 |
5487 |
6625 |
| 20 |
0,4227 |
0,5368 |
0,6524 |
| 21 |
4132 |
5256 |
6402 |
| 22 |
4044 |
5151 |
6287 |
| 23 |
3961 |
5052 |
6177 |
| 24 |
3882 |
4958 |
6073 |
| 25 |
0,3809 |
0,4869 |
0,5974 |
| 26 |
3739 |
4785 |
5880 |
| 27 |
3673 |
4705 |
5790 |
| 28 |
3610 |
4629 |
5703 |
| 29 |
3550 |
4556 |
5620 |
| 30 |
0,3494 |
0,4487 |
0,5541 |
| 31 |
3440 |
4421 |
5465 |
| 32 |
3388 |
4357 |
5392 |
| 33 |
0,3338 |
0,4297 |
0,5322 |
| 34 |
3291 |
4238 |
5255 |
| 35 |
0,3246 |
0,4182 |
0,5189 |
| 36 |
3202 |
4128 |
5126 |
| 37 |
3160 |
4076 |
5066 |
| 38 |
3120 |
4026 |
5007 |
| 39 |
3081 |
3978 |
4951 |
| 40 |
0,3044 |
0,3932 |
0,4896 |
(В данном случае степенью свободы будет число, равное п — 2, где п — количество данных в коррелируемых рядах.) Заметим, что значимость коэффициента корреляции зависит и от заданного уровня значимости или принятой вероятности допустимой ошибки в расчетах. Если, к примеру, коррелируется друг с другом два ряда цифр по 10 единиц в каждом и получен коэффициент корреляции между ними, равный 0,65, то он будет значимым на уровне 0,95 (он больше критического табличного значения, составляющего 0,6319 для вероятности допустимой ошибки 0,05, и меньше критического значения 0,7646 для вероятности допустимой ошибки 0,01).
Метод множественных корреляций в отличие от метода парных корреляций позволяет выявить общую структуру корреляционных зависимостей, существующих внутри многомерного экспериментального материала, включающего более двух переменных, и представить эти корреляционные зависимости в виде некоторой системы.
ФАКТОРНЫЙ АНАЛИЗ
Один из наиболее распространенных вариантов этого метода — факторный анализ — позволяет определить совокупность внутренних взаимосвязей, возможных причинно-следственных связей, существующих в экспериментальном материале. В результате факторного анализа обнаруживаются так называемые факторы — причины, объясняющие множество частных (парных) корреляционных зависимостей.
Фактор — математико-статистическое понятие. Будучи переведенным на язык психологии (эта процедура называется содержательной или психологической интерпретацией факторов), он становится психологическим понятием. Например, в известном 16-факторном личностном тесте Р. Кеттела, который подробно рассматривался в первой части книги, каждый фактор взаимно однозначно связан с определенными чертами личности человека.
С помощью выявленных факторов объясняют взаимозависимость психологических явлений. Поясним сказанное на примере. Допустим, что в некотором психолого-педагогическом эксперименте изучалось взаимовлияние таких переменных, как характер, способности, потребности и успеваемость учащихся. Предположим далее, что, оценив каждую из этих переменных у достаточно представительной выборки испытуемых и подсчитав коэффициенты парных корреляций между всевозможными парами данных переменных, мы получили следующую матрицу интеркорреляций (в ней справа и сверху цифрами обозначены в перечисленном выше порядке изученные в эксперименте переменные, а внутри самого квадрата показаны их корреляции друг с другом; поскольку всевозможных пар в данном случае меньше, чем клеток в матрице, то заполнена только верхняя часть матрицы, расположенная выше ее главной диагонали).
Анализ корреляционной матрицы показывает, что переменная 1 (характер) значимо коррелирует с переменными 2 и 3 (способности и потребности). Переменная 2 (способности) достоверно коррелирует с переменной 3 (потребности), а переменная 3 (потребности) — с переменной 4 (успеваемость). Фактически из шести имеющихся в матрице коэффициентов корреляции четыре являются достаточно высокими и, если предположить, что они определялись на совокупности испытуемых, превышающей 10 человек, — значимыми.
| 1 |
2 |
3 |
4 |
| 1 |
0,82 |
0,50 |
0,04 |
| 2 |
0,40 |
0,24 |
|
| 3 |
0,75 |
||
| 4 |
Зададим некоторое правило умножения столбцов цифр на строки матрицы: каждая цифра столбца последовательно умножается на каждую цифру строки и результаты парных произведений записываются в строку аналогичной матрицы. Пример: если по этому правилу умножить друг на друга три цифры столбца и строки, представленные в левой части матричного равенства, то получим матрицу, находящуюся в правой части этого же равенства:
| 2 |
X |
2 |
3 |
4 |
= |
4 |
6 |
8 |
| 3 |
6 |
9 |
12 |
|||||
| 4 |
8 |
12 |
16 |
Задача факторного анализа по отношению к только что рассмотренной является как бы противоположной. Она сводится к тому, чтобы по уже имеющейся матрице парных корреляций, аналогичной представленной в правой части показанного выше матричного равенства, отыскать одинаковые по включенным в них цифрам столбец и строку, умножение которых друг на друга по заданному правилу порождает корреляционную матрицу.
Иллюстрация:
| Х1 |
х |
Х1 |
Х2 |
Х3 |
Х4 |
= |
0,16 |
0,50 |
0,30 |
| Х2 |
0,16 |
0,40 |
0,24 |
||||||
| Х3 |
0,50 |
0,40 |
0,75 |
||||||
| Х4 |
0,30 |
0,24 |
0,75 |
Здесь х1 х2 , x3 и х4 — искомые числа.
Для их точного и быстрого определения существуют специальные математические процедуры и программы для ЭВМ.
Допустим, что мы уже нашли эти цифры: x1 = 0,45, х2 =,36 х3 = 1,12, х4 = 0,67. Совокупность найденных цифр и называется фактором, а сами эти цифры — факторными весами или нагрузками.
Эти цифры соответствуют тем психологическим переменным, между которыми вычислялись парные корреляции,
х1 — характер,
х2 — способности,
х3 — потребности,
х4 — успеваемость.
Поскольку наблюдаемые в эксперименте корреляции между переменными можно рассматривать как следствие влияния на них общих причин — факторов, а факторы интерпретируются в психологических терминах, мы можем теперь от факторов перейти к содержательной психологической интерпретации обнаруженных статистических закономерностей. Фактор содержит в себе ту же самую информацию, что и вся корреляционная матрица, а факторные нагрузки соответствуют коэффициентам корреляции. В нашем примере х3 (потребности) имеет наибольшую факторную нагрузку (1,12), а х2 (способности) — наименьшую (0,36).
Следовательно, наиболее значимой причиной, влияющей на все остальные психологические переменные, в нашем случае являются потребности, а наименее значимой — способности. Из корреляционной матрицы видно, что связи переменной х 3 со всеми остальными являются наиболее сильными (от 0,40 до 0,75), а корреляции переменной х2 — самыми слабыми (от 0,16 до 0,40).
Чаще всего в итоге факторного анализа определяется не один, а несколько факторов, по-разному объясняющих матрицу интеркорреляций переменных. В таком случае факторы делят на генеральные, общие и единичные.
Генеральными называются факторы, все факторные нагрузки которых значительно отличаются от нуля (нуль нагрузки свидетельствует о том, что данная переменная никак не связана с остальными и не оказывает на них никакого влияния в жизни).
Общие — это факторы, у которых часть факторных нагрузок отлична от нуля.
Единичные — это факторы, в которых существенно отличается от нуля только одна из нагрузок. На рис. 75 схематически представлена структура факторного отображения переменных в факторах различной степени общности.
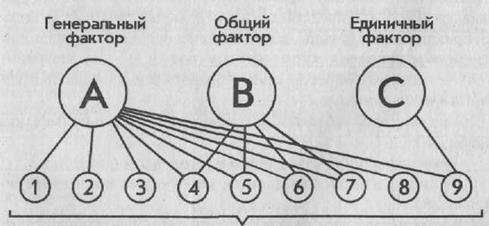
Переменные, между которыми определены в результате эксперимента парные корреляционные зависимости
Рис. 75 . Структура факторного отображения взаимосвязей переменных.
Отрезки, соединяющие факторы с переменными, указывают на высокие
факторные нагрузки
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
1. Готтсданкер Р.
Основы психологического эксперимента. М:
МГУ, 1982. - 464 с. (Корреляционные исследования: 378-424.)
2. Закс Л. Статистическое оценивание. М., 1976.
(Что такое статистика: 37-39. Нормальная кривая и нормальное распределение: 63-71. Арифметическое среднее и стандартное отклонение: 72-79. Медиана и мода: 91-94. Распределение Стъюдента: 129-136. Хи-квадрат распределение: 136-150. Распределение Фишера: 150-153. Сравнение двух выборочных дисперсий из нормальных совокупностей: 241-245. Сравнение двух выборочных средних из нормальных совокупностей: 245-270. Проверка распределений по хи-квадрат критерию согласия: 295-296. Коэффициент ранговой корреляции Спирмена: 368-372. Оценивание прямой регрессии: 371-381. Проверка равенства нескольких дисперсий: 448-453).
3. Кулагин Б.В.
Основы профессиональной психодиагностики. Л.,
1984.-216 с. (Измерение в психодиагностике: 13-20. Корреляция и факторный анализ: 20-33.)
4. Фресс П., Пиаже Ж. Экспериментальная психология. Вып. I и П. М., 1966. (Измерение в психологии: 197-229. Проблема надежности измерения: 229-231).
5. Практикум по общей психологии / Под ред. А.И. Щербакова. М., 1990. -287 с. [Методы психологии (с элементами математической статистики): 20-39].
6. Психодиагностические методы (в комплексном лонгитюдном
исследовании студентов) / Под ред. А.А. Бодалева, М.Д. Дворяшиной, И.М. Палея. Л., 1976. - 248 с. (Основные математические процедуры психодиагностического исследования: 35-51.)
Курс: «Математические методы в психологии»
(Для студентов психологов и социальных работников)
Лекция № 3
ОСНОВНЫЕ ПОНЯТИЯ, ИСПОЛЬЗУЕМЫЕ В МАТЕМАТИЧЕСКОЙ ОБРАБОТКЕ ПСИХОЛОГИЧЕСКИХ ДАННЫХ
Учебные вопросы:
1.Признаки и переменные.
2.Шкалы измерения.
3.Распределение признака. Параметры распределения.
4.Статистические гипотезы.
5.Статистические критерии.
6.Уровни статистической значимости.
7.Мощность критериев.
8.Классификация задач и методов их решения.
9.Принятие решения о выборе метода математической обработки.
Вопрос 1. Признаки и переменные
Признаки и переменные - это измеряемые психологические явления. Такими явлениями могут быть время решения задачи, количеств допущенных ошибок, уровень тревожности, показатель интеллектуальной лабильности, интенсивность агрессивных реакций, угол поворот корпуса в беседе, показатель социометрического статуса и множеств других переменных.
Понятия признака и переменной могут использоваться как взаимозаменяемые. Они являются наиболее общими. Иногда вместо ни используются понятия показателя или уровня, например, уровень настойчивости, показатель вербального интеллекта и др. Понятия показа теля и уровня указывают на то, что признак может быть измерен количественно, так как к ним применимы определения высокий ил низкий, например, высокий уровень интеллекта, низкие показатели тревожности и др.
Психологические переменные являются случайными величинами поскольку заранее неизвестно, какое именно значение они примут.
Математическая обработка - это оперирование со значениям признака, полученными у испытуемых в психологическом исследовании. Такие индивидуальные результаты называют также наблюдениями наблюдаемыми значениями, вариантами, датами, индивидуальны ми показателями и др. В психологии чаще всего используются термины наблюдение или наблюдаемое значение.
Значения признака определяются при помощи специальных шкал измерения.
Вопрос 2.Шкалы измерения
Измерение - это приписывание числовых форм объектам или событиям в соответствии с определенными правилами (Стивенс С, 1960, с.60). С.Стивенсом предложена классификация из 4 типов шкал измерения:
1) номинативная, или номинальная, или шкала наименований;
2) порядковая, или ординальная, шкала;
3) интервальная, или шкала равных интервалов;
4) шкала равных отношений.
Номинативная шкала - это шкала, классифицирующая по названию: потеп (лат.) - имя, название. Название же не измеряется количественно, оно лишь позволяет отличить один объект от другого или одного субъекта от другого. Номинативная шкала - это способ классификации объектов или субъектов, распределения их по ячейкам классификации.
Простейший случай номинативной шкалы - дихотомическая шкала, состоящая всего лишь из двух ячеек, например: имеет братьев и сестер - единственный ребенок в семье; иностранец - соотечественник; проголосовал за - проголосовал против и т.п.
Признак, который измеряется по дихотомической шкале наименований, называется альтернативным. Он может принимать всего два значения. При этом исследователь зачастую заинтересован в одном из них, и тогда он говорит, что признак проявился, если тот принял интересующее его значение, и что признак не проявился, если он принял противоположное значение. Например: Признак леворукости проявился у 8 испытуемых из 20. В принципе номинативная шкала может состоять из ячеек признак проявился - признак не проявился.
Более сложный вариант номинативной шкалы - классификация из трех и более ячеек, например: экстрапунитивные - интрапунитивные - импунитивные реакции или выбор кандидатуры А - кандидатуры Б - кандидатуры В - кандидатуры Г или старший - средний - младший -единственный ребенок в семье и др.
Расклассифицировав все объекты, реакции или всех испытуемых по ячейкам классификации, мы получаем возможность от наименований перейти к числам, подсчитав количество наблюдений в каждой из ячеек.
Как уже указывалось, наблюдение - это одна зарегистрированная реакция, один совершенный выбор, одно осуществленное действие или результат одного испытуемого.
Допустим, мы определим, что кандидатуру А выбрали 7 испытуемых, кандидатуру Б - 11, кандидатуру В - 28, а кандидатуру Г - всего 1. Теперь мы можем оперировать этими числами, представляющими собой частоты встречаемости разных наименований, то есть частоты принятия признаком выбор каждого из 4 возможных значении. Далее мы можем сопоставить полученное распределение частот с равномерным или каким-то иным распределением.
Таким образом , номинативная шкала позволяет нам подсчитывать частоты встречаемости разных наименований, или значений признака, и затем работать с этими частотами с помощью математических методов.
Единица измерения, которой мы при этом оперируем - количество наблюдений (испытуемых, реакций, выборов и т. п.), или частота. Точнее, единица измерения - это одно наблюдение. Такие данные могут быть обработаны с помощью метода 2 , биномиального критерия m и углового преобразования Фишера *.
Порядковая шкала - это шкала, классифицирующая по принципу больше - меньше. Если в шкале наименований было безразлично, в каком порядке мы расположим классификационные ячейки, то в порядковой шкале они образуют последовательность от ячейки самое малое значение к ячейке самое большое значение (или наоборот). Ячейки теперь уместнее называть классами, поскольку по отношению к классам употребимы определения низкий, средний и высокий класс, или 1-й, 2-й, 3-й класс, и т.д.
В порядковой шкале должно быть не менее трех классов, например положительная реакция - нейтральная реакция - отрицательная реакция или подходит для занятия вакантной должности - подходит с оговорками - не подходит и т. п.
В порядковой шкале мы не знаем истинного расстояния между классами, а знаем лишь, что они образуют последовательность. Например, классы подходит для занятия вакантной должности и подходит с оговорками могут быть реально ближе друг к другу, чем класс подходит с оговорками к классу не подходит.
От классов легко перейти к числам, если мы условимся считать, что низший класс получает ранг 1, средний класс - ранг 2, а высший класс - ранг 3, или наоборот. Чем больше классов в шкале, тем больше. У нас возможностей для математической обработки полученных данных и проверки статистических гипотез.
Например, мы можем оценить различия между двумя выборками испытуемых по преобладанию у них более высоких или более низких рангов или подсчитать коэффициент ранговой корреляции между двумя переменными, измеренными в порядковой шкале, допустим, между оценками профессиональной компетентности руководителя, данными ему разными экспертами.
Все психологические методы, использующие ранжирование, построены на применении шкалы порядка. Если испытуемому предлагается упорядочить 18 ценностей по степени их значимости для него, проранжировать список личностных качеств социального работника или 10 претендентов на эту должность по степени их профессиональной пригодности, то во всех этих случаях испытуемый совершает так называемое принудительное ранжирование, при котором количество рангов соответствует количеству ранжируемых субъектов или объектов (ценностей, качеств и т.п.).
Независимо от того, приписываем ли мы каждому качеству или испытуемому один из 3-4 рангов или совершаем процедуру принудительного ранжирования, мы получаем в обоих случаях ряды значении, измеренные по порядковой шкале. Правда, если у нас всего 3 возможных класса и, следовательно, 3 ранга, и при этом, скажем, 20 ранжируемых испытуемых, то некоторые из них неизбежно получат одинаковые ранги. Все многообразие жизни не может уместиться в 3 градации, поэтому в один и тот же класс могут попасть люди, достаточно серьезно различающиеся между собой. С другой стороны, принудительное ранжирование, то есть образование последовательности из многих испытуемых, может искусственно преувеличивать различия между людьми. Кроме того, данные, полученные в разных группах, могут оказаться несопоставимыми, так как группы могут изначально различаться по уровню развития исследуемого качества, и испытуемый, получивший в одной группе высший ранг, в другой получил бы всего лишь средний, и т.п.
Выход из положения может быть найден, если задавать достаточно дробную классификационную систему, скажем, из 10 классов, или градаций, признака. В сущности, подавляющее большинство психологических методик, использующих экспертную оценку, построено на измерении одним и тем же аршином из 10, 20 или даже 100 градаций разных испытуемых в разных выборках.
Итак , единица измерения в шкале порядка - расстояние в 1 класс или в 1 ранг, при этом расстояние между классами и рангами может быть разным (оно нам неизвестно). К данным, полученным по порядковой шкале, применимы все описанные в данной книге критерии и методы.
Интервальная шкала - это шкала, классифицирующая по принципу больше на определенное количество единиц - меньше на определенное количество единиц. Каждое из возможных значений признака отстоит от другого на равном расстоянии.
Можно предположить, что если мы измеряем время решения задачи в секундах, то это уже явно шкала интервалов. Однако на самом деле это не так, поскольку психологически различие в 20 секунд между испытуемым А и Б может быть отнюдь не равно различию в 20 секунд между испытуемыми Б и Г, если испытуемый А решил задачу за 2 секунды, Б - за 22, В - за 222, а Г - за 242.
Аналогичным образом, каждая секунда после истечения полутора минут в опыте с измерением мышечного волевого усилия на динамометре с подвижной стрелкой, по цене, может быть, равна 10 или даже более секундам в первые полминуты опыта. Одна секунда за год идет - так сформулировал это однажды один испытуемый.
Попытки измерять психологические явления в физических единицах - волю в секундах, способности в сантиметрах, а ощущение собственной недостаточности - в миллиметрах и т. п., конечно, понятны, ведь все-таки это измерения в единицах объективно существующего времени и пространства. Однако ни один опытный исследователь при этом не обольщает себя мыслью, что он совершает измерения по психологической интервальной шкале. Эти измерения принадлежат по-прежнему к шкале порядка, нравится нам это или нет (Стивенс С, 1960, с.56; Паповян С.С., 1983, с.63; Михеев В.И., 1986, с.28).
Мы можем с определенной долей уверенности утверждать лишь, что испытуемый А решил задачу быстрее Б, Б быстрее В, а В быстрее Г.
Аналогичным образом, значения, полученные испытуемыми в баллах по любой нестандартизованной методике, оказываются измеренными лишь по шкале порядка. На самом деле равно интервальными можно считать лишь шкалы в единицах стандартного отклонения и процентильные шкалы, и то лишь при условии, что распределение значений в стандартизующей выборке было нормальным (Бурлачук Л. Ф., Морозов С. М., 1989, с. 163. с. 101).
Принцип построения большинства интервальных шкал построен на известном правиле трех сигм: примерно 97,7-97,8% всех значений признака при нормальном его распределении укладываются в диапазоне М±31 . Можно построить шкалу в единицах долей стандартного отклонения, которая будет охватывать весь возможный диапазон изменения признака, если крайний слева и крайний справа интервалы оставить открытыми.
1 Определения и формулы расчета М и О даны в параграфе Распределение признака. Параметры распределения.
Р.Б. Кеттелл предложил, например, шкалу стенов - стандартной десятки. Среднее арифметическое значение в сырых баллах принимается за точку отсчета. Вправо и влево отмеряются интервалы, равные 1/2 стандартного отклонения. На Рис. 1.2 представлена схема вычисления стандартных оценок и перевода сырых баллов в стены по шкале N 16-факторного личностного опросника Р. Б. Кеттелла.
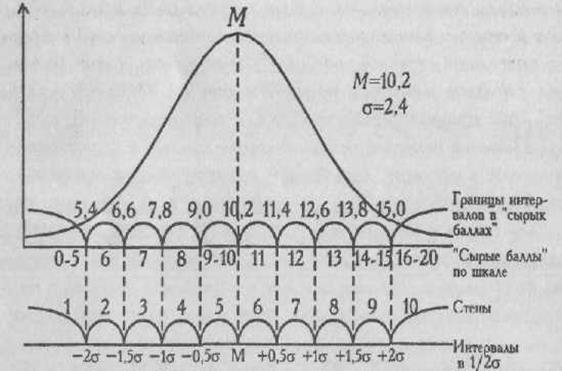
Рис. 1.1. Схема вычисления стандартных оценок (стенов) по фактору N 16-
факторного личностного опросника Р. Б. Кеттелла; снизу указаны интервалы в единицах 1/2 стандартного отклонения
Справа от среднего значения будут располагаться интервалы, равные 6, 7, 8, 9 и 10 стенам, причем последний из этих интервалов открыт. Слева от среднего значения будут располагаться интервалы, равные 5, 4, 3, 2 и 1 стенам, и крайний интервал также открыт. Теперь мы поднимаемся вверх, к оси сырых баллов, и размечаем границы интервалов в единицах сырых баллов. Поскольку М=10,2; =2,4, вправо мы откладываем 1/2 т.е. 1,2 сырых балла. Таким образом, граница интервала составит: (10,2 + 1,2) = 11,4 сырых балла. Итак, границы интервала, соответствующего 6 стенам, будут простираться от 10,2 до 11,4 баллов. В сущности, в него попадает только одно сырое значение - 11 баллов. Влево от средней мы откладываем 1/2 и получаем границу интервала: 10,2-1,2=9. Таким образом, границы интервала, соответствующие 9 стенам, простираются от 9 до 10,2. В этот интервал попадают уже два сырых значения - 9 и 10. Если испытуемый получил 9 сырых баллов, ему начисляется теперь 5 стенов; если он получил 11 сырых баллов - 6 стенов, и т. д.
Мы видим, что в шкале стенов иногда за разное количество сырых баллов будет начисляться одинаковое количество стенов. Например, за 16, 17, 18, 19 и 20 баллов будет начисляться 10 стенов, а за 14 и 15 - 9 стенов и т. д.
В принципе, шкалу стенов можно построить по любым данным, измеренным по крайней мере в порядковой шкале, при объеме выборки п200 и нормальном распределении признака2 .
Другой способ построения равноинтервальной шкалы - группировка интервалов по принципу равенства накопленных частот. При нормальном распределении признака в окрестности среднего значения группируется большая часть всех наблюдений, поэтому в этой области среднего значения интервалы оказываются меньше, уже, а по мере удаления от центра распределения они увеличиваются, (см. Рис. 1.2). Следовательно, такая процентнльная шкала является равноинтервальной только относительно накопленной частоты (Мельников В.М., Ямпольский Л.Т., 1985, с. 194).
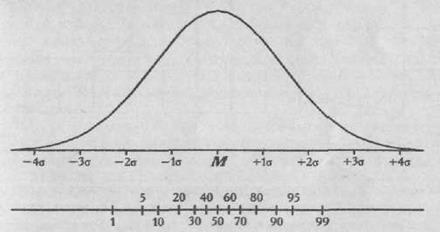
Рис. 1.2. Процентильная шкала; сверху для сравнения указаны интервалы в единицах стандартного отклонения
О нормальном распределении см. Пояснения в вопросе 3.
Построение шкал равных интервалов по данным, полученным по шкале порядка, напоминает трюк с веревочной лестницей, на который ссылался С. Стивене. Мы сначала поднимаемся по лестнице, которая ни на чем не закреплена, и добираемся до лестницы, которая закреплена. Однако каким путем мы оказались на ней? Измерили некую психологическую переменную по шкале порядка, подсчитали средние и стандартные отклонения, а затем получили, наконец, интервальную шкалу. Такому нелегальному использованию статистики может быть дано известное прагматическое оправдание; во многих случаях оно приводит к плодотворным результатам (Стивенс С, 1960, с. 56).
Многие исследователи не проверяют степень совпадения полученного ими эмпирического распределения с нормальным распределением, и тем более не переводят получаемые значения в единицы долей стандартного отклонения или процентили, предпочитая пользоваться сырыми данными. Сырые же данные часто дают скошенное, срезанное по краям или двухвершинное распределение. На Рис. 1.3 представлено распределение показателя мышечного волевого усилия на выборке из 102 испытуемых. Распределение с удовлетворительной точностью можно считать нормальным (х2 =12,7 при v=9, М=89,75, = 25,1).
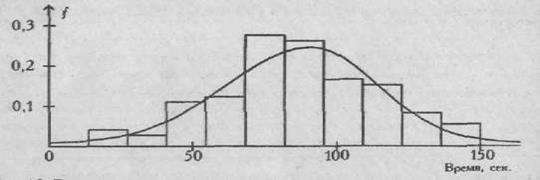
Рис. 1.3. Гистограмма и плавная кривая распределения показателя мышечного волевого усилия (п=102)
На Рис. 1.4 представлено распределение показателя самооценки по шкале методики Дж. Менестера - Р.Корзини Уровень успеха, которого я должен был достичь уже сейчас (n=356). Распределение значимо отличается от нормального
(2 = 58,8, при v=7; p0,01; М=80,64; =16,86).

Рис. 1.4. Гистограмма и плавная кривая распределения показателя должного успеха ( n =356)
С такими ненормальными распределениями приходится встречаться очень часто, чаще, может быть, чем с классическими нормальными. И дело здесь не в каком-то изъяне, а в самой специфике психологических признаков. По некоторым методикам от 10 до 20% испытуемых получают оценку ноль - например, в их рассказах не встречается ни одной словесной формулировки, которая отражала бы мотив надежда на успех или боязнь неудачи (методика Хекхаузена). То, что испытуемый получил оценку ноль, нормально, но распределение таких оценок не может быть нормальным, как бы мы ни увеличивали объем выборки (см. в. 5.3).
Методы статистической обработки, предлагаемые в настоящем руководстве, в большинстве своем не требуют проверки совпадения полученного эмпирического распределения с нормальным. Они построены на подсчете частот и ранжирования. Проверка необходима только в случае применения дисперсионного анализа. Именно поэтому соответствующая глава сопровождается описанием процедуры подсчета необходимых критериев.
Во всех остальных случаях нет необходимости проверять степень совпадения полученного эмпирического распределения с нормальным, и тем более стремиться преобразовать порядковую шкалу в равноинтервальную. В каких бы единицах ни были измерены переменные - в секундах, миллиметрах, градусах, количестве выборов и т. п. - все эти данные могут быть обработаны с помощь непараметрических критериев3 , составляющих основу данного руководства.
Определение и описание («параметрических критериев дано ниже в данной главе.
Шкала равных отношений - это шкала, классифицирующая объекты или субъектов пропорционально степени выраженности измеряемого свойства. В шкалах отношений классы обозначаются числами, которые пропорциональны друг другу: 2 так относится к 4, как 4 к 8. Это предполагает наличие абсолютной нулевой точки отсчета. В физике абсолютная нулевая точка отсчета встречается при измерении длин отрезков или физических объектов и при измерении температуры по шкале Кельвина с абсолютным нулем температур. Считается, что в психологии примерами шкал равных отношений являются шкалы порогов абсолютной чувствительности (Стивене С, 1960; Гайда В. К., Захаров В. П., 1982). Возможности человеческой психики столь велики, что трудно представить себе абсолютный нуль в какой-либо измеряемой психологической переменной. Абсолютная глупость и абсолютная честность - понятия скорее житейской психологии.
То же относится и к установлению равных отношений: только метафора обыденной речи допускает, чтобы Иванов был в 2 раза (3, 100, 1000) умнее Петрова или наоборот.
Абсолютный нуль, правда, может иметь место при подсчете количества объектов или субъектов. Например, при выборе одной из 3 альтернатив испытуемые не выбрали альтернативу А ни одного раза, альтернативу Б - 14 раз и альтернативу В - 28 раз. В этом случае мы можем утверждать, что альтернативу В выбирают в два раза чаще, чем альтернативу Б. Однако при этом измерено не психологическое свойство человека, а соотношение выборов у 42 человек.
По отношению к показателям частот возможно применять все арифметические операции: сложение, вычитание, деление и умножение. Единица измерения в этой шкале отношений - 1 наблюдение, 1 выбор, 1 реакция и т. п. Мы вернулись к тому, с чего начали: к универсальной шкале измерения в частотах встречаемости того или иного значения признака и к единице измерения, которая представляет собой 1 наблюдение. Расклассифицировав испытуемых по ячейкам номинативной шкалы, мы можем применить потом высшую шкалу измерения - шкалу отношений между частотами.
Вопрос 3 Распределение признака. Параметры распределения
Распределением признака называется закономерность встречаемости разных его значений (Плохинский Н.А., 1970, с. 12).
В психологических исследованиях чаще всего ссылаются на нормальное распределение.
Нормальное распределение характеризуется тем, что крайние значения признака в нем встречаются достаточно редко, а значения, близкие к средней величине - достаточно часто. Нормальным такое распределение называется потому, что оно очень часто встречалось в естественно-научных исследованиях и казалось нормой всякого массового случайного проявления признаков. Это распределение следует закону, открытому тремя учеными в разное время: Муавром в 1733 г. в Англии, Гауссом в 1809 г. в Германии и Лапласом в 1812 г. во Франции (Плохинский Н.А., 1970, с.17). График нормального распределения представляет собой привычную глазу психолога-исследователя так называемую колоколообразную кривую (см, напр., Рис. 1.1, 1.2).
Параметры распределения - это его числовые характеристики, указывающие, где в среднем располагаются значения признака, насколько эти значения изменчивы и наблюдается ли преимущественное появление определенных значений признака. Наиболее практически важными параметрами являются математическое ожидание, дисперсия, показатели асимметрии и эксцесса.
В реальных психологических исследованиях мы оперируем не параметрами, а их приближенными значениями, так называемыми оценками параметров. Это объясняется ограниченностью обследованных выборок. Чем больше выборка, тем ближе может быть оценка параметра к его истинному значению. В дальнейшем, говоря о параметрах, мы будем иметь в виду юс оценки.
Среднее арифметическое (оценка математического ожидания) вычисляется по формуле:
![]()
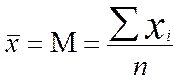
где x i - каждое наблюдаемое значение признака;
i - индекс, указывающий на порядковый номер данного значения признака;
n - количество наблюдений;
- знак суммирования.
Оценка дисперсии определяется по формуле:
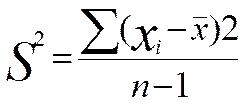
где Xi - каждое наблюдаемое значение признака;
x - среднее арифметическое значение признака;
п - количество наблюдений.
Величина, представляющая собой квадратный корень из несмещенной оценки дисперсии (S), называется стандартным отклонением или средним квадратнческим отклонением. Для большинства исследователей привычно обозначать эту величину греческой буквой (сигма), а не S. На самом деле, - это стандартное отклонение в генеральной совокупности, a S - несмещенная оценка этого параметра в исследованной выборке. Но, поскольку S - лучшая оценка (Fisher R.A., 1938), эту оценку стали часто обозначать уже не как S, а как :
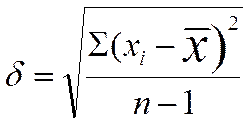
В тех случаях, когда какие-нибудь причины благоприятствуют более частому появлению значений, которые выше или, наоборот, ниже среднего, образуются асимметричные распределения. При левосторонней, или положительной, асимметрии в распределении чаще встречаются более низкие значения признака, а при правосторонней, или отрицательной - более высокие (см. Рис. 1.5).
Показатель асимметрии (А) вычисляется по формуле:
Для симметричных распределений А=0.
|
|
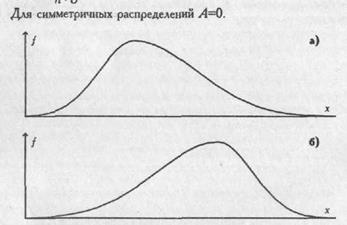
Рис. 1.5. Асимметрия распределений.
А) Левая, положительная
Б) правая, отрицательная
В тех случаях, когда какие-либо причины способствуют преимущественному появлению средних или близких к средним значений, образуется распределение с положительным эксцессом. Если же в распределении преобладают крайние значения, причем одновременно и более низкие, и более высокие, то такое распределение характеризуется отрицательным эксцессом и в центре распределения может образоваться впадина, превращающая его в двувершинное (см. Рис. 1.6).
Показатель эксцесса (Е) определяется по формуле:
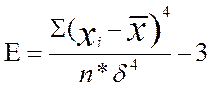
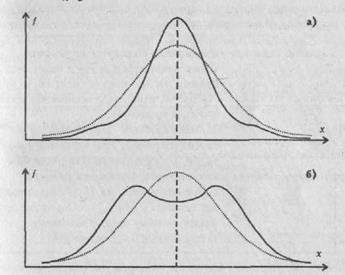
Рис. 1.6. Эксцесс: а) положительный; б) отрицательный
В распределениях с нормальной выпуклостью Е=0.
Параметры распределения оказывается возможным определить только по отношению к данным, представленным по крайней мере в интервальной шкале. Как мы убедились ранее, физические шкалы длин, времени, углов являются интервальными шкалами, и поэтому к ним применимы способы расчета оценок параметров, по крайней мере, с формальной точки зрения. Параметры распределения не учитывают
![]() истинной психологической неравномерности секунд, миллиметров и других физических единиц измерения.
истинной психологической неравномерности секунд, миллиметров и других физических единиц измерения.
На практике психолог-исследователь может рассчитывать параметры любого распределения, если единицы, которые он использовал при измерении, признаются разумными в научном сообществе.
Вопрос 4. Статистические гипотезы
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Благодаря гипотезам исследователь не теряет путеводной нити в процессе расчетов и ему легко понять после их окончания, что, собственно, он обнаружил.
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные.
Нулевая гипотеза - это гипотеза об отсутствии различий.
Она обозначается как Hо называется нулевой потому, что содержит число 0: X1 —Х2 =0, где X1 , X2 - сопоставляемые значения признаков.
Нулевая гипотеза - это то, что мы хотим опровергнуть, если перед нами стоит задача доказать значимость различий.
Альтернативная гипотеза - это гипотеза о значимости различий.
Она обозначается как Н1 . Альтернатив ная гипотеза - это то, что мы хотим доказать, поэтому иногда ее называют экспериментальной гипотезой.
Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий , ибо они более информативны для нас в поиске нового. Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными.
Направленные гипотезы
H0 : X1 не превышает Х2
H1 : X1 превышает Х2
Ненаправленные
гипотезы
H0
; X1
не отличается от Х2
H1
: X1
отличается от Х2
Если вы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной смелости, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы.
Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействии произошли более выраженные изменения, чем в группе Б, то нам тоже необходимо сформулировать направленные гипотезы.
Если же мы хотим доказать, что различаются формы распределения признака в группе А и Б, то формулируются ненаправленные гипотезы.
При описании каждого критерия в руководстве даны формулировки гипотез, которые он помогает нам проверить.
Построим схему - классификацию статистических гипотез.
Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
Вопрос 5. Статистические критерии
Статистический критерий - это решающее правило, обеспечивающее надежное поведение, то есть принятие истинной и отклонение ложной гипотезы с высокой вероятностью (Суходольский Г.В., 1972, с. 291).
Статистические критерии обозначают также метод расчета определенного числа и само это число.
Когда мы говорим, что достоверность различий определялась по критерию X 2 , то имеем в виду, что использовали метод X 2 для расчета определенного числа.
Когда мы говорим, далее, что X 2 = 12,676, то имеем в виду определенное число, рассчитанное по методу X 2 . Это число обозначается как эмпирическое значение критерия.
По соотношению эмпирического и критического значений критерия мы можем судить о том, подтверждается ли или опровергается нулевая гипотеза. Например, если X 2 эмп X 2 кр ., то Н0 отвергается.
В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, хотя есть критерии (например, критерий Манна-Уитни или критерий знаков), в которых мы должны придерживаться противоположного правила.
Эти правила оговариваются в описании каждого из представленных в руководстве критериев.
В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как п. В этом случае эмпирическое значение критерия одновременно является тестом для проверки статистических гипотез. По специальной таблице мы определяем, какому уровню статистической значимости различий соответствует данная эмпирическая величина. Примером такого критерия является критерий *, вычисляемый на основе углового преобразования Фишера.
В большинстве случаев, однако, одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в исследуемой выборке (n) или от так называемого количества степеней свободы, которое обозначается как или как df .
Число степеней свободы V равно числу классов вариационного ряда минус число условий, при которых он был сформирован (Ивантер Э.В., Коросов А.В., 1992, с. 56). К числу таких условий относятся объем выборки (n), средние и дисперсии.
Если мы расклассифицировали наблюдения по классам какой-либо номинативной шкалы и подсчитали количество наблюдений в каждой ячейке классификации, то мы получаем так называемый частотный вариационный ряд. Единственное условие, которое соблюдается при его формировании - объем выборки п. Допустим, у нас 3 класса: Умеет работать на компьютере - умеет выполнять лишь определенные операции - не умеет работать на компьютере. Выборка состоит из 50 человек. Если в первый класс отнесены 20 испытуемых, во второй - тоже 20, то в третьем классе должны оказаться все остальные 10 испытуемых. Мы ограничены одним условием - объемом выборки. Поэтому даже если мы потеряли данные о том, сколько человек не умеют работать на компьютере, мы можем определить это, зная, что в первом и втором классах - по 20 испытуемых. Мы не свободны в определении количества испытуемых в третьем- разряде, свобода простирается только на первые две ячейки классификации:
V = c - l = 3- 1 = 2
Аналогичным образом, если бы у нас была классификация из 10 разрядов, то мы были бы свободны только в 9 из них, если бы у нас было 100 классов - то в 99 из них и т. д.
Способы более сложного подсчета числа степеней свободы при двухмерных классификациях приведены в разделах, посвященных критерию 2 и дисперсионному анализу.
Зная п и/или число степеней свободы, мы по специальным таблицам можем определить критические значения критерия и сопоставить с ними полученное эмпирическое значение. Обычно это записывается так: при n=22 критические значения критерия составляют ... или при v=2 критические значения критерия составляют ... и т.п.
Критерии делятся на параметрические и непараметрические.
Параметрические критерии
Критерии, включающие в формулу расчета параметры распределения, то есть средние и дисперсии (/-критерий Стьюдента, критерий F и др.)
Непараметрические критерия
Критерии, не включающие в формулу расчета параметров распределения и основанные на оперировании частотами или рангами (критерий Q Розенбаума, критерий Т Вилкоксона и др.)
И те, и другие критерии имеют свои преимущества и недостатки. На основании нескольких руководств можно составить таблицу, позволяющую оценить возможности и ограничения тех и других (Рунион Р., 1982; McCall R., 1970; J.Greene, M.DOlivera, 1989).
Таблица 1.1
Возможности и ограничения параметрических и непараметрических критериев
ПАРАМЕТРИЧЕСКИЕ КРИТЕРИИ
1. Позволяют прямо оценить различия в средних, полученных в двух выборках (t - критерий Стьюдента).
2.Позволяют прямо оценить различия в дисперсиях (критерий Фишера).
3.Позволяют выявить тенденции изменения признака при переходе от условия к условию (дисперсионный
однофакторный анализ), но лишь при условии нормального распределения признака.
4.Позволяют оценить взаимодействие двух и более факторов в их влиянии на изменения признака (двухфакторный дисперсионный анализ).
5.Экспериментальные данные должны отвечать двум, а иногда трем, условиям:
а) значения признака измерены по интервальной шкале;
б) распределение признака является нормальным;
в) в дисперсионном анализе должно соблюдаться требование равенства дисперсий в ячейках комплекса.
6.Математические расчеты довольно сложны.
7.Если условия, перечисленные в п.5, выполняются, параметрические критерии оказываются несколько более
мощными, чем непараметрические.
НЕПАРАМЕТРИЧЕСКИЕ КРИТЕРИИ
1. Позволяют оценить лишь средние тенденции, например, ответить на вопрос, чаще ли в выборке А встречаются более высокие, а в выборке Б - более низкие значения признака (критерии Q, U, * и др.).
2.Позволяют оценить лишь различия в диапазонах вариативности признака (критерий *).
3.Позволяют выявить тенденции изменения признака при переходе от условия к условию при любом распределении признака (критерии тенденций L и S).
4.Эта возможность отсутствует.
5.Экспериментальные данные могут не отвечать ни одному из этих условий:
а) значения признака могут быть представлены в любой шкале, начиная от шкалы наименований;
б) распределение признака может быть любым и совпадение его с каким-либо теоретическим законом распределения
необязательно и не нуждается в проверке;
в) требование равенства дисперсий отсутствует.
6.Математические расчеты по большей части просты и занимают мало времени (за исключением критериев 2
и ).
7.Если условия, перечисленные в п.5, не выполняются, непараметрические критерии оказываются более мощными, чем параметрические, так как они менее чувствительны к засорениям.
Из Табл. 1.1 мы видим, что параметрические критерии могут оказаться несколько более мощными4 , чем непараметрические, но только в том случае, если признак измерен по интервальной шкале и нормально распределен. С интервальной шкалой есть определенные проблемы (см. раздел Шкалы измерения). Лишь с некоторой натяжкой мы можем считать данные, представленные не в стандартизованных оценках, как интервальные. Кроме того, проверка распределения на нормальность требует достаточно сложных расчетов, результат которых заранее неизвестен (см. параграф 7.2). Может оказаться, что распределение признака отличается от нормального, и нам так или иначе все равно придется обратиться к непараметрическим критериям.
4 О понятии мощности критерия см. ниже.
Непараметрические критерии лишены всех этих ограничений и не требуют таких длительных и сложных расчетов. По сравнению с параметрическими критериями они ограничены лишь в одном - с их помощью невозможно оценить взаимодействие двух или более условий или факторов, влияющих на изменение признака. Эту задачу может решить только дисперсионный двухфакторный анализ.
Учитывая это, в настоящее руководство включены в основном непараметрические статистические критерии. В сумме они охватывают большую часть возможных задач сопоставления данных.
Единственный параметрический метод, включенный в руководство - метод дисперсионного анализа, двухфакторный вариант которого ничем невозможно заменить.
Вопрос 6. Уровни статистической значимости
Уровень значимости - это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Когда мы указываем, что различия достоверны на 5%-ом уровне значимости, или при р 0,05 , то мы имеем виду, что вероятность того, что они все-таки недостоверны, составляет 0,05.
Когда мы указываем, что различия достоверны на 1%-ом уровне значимости, или при р 0,01 , то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01.
![]() Если перевести все это на более формализованный язык, то уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.
Если перевести все это на более формализованный язык, то уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.
Ошибка, состоящая в той, что мы отклонили нулевую гипотезу, в то время как она верна, называется ошибкой
1 рода.
Вероятность такой ошибки обычно обозначается как . В сущности, мы должны были бы указывать в скобках не р 0,05 или р 0,01, а 0,05 или 0,01. В некоторых руководствах так и делается (Рунион Р., 1982; Захаров В.П., 1985 и др.).
Если вероятность ошибки - это , то вероятность правильного решения: 1—. Чем меньше , тем больше вероятность правильного решения.
Исторически сложилось так, что в психологии принято считать низшим уровнем статистической значимости 5%-ый уровень (р0,05): достаточным – 1%-ый уровень (р0,01) и высшим 0,1%-ый уровень (р0,001), поэтому в таблицах критических значений обычно приводятся значения критериев, соответствующих уровням статистической значимости р0,05 и р0,01, иногда - р0,001. Для некоторых критериев в таблицах указан точный уровень значимости их разных эмпирических значений. Например, для *=1,56 р=О,06.
До тех пор, однако, пока уровень статистической значимости не достигнет р=0,05, мы еще не имеем права отклонить нулевую гипотезу. В настоящем руководстве мы, вслед за Р. Рунионом (1982), будем придерживаться следующего правила отклонения гипотезы об отсутствии различий (Но) и принятия гипотезы о статистической достоверности различий (Н1 ).
Правило отклонения H о и принятия H 1
Если эмпирическое значение критерия равняется критическому значению, соответствующему р0,05 или превышает его, то H0 отклоняется, но мы еще не можем определенно принять H1 .
Если эмпирическое значение критерия равняется критическому значению, соответствующему р0,01 или превышает его, то H0 отклоняется и принимается Н1 .
Исключения : критерий знаков G, критерий Т Вилкоксона и критерий U Манна-Уитни. Для них устанавливаются обратные соотношения.
Рис. 1.7. Пример «оси значимости» для критерия Q Розенбаума
Критические значения критерия обозначены как Qо,о5 и Q0,01, эмпирическое значение критерия как Qэмп. Оно заключено в эллипс.
Вправо от критического значения Q0,01 простирается зона значимости - сюда попадают эмпирические значения, превышающие Q 0 ,01 и, следовательно, безусловно значимые.
Влево от критического значения Q o,05 простирается зона незначимости, - сюда попадают эмпирические значения Q, которые ниже Q 0,05, и, следовательно, безусловно незначимы.
Мы видим, что Q 0,05 =6; Q 0,01 =9; Q эмп. =8;
Эмпирическое значение критерия попадает в область между Q0,05 и Q0,01. Это зона неопределенности: мы уже можем отклонить гипотезу о недостоверности различий (Но), но еще не можем принять гипотезы об их достоверности (H1 ).
Практически, однако, исследователь может считать достоверными уже те различия, которые не попадают в зону незначимости, заявив, что они достоверны при р 0,05, или указав точный уровень значимости полученного эмпирического значения критерия, например: р=0,02. С помощью таблиц Приложения 1 это можно сделать по отношению к критериям Н Крускала-Уоллиса, 2 r Фридмана, L Пейджа, * Фишера, Колмогорова.
Уровень статистической значимости или критические значения критериев определяются по-разному при проверке направленных и ненаправленных статистических гипотез.
При направленной статистической гипотезе используется односторонний критерий, при ненаправленной гипотезе - двусторонний критерий. Двусторонний критерий более строг, поскольку он проверяет различия в обе стороны, и поэтому то эмпирическое значение критерия, которое ранее соответствовало уровню значимости р 0,05, теперь соответствует лишь уровню р 0,10.
В данном руководстве исследователю не придется всякий раз самостоятельно решать, использует ли он односторонний или двухсторонний критерий. Таблицы критических значений критериев подобраны таким образом, что направленным гипотезам соответствует односторонний, а ненаправленным - двусторонний критерий, и приведенные значения удовлетворяют тем требованиям, которые предъявляются к каждому из них. Исследователю необходимо лишь следить за тем, чтобы его гипотезы совпадали по смыслу и по форме с гипотезами, предлагаемыми в описании каждого из критериев.
Вопрос 7. Мощность критериев
Мощность критерия - это его способность выявлять различия, если они есть. Иными словами, это его способность отклонить нулевую гипотезу об отсутствии различий, если она неверна.
Ошибка, состоящая в том, что мы приняли нулевую гипотезу, в то время как она неверна, называется ошибкой II рода.
Вероятность такой ошибки обозначается как . Мощность критерия - это его способность не допустить ошибку II рода, поэтому:
Мощность=1—
Мощность критерия определяется эмпирическим путем. Одни и те же задачи могут быть решены с помощью разных критериев, при этом обнаруживается, что некоторые критерии позволяют выявить различия там, где другие оказываются неспособными это сделать, или выявляют более высокий уровень значимости различий. Возникает вопрос: а зачем же тогда использовать менее мощные критерии? Дело в том, что основанием для выбора критерия может быть не только мощность, но и другие его характеристики, а именно:
а)простота;
б)более широкий диапазон использования (например, по отношению к данным, определенным по номинативной шкале, или по отношению к большим n);
в)применимость по отношению к неравным по объему выборкам;
г)большая информативность результатов.
Вопрос 8. Классификация задач и методов их решения
Множество задач психологического исследования предполагает те или иные сопоставления. Мы сопоставляем группы испытуемых по какому-либо признаку, чтобы выявить различия между ними по этому признаку. Мы сопоставляем то, что было до с тем, что стало после наших экспериментальных или любых иных воздействий, чтобы определить эффективность этих воздействий. Мм сопоставляем эмпирическое распределение значений признака с каким-либо теоретическим законом распределения или два эмпирических распределения между собой, с тем, чтобы доказать неслучайность выбора альтернатив или различия в форме распределений.
Мы, далее, можем сопоставлять два признака, измеренные на одной и той же выборке испытуемых, для того, чтобы установить степень согласованности их изменений, их сопряженность, корреляцию между ними.
Наконец, мы можем сопоставлять индивидуальные значения, полученные при разных комбинациях каких-либо существенных условий, с тем, чтобы выявить характер взаимодействия этих условий в их влиянии на индивидуальные значения признака.
Именно эти задачи позволяет решить тот набор методов, который предлагается настоящим руководством. Все эти методы могут быть использованы при так называемой ручной обработке данных.
Вопрос 9. Принятие решения о выборе метода математической обработки
Если данные уже получены, то вам предлагается следующий алгоритм определения задачи и метода.
АЛГОРИТМ 1
Принятие решения о задаче и методе обработки на стадии, когда данные уже получены
1. По первому столбцу Табл. 1.2 определить, какая из задач стоит в вашем исследовании.
2. По второму столбцу Табл. 1.2 определить, каковы условия решения вашей задачи, например, сколько выборок обследовано или на какое количество
групп вы можете разделить обследованную выборку.
3. Обратиться к соответствующей главе и по алгоритму принятия решения о выборе критерия, приведенного в конце каждой главы, определить, какой
именно метод или критерий вам целесообразно использовать.
Если вы еще находитесь на стадии планирования исследования, то лучшее заранее подобрать математическую модель, которую вы будете в дальнейшем использовать. Особенно необходимо планирование в тех случаях, когда в перспективе предполагается использование критериев тенденций или (в еще большей степени) дисперсионного анализа. В этом случае алгоритм принятия решения таков:
АЛГОРИТМ 2
Принятие решения о задаче и методе обработка на стадия планирования исследования
1. Определите, какая модель вам кажется наиболее подходящей для доказательства ваших научных предположений.
2.Внимательно ознакомьтесь с описанием метода, примерами и задачами для самостоятельного решения, которые к нему прилагаются.
3.Если вы убедились, что это то, что вам нужно, вернитесь к разделу Ограничения критерия и решите, сможете ли вы собрать данные, которые будут отвечать этим ограничениям (большие объемы выборок, наличие не скольких выборок, монотонно различающихся по какому-либо признаку, например, по возрасту и т.п.).
4.Проводите исследование, а затем обрабатывайте полученные данные по заранее выбранному алгоритму, если вам удалось выполнить ограничения.
5.Если ограничения выполнить не удалось, обратитесь к алгоритму 1.
В описании каждого критерия сохраняется следующая последовательность изложения:
• назначение критерия;
• описание критерия;
• гипотезы, которые он позволяет проверить;
• графическое представление критерия;
• ограничения критерия;
• пример или примеры.
Кроме того, для каждого критерия создан алгоритм расчетов. Если критерий сразу удобнее рассчитывать по алгоритму, то он приводится в разделе Пример; если алгоритм легче можно воспринять уже после рассмотрения примера, то он приводится в конце параграфа, соответствующего данному критерию.
Курс: «Математические методы в психологии»
(Для студентов психологов и социальных работников)
Лекция № 4
ВЫЯВЛЕНИЕ РАЗЛИЧИЙ В УРОВНЕ ИССЛЕДУЕМОГО ПРИЗНАКА
Вопросы:
1. Обоснование задачи сопоставления и сравнения
2. Q-критерий Розенбаума
3. U – критерий Манна-Уитни
4. Н – критерий Крускала-Уоллиса
5. S – критерий тенденций Джонкира
6. Алгоритм принятия решения о выборе критерия для сопоставлений
Вопрос 1 Обоснование задачи сопоставления и сравнения
Очень часто перед исследователем в психологии стоит задача выявления различий между двумя, тремя и более выборками испытуемых. Это может быть, например, задача определения психологических особенностей хронически больных детей по сравнению со здоровыми, юных правонарушителей по сравнению с законопослушными сверстниками или различий между работниками государственных предприятий и частных фирм, между людьми разной национальности или разной культуры и, наконец, между людьми разного возраста в методе поперечных срезов.
Иногда по выявленным в исследовании статистически достоверным различиям формируется групповой профиль или усредненный портрет человека той или иной профессии, статуса, соматического заболевания и др. (см., например, Cattell R.B., Eber H.W., Tatsuoka MM., 1970).
В последние годы все чаще встает задача выявления психологического портрета специалиста новых профессий: успешного менеджера, успешного политика, успешного торгового представителя, успешного коммерческого директора и др. Такого рода исследования не всегда подразумевают участие двух или более выборок. Иногда обследуется одна, но достаточно представительная выборка численностью не менее 60 человек, а затем внутри, этой выборки выделяются группы более и менее успешных специалистов, и их данные по исследованным переменным сопоставляются между собой. В самом простом случае критерием для разделения выборки на успешных и неуспешных- будет средняя величина по показателю успешности. Однако такое деление является довольно грубым: лица, получившие близкие оценки по успешности, могут оказаться в противоположных группах, а лица, заметно различающиеся по оценкам успешности, - в одной и той же группе. Это может исказить результаты сопоставления групп или, по крайней мере, сделать различия между группами менее заметными.
Чтобы избежать этого, можно попробовать выделить группы успешных и неуспешных специалистов более строго, включая в первую из них только тех, чьи значения превышают среднюю величину не менее чем на 1/4 стандартного отклонения, а во вторую группу - только тех, чьи значения не менее чем на 1/4 стандартного отклонения ниже средней величины. При этом все, кто оказывается в зоне средних величин, М±1/4, выпадают из дальнейших сопоставлений. Если распределение близко к нормальному, то выпадет примерно 19,8% испытуемых. Если распределение отличается от нормального, то таких испытуемых может быть и больше. Чтобы избежать потерь, можно сопоставлять не две, а три группы испытуемых: с высокой, средней и низкой профессиональной успешностью.
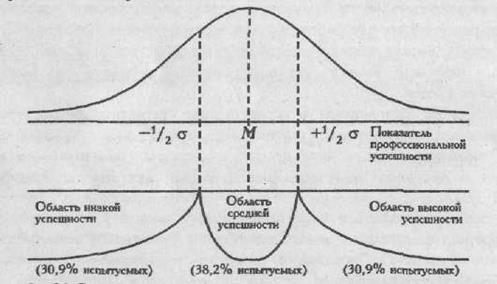
Рис 2.1. Схематическое изображение процесса разделения выборки на группы с низкой, средней и высокой профессиональной успешностью.
На Рис. 2.1 представлена схема разделения выборки на группы с низкой, средней и высокой профессиональной успешностью по критерию отклонения значений от средней величины на 1/2 стандартного отклонения. При таком строгом критерии в среднюю группу попадают (при нормальном распределении) около 38,2% всех испытуемых, а в крайних группах оказывается по 30,9% испытуемых.
Чем меньше испытуемых оказывается в группах, тем меньше у нас возможностей для выявления достоверных различий, так как критические значения большинства критериев при малых n строже, чем при больших n.
Таким образом, при нестрогом разделении испытуемых на группы мы теряем в точности, а при строгом - в количестве испытуемых.
При решении задач выявления различий в уровневых показателях следует помнить, что усредненный профиль успешного специалиста должен рассматриваться скорее как исследовательский результат, позволяющий сформулировать гипотезы для дальнейших исследований, а не как основание для профессионального отбора. Тому есть две причины.
Во-первых , ни у одного из успешных специалистов может не наблюдаться усредненный профиль - он, в сущности, является отвлеченным обобщением;
во-вторых , в профессиональной деятельности наличие собственного индивидуального стиля важнее соответствия среднегрупповому профилю. Недостаток в тех качествах, которые могут казаться важными, компенсируется другими качествами. У каждого успешного специалиста его психологические свойства создают неповторимый ансамбль, который при усреднении данных теряется.
Р.Б. Кеттелл, учитывая это, предлагал при исследовании профессиональной успешности включать в рассмотрение индивидуальные профили выдающихся представителей той или иной профессии (Cattel! R.B., Eber H.W., Tatsuoka M., 1970).
Сопоставление уровневых показателей в разных выборках может быть необходимой частью комплексных диагностических, учебных, психокоррекционных и иных программ. Оно помогает нам обратить внимание на те особенности обследованных выборок, которые должны быть учтены и использованы при адаптации программ к данной группе в процессе их конкретного воплощения.
Критерии, которые рассматриваются в данной главе, предполагают, что мы сопоставляем так называемые независимые выборки, то есть две или более выборки, состоящие из разных испытуемых. Тот испытуемый, который входит в одну выборку, уже не может входить в другую. В противоположность этому, если мы обследуем одну и ту же выборку испытуемых, несколько раз подвергая её аналогичным измерениям (замерам), то перед нами - так называемые связанные, или зависимые, выборки данных. Сопоставление 2-х или более замеров, полученных на одной и той же выборке, рассматривается в Теме 4.
Решение о выборе того или иного критерия принимается на основе того, сколько выборок сопоставляется и каков их объем (см. Алгоритм 7 в конце темы).
Вопрос 2 Q - критерий Розенбаума
Назначение критерия
Критерий используется для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. В каждой из выборок должно быть не менее 11 испытуемых.
Описание критерия
Это очень простой непараметрический критерий, который позволяет быстро оценить различия между двумя выборками по какому-либо признаку. Однако если критерий Q не выявляет достоверных различий, это еще не означает, что их действительно нет.
В этом случае стоит применить критерий * Фишера. Если же Q-критерии выявляет достоверные различия между выборками с уровнем значимости р 0,01, можно ограничиться только им и избежать трудностей применения других критериев.
Критерий применяется в тех случаях, когда данные представлены по крайней мере в порядковой шкале. Признак должен варьировать в каком-то диапазоне значений, иначе сопоставления с помощью Q -критерия просто невозможны. Например, если у нас только 3 значения признака, 1, 2 и 3, - нам очень трудно будет установить различия. Метод Роэенбаума требует, следовательно, достаточно тонко измеренных признаков.
Применение критерия начинаем с того, что упорядочиваем значения признака в обеих выборках по нарастанию (или убыванию) признака. Лучше всего, если данные каждого испытуемого представлены на отдельной карточке. Тогда ничего не стоит упорядочить два ряда значении по интересующему нас признаку, раскладывая карточки на столе. Так мы сразу увидим, совпадают ли диапазоны значений, и если нет, то насколько один ряд значений выше (S1 ), а второй - ниже (S2 ).
Для того, чтобы не запутаться, в этом и во многих других критериях рекомендуется первым рядом (выборкой, группой) считать тот ряд, где значения выше, а вторым рядом - тот, где значения ниже.
Гипотезы
Н0 : Уровень признака в выборке 1 не превышает уровня признака в выборке 2.
H1 : Уровень признака в выборке 1 превышает уровень признака в выборке 2.
Графическое представление критерия Q
На Рис. 2.2. представлены три варианта соотношения рядов значений в двух выборках. В варианте (а) все значения первого ряда выше всех значений второго ряда. Различия, безусловно, достоверны, при соблюдении условия, что n 1, n 2 11.
В варианте (б), напротив, оба ряда находятся на одном и том же уровне: различия недостоверны. В варианте (в) ряды частично перекрещиваются, но все же первый ряд оказывается гораздо выше второго. Достаточно ли велики зоны S 1 и S 2 , в сумме составляющие Q, можно определить по Таблице I Приложения 1, где приведены критические значения Q для разных n. Чем величина Q больше, тем более достоверные различия мы сможем констатировать.
Рис. 2.2. Возможные соотношения рядов значений в двух выборках:
* S 1 - зона значений 1-го ряда, которые выше максимального значения 2-го ряда;
* S 2 - зона значений второго ряда, которые меньше минимального значения 1-го ряда;
*штриховкой отмечены перекрещивающиеся зоны двух рядов
Ограничения критерия Q
1. В каждой из сопоставляемых выборок должно быть не менее 11 наблюдений. При этом объемы выборок должны примерно совпадать. Е.В. Гублером указываются следующие правила :
а) если в обеих выборках меньше 50 наблюдений, то абсолютная величина разности между n 1 и n 2 не должна быть больше 10 наблюдений;
б) если в каждой из выборок больше 51 наблюдения, но меньше 100 , то абсолютная величина разности между n 1 и n 2 не должна быть больше 20 наблюдений;
в) если в каждой из выборок больше 100 наблюдений, то допускается, чтобы одна из выборок была больше другой не более чем в 1,5-2 раза (Гублер Е.В., 1978, с. 75).
2. Диапазоны разброса значений в двух выборках должны не совпадать между собой, в противном случае применение критерия бессмысленно. Между тем, возможны случаи, когда
диапазоны разброса значений совпадают, но, вследствие разносторонней асимметрии двух распределений, различия в средних величинах признаков существенны (Рис. 2.3., 2.4).
|
|
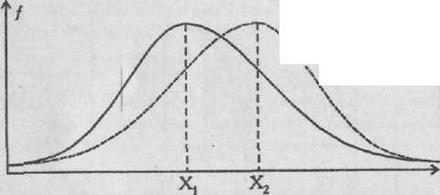
Рис. 2.3. Вариант соотношения распределений признака в двух выборках, при котором критерий Q беспомощен
|
|
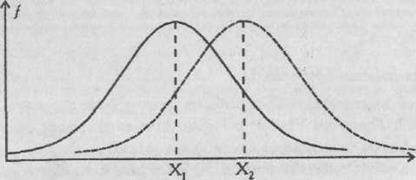
Рис. 2.4. Вариант соотношения распределений признака в двух выборках, при котором критерий Q может быть могущественным
Пример
У предполагаемых участников психологического эксперимента, моделирующего деятельность воздушного диспетчера, был измерен уровень вербального и невербального интеллекта с помощью методики Д. Векслера. Было обследовано 26 юношей в возрасте от 18 до 24 лет (средний возраст 20,5 лет). 14 из них были студентами физического факультета, а 12 - студентами психологического факультета Ленинградского университета (Сидоренко Е.В., 1978). Показатели вербального интеллекта представлены в Табл. 2.1.
Можно ли утверждать, что одна из групп превосходит другую по уровню вербального интеллекта?
Таблица 2.1
Индивидуальные значения вербального интеллекта в выборках студентов физического (n1 =14) и психологического (п2 =12) факультетов
| Студе нты-физики |
Студенты - психологи |
|||||
| Код имени испытуемого |
Показатели вербального интеллекта |
Код имени испытуемого |
Показатель вербального интеллекта |
|||
| 1. |
И.А |
132 |
1. |
Н.Т. |
126 |
|
| 2. |
К.А. |
134 |
2. |
О.В. |
127 |
|
| 3. |
К.Е. |
124 |
3. |
Е.В. |
132 |
|
| 4. |
П.А. |
132 |
4. |
Ф.О. |
120 |
|
| 5. |
С.А. |
135 |
5. |
И.Н. |
119 |
|
| 6. |
СтЛ. |
132 |
6. |
И.Ч. |
126 |
|
| 7. |
Т.А. |
131 |
7. |
И.8. |
120 |
|
| 8. |
Ф.А. |
132 |
8. |
КО. |
123 |
|
| 9. |
Ч.И. |
121 |
9. |
Р.Р. |
120 |
|
| 10. |
Ц.А. |
127 |
10. |
Р.И. |
116 |
|
| 11. |
См.А. |
136 |
11. |
O.K. |
123 |
|
| 12. |
КАн. |
129 |
12. |
Н.К. |
115 |
|
| 13. |
Б.Л. |
136 |
||||
| 14. |
Ф.В. |
136 |
||||
Упорядочим значения в обеих выборках, а затем сформулируем гипотезы:
H0 : Студенты-физики не превосходят студентов-психологов по уровню вербального интеллекта.
H1 : Студенты-физики превосходят студентов-психологов по уровню вербального интеллекта.
| р а при Q9 Mn Q |
| мы |
| 1( p |
Таблица 2.2.
Упорядоченные по убыванию вербального интеллекта ряды индивидуальных значении в двух студенческих выборках
| 1 ряд – студенты-физики |
2 ряд – студенты-психологи |
|||||||
| 1 |
См.А |
136 |
S1 |
|||||
| 2 |
Б.Л. |
136 |
||||||
| 3 |
Ф.В. |
136 |
||||||
| 4 |
С.А. |
135 |
||||||
| 5 |
К.А. |
134 |
||||||
| 6 |
И.К. |
132 |
1 |
Е.В. |
132 |
|||
| 7 |
П.А. |
132 |
||||||
| 8 |
Ст.А. |
132 |
||||||
| 9 |
Ф.А. |
132 |
||||||
| 10 |
Т.А. |
131 |
||||||
| 11 |
К.Ан. |
129 |
||||||
| 12 |
Ц.А. |
127 |
2 |
О.В. |
127 |
|||
| 3 |
Н.Т. |
126 |
||||||
| 4 |
И.Ч. |
126 |
||||||
| 13 |
К.Е. |
124 |
||||||
| 5 |
К.О. |
123 |
||||||
| 6 |
О.К. |
123 |
||||||
| 14 |
Ч.И. |
121 |
||||||
| S2 |
7 |
Ф.О. |
120 |
|||||
| 8 |
И.В. |
120 |
||||||
| 9 |
Р.Р. |
120 |
||||||
| 10 |
И.Н. |
119 |
||||||
| 11 |
Р.И. |
116 |
||||||
| 12 |
Н.К. |
115 |
||||||
Как видно из Табл. 2.2, мы правильно обозначили ряды: первый, тот, что выше - ряд физиков, а второй, тот, что ниже - ряд психологов.
По Табл. 2.2 определяем количество значений первого ряда, которые больше максимального значения второго ряда: S 1 =5.
Теперь определяем количество значений второго ряда, которые меньше минимального значения первого ряда: S 2 =6.
Вычисляем Q эмп по формуле:
Q эмп = S 1 + S 2 = 5+6 =11
По Табл.1 Приложения 1 определяем критические значения Q для n1 =14, n2 =12:
Qкр
= 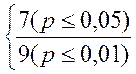
Ясно, что чем больше расхождения между выборками, тем больше величина Q . Н0 отклоняется при Q эмп Q кр, а при Q эмп Q кр мы будем вынуждены принять Н0.
Построим «ось значимости»
| Q0,05 |
Q0,01 |
||
| … |
? |
Q эмп |
! |
| 7 |
9 |
11 |
Q эмп Q кр (p0.01)
Ответ: H0 отклоняется.
Принимается H 1 . Студенты-физики превосходят студентов-психологов по уровню вербального интеллекта (р0,01). Отметим, что в тех случаях, когда эмпирическая величина критерия оказывается на границе зоны незначимости, мы имеем право утверждать лишь, что различия достоверны при р 0,05, если же оно оказывается между двумя критическими значениями, то мы можем утверждать, что р 0,05.
Если эмпирическое значение критерия оказывается на границе, мы можем утверждать, что р 0,01, если оно попадает в зону значимости, мы можем утверждать, что р 0,01.
Поскольку уровень значимости выявленных различий достаточно высок (р0,01), мы могли бы на этом остановиться. Однако если исследователь сам психолог, а не физик, вряд ли он на этом остановится. Он может попробовать сопоставить выборки по уровню невербального интеллекта, поскольку именно невербальный интеллект определяет уровень интеллекта в целом и степень его организованности (см., например: Бергер М.А., Логинова Н.А., 1974).
Мы вернемся к этому примеру при рассмотрении критерия Манна-Уитни и попытаемся ответить на вопрос о соотношении уровней невербального интеллекта в двух выборках. Быть может, психологи еще окажутся в более высоком ряду!
АЛГОРИТМ 3
Подсчет критерия Q Розенбаума
1.Проверить, выполняются ли ограничения: n 1, n 2 11, n1 n2
2.Упорядочить значения отдельно в каждой выборке по степени возрастания признака. Считать выборкой 1 ту выборку, значения в которой предположительно выше, а выборкой 2 - ту, где значения предположительно ниже.
3.Определить самое высокое (максимальное) значение в выборке 2.
4.Подсчитать количество значений в выборке 1, которые выше максимального значения в выборке 2. Обозначить полученную величину как S 1 .
5.Определить самое низкое (минимальное) значение в выборке 1.
6.Подсчитать количество значений в выборке 2, которые ниже минимального значения выборки 1. Обозначить полученную величину как S2 .
7. Подсчитать эмпирическое значение Q по формуле: Q = S 1 + S 2 .
8.По Табл. I Приложения I определить критические значения Q для данных n1, и n2. Если Qэмп равно Q0,05 или превышает его, Н0 отвергается.
9.При n1,
n2
26 сопоставить полученное эмпирическое значение с Qкр
=8 (р0,05) и QKp
=10(p0,01). Если Qэмп
превышает или по
крайней мере равняется Qкр=8, H0
отвергается.
Вопрос 2.3 U - критерий Манна-Уитнн
Назначение критерия
Критерий предназначен для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. Он позволяет выявлять различия между мал ыми выборками, когда n1, n2 3 или n1 =2, n2 5. И является более мощным, чем критерий Розенбаума.
Описание критерия
Существует несколько способов использования критерия и несколько вариантов таблиц критических значений, соответствующих этим способам (Гублер Е. В., 1978; Рунион Р., 1982; Захаров В. П.Р 1985; McCall R., 1970; Krauth J., 1988).
Этот метод определяет, достаточно ли мала зона перекрещивающихся значений между двумя рядами. Мы помним, что 1-м рядом (выборкой, группой) мы называем тот ряд значений, в котором значения, по предварительной оценке, выше, а 2-м рядом - тот, где они предположительно ниже.
Чем меньше область перекрещивающихся значений, тем более вероятно, что различия достоверны. Иногда эти различия называют различиями в расположении двух выборок (Welkowitz J. et al., 1982).
Эмпирическое значение критерия U отражает то, насколько велика зона совпадения между рядами. Поэтому чем меньше U эмп, тем более вероятно, что различия достоверны.
Гипотезы
H0 : Уровень признака в группе 2 не ниже уровня признака
в группе 1.
H1 : Уровень признака в группе 2 ниже уровня признака
в группе 1.
Графическое представление критерия U
На Рис. 2.5. представлены три из множества возможных вариантов соотношения двух рядов значений.
В варианте (а) второй ряд ниже первого, и ряды почти не перекрещиваются. Область наложения слишком мала, чтобы скрадывать различия между рядами. Есть шанс, что различия между ними достоверны. Точно определить это мы сможем с помощью критерия U.
В варианте (б ) второй ряд тоже ниже первого, но и область перекрещивающихся значений у двух рядов достаточно обширна. Она может еще не достигать критической величины, когда различия придется признать несущественными. Но так ли это, можно определить только путем точного подсчета критерия U.
В варианте (в) второй ряд ниже первого, но область наложения настолько обширна, что различия между рядами скрадываются.
|
|
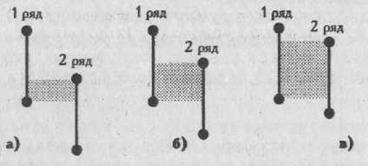
Рис. 2.5. Возможные варианты соотношении рядов значений в двух выборках; штриховкой обозначены зоны наложения
Ограничения критерия U
1. В каждой выборке должно быть не менее 3 наблюдении:
n1, n2 3; допускается, чтобы в одной выборке было 2 наблюдения, но тогда во второй их должно быть не менее 5.
2. В каждой выборке должно быть не более 60 наблюдений; Однако уже при n1, n2 20 ранжирование становится достаточно трудоемким.
На наш взгляд, в случае, если n1, n2 20, лучше использовать другой критерий, а именно угловое преобразование Фишера в комбинации с критерием , позволяющим выявить критическую точку, в которой накапливаются максимальные различия между двумя сопоставляемыми выборками. Формулировка звучит сложно, но сам метод достаточно прост. Каждому исследователю лучше попробовать разные пути и выбрать тот, который кажется ему более подходящим.
Пример
Вернемся к результатам обследования студентов физического и психологического факультетов Ленинградского университета с помощью методики Д. Векслера для измерения вербального и невербального интеллекта. С помощью критерия Q Розенбаума мы в предыдущем параграфе смогли с высоким уровнем значимости определить, что уровень вербального интеллекта в выборке студентов физического факультета выше. Попытаемся установить теперь, воспроизводится ли этот результат при сопоставлении выборок по уровню невербального интеллекта. Данные приведены в Табл. 2.3.
Можно ли утверждать, что одна из выборок превосходит другую по уровню невербального интеллекта?
Таблица 2.3
Индивидуальные значения невербального интеллекта в выборках студентов физического (n1 =14) и психологического (n2 =12) факультетов
| Студе нты-физики |
Студенты - психологи |
|||||
| Код имени испытуемого |
Показатели невербального интеллекта |
Код имени испытуемого |
Показатель невербального интеллекта |
|||
| 1. |
И.А |
111 |
1. |
Н.Т. |
113 |
|
| 2. |
К.А. |
104 |
2. |
О.В. |
107 |
|
| 3. |
К.Е. |
107 |
3. |
Е.В. |
123 |
|
| 4. |
П.А. |
90 |
4. |
Ф.О. |
122 |
|
| 5. |
С.А. |
115 |
5. |
И.Н. |
117 |
|
| 6. |
СтЛ. |
107 |
6. |
И.Ч. |
112 |
|
| 7. |
Т.А. |
106 |
7. |
И.8. |
105 |
|
| 8. |
Ф.А. |
107 |
8. |
КО. |
108 |
|
| 9. |
Ч.И. |
95 |
9. |
Р.Р. |
111 |
|
| 10. |
Ц.А. |
116 |
10. |
Р.И. |
114 |
|
| 11. |
См.А. |
127 |
11. |
O.K. |
102 |
|
| 12. |
КАн. |
115 |
12. |
Н.К. |
104 |
|
| 13. |
Б.Л. |
102 |
||||
| 14. |
Ф.В. |
99 |
||||
Критерий U требует тщательности и внимания. Прежде всего, необходимо помнить правила ранжирования.
![]() Правила
ранжирования
Правила
ранжирования
1. Меньшему значению начисляется меньший ранг.
Наименьшему значению начисляется ранг 1.
Наибольшему значению начисляется ранг, соответствующий количеству ранжируемых значений. Например, если п=7, то наибольшее значение получит ранг 7, за возможным исключением для тех случаев, которые предусмотрены правилом 2.
2. В случае, если несколько значений равны, им начисляется ранг, представляющий собой среднее значение из тех рангов, которые они получили бы, если бы не были равны.
Например , 3 наименьших значения равны 10 секундам. Если бы мы измеряли время более точно, то эти значения могли бы различаться и составляли бы, скажем, 10,2 сек; 10,5 сек; 10,7 сек. В этом случае они получили бы ранги, соответственно, 1, 2 и 3. Но поскольку полученные нами значения равны, каждое из них получает средний ранг:

Допустим, следующие 2 значения равны 12 сек. Они должны были бы получить ранги 4 и 5, но, поскольку они равны, то получают средний ранг:
![]() и т.д.
и т.д.
3. Общая сумма рангов должка совпадать с расчетной, которая определяется по формуле:
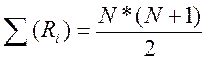
где N – общее количество ранжируемых наблюдений (значений).
Несовпадение реальной и расчётной сумм рангов будет свидетельствовать об ошибке, допущенной при начислении рангов или их суммировании. Прежде чем продолжить работу, необходимо найти ошибку и устранить её.
При подсчете критерия U легче всего сразу приучить себя действовать по строгому алгоритму.
АЛГОРИТМ 4
Подсчет критерия U Манна-Уитни
1.Перенести все данные испытуемых на индивидуальные карточки.
2.Пометить карточки испытуемых выборки 1 одним цветом, скажем красным, а все карточки из выборки 2 - другим, например, синим.
3.Разложить все карточки в единый ряд по степени нарастания признака, не считаясь с тем, к какой выборке они относятся, как если бы мы работали с одной большой выборкой.
4.Проранжировать значения на карточках, приписывая меньшему значению меньший ранг. Всего рангов получится столько, сколько у нас (n1 +n2 ).
5.Вновь разложить карточки на две группы, ориентируясь на цветные обозначения: красные карточки в один ряд, синие - в другой.
6.Подсчитать сумму рангов отдельно на красных карточках (выборка 1) и на синих карточках (выборка 2). Проверить, совпадает ли общая сумма рангов с расчетной.
7.Определить большую из двух ранговых сумм.
8.Определить значение U по формуле:
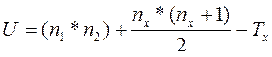
где n1 - количество испытуемых в выборке 1;
n2 - количество испытуемых в выборке 2;
Тх - большая из двух ранговых сумм;
nx - количество испытуемых в группе с большей суммой рангов. 9. Определить критические значения U по Табл. II Приложения
Если Uэмп UKp 0,05 , Н0 принимается.
Если Uэмп UKp 0,05, Но отвергается. Чем меньше значения U, тем
достоверность различий выше.
Теперь проделаем всю эту работу на материале данного примера. В результате работы по 1-6 шагам алгоритма построим таблицу.
Таблица 2.4
Подсчет ранговых сумм по выборкам студентов физического и психологического факультетов
| Студенты-физики (n1 =14) |
Студенты-психологи (n2 =12) |
||||||
| Показатель невербального интеллекта |
Ранг |
Показатель невербального интеллекта |
Ранг |
||||
| 127 |
26 |
||||||
| 123 |
25 |
||||||
| 122 |
24 |
||||||
| 117 |
23 |
||||||
| 116 |
22 |
||||||
| 115 |
20,5 |
||||||
| 115 |
20,5 |
||||||
| 114 |
19 |
||||||
| 113 |
18 |
||||||
| 112 |
17 |
||||||
| 111 |
15,5 |
111 |
15,5 |
||||
| 108 |
14 |
||||||
| 107 |
11.5 |
107 |
115 |
||||
| 107 |
11,5 |
||||||
| 107 |
11,5 |
||||||
| 106 |
9 |
||||||
| 105 |
8 |
||||||
| 104 |
6.5 |
104 |
6,5 |
||||
| 102 |
4,5 |
102 |
4,5 |
||||
| 99 |
3 |
||||||
| 95 |
2 |
||||||
| 90 |
1 |
||||||
| Суммы |
1501 |
165 |
1338 |
186 |
|||
| Средние |
107.2 |
111,5 |
|||||
Общая сумма рангов: 165+186=351.
Расчетная сумма:
![]()
Равенство реальной и расчетной сумм соблюдено.
Мы видим, что по уровню невербального интеллекта более высоким рядом оказывается выборка студентов-психологов.
Именно на эту выборку приходится большая ранговая сумма: 186.
Теперь мы готовы сформулировать гипотезы:
H0 : Группа студентов-психологов не превосходит группу студентов-физиков по уровню невербального интеллекта.
H1 : Группа студентов-психологов превосходит группу студентов-физиков по уровню невербального интеллекта.
В соответствии со следующим шагом алгоритма определяем эмпирическую величину U:
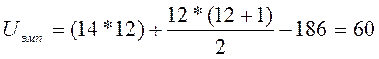
Поскольку в нашем случае n 1 не равно n 2 подсчитаем эмпирическую величину U и для второй ранговой суммы (165), подставляя в формулу соответствующее ей пх :
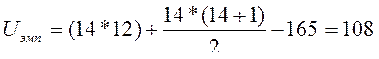
Такую проверку рекомендуется производить в некоторых руководствах (Рунион Р., 1982; Greene J., DOlivera M., 1989). Для сопоставления с критическим значением выбираем меньшую величину U: Uэмп =60.
По Табл. II Приложения 1 определяем критические значения для соответствующих п, причем меньшее п принимаем за n1 (n1 = 12) и отыскиваем его в верхней строке Табл. II Приложения 1, большее n принимаем за п2 (п2 = 14), и отыскиваем его в левом столбце Табл. II Приложения 1.
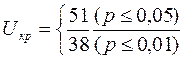
Мы помним, что критерий U является одним из двух исключений из общего правила принятия решения о достоверности различий, а именно, мы можем констатировать достоверные различия, если
Построим ось значимости.
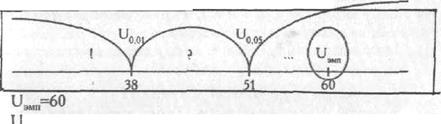
Uэмп Uкр
Ответ: Н0 принимается. Группа студентов-психологов не превосходит группы студентов-физиков по уровню невербального интеллекта.
Обратим внимание на то, что для данного случая критерий Q Розенбаума неприменим, так как размах вариативности в группе физиков шире, чем в группе психологов: и самое высокое, и самое низкое значение невербального интеллекта приходится на группу физиков (см. Табл. 2.4).
Вопрос 4 Н - критерий Крускала-Уоллиса
Назначение критерия
Критерий предназначен для оценки различий одновременно между тремя , четырьмя и т.д. выборками по уровню какого-либо признака.
Он позволяет установить, что уровень признака изменяется при переходе от группы к группе, но не указывает на направление этих изменений.
Описание критерия
Критерий Н иногда рассматривается как непараметрический аналог метода дисперсионного однофакторного анализа для несвязных выборок (Тюрин Ю. Н., 1978). Иногда его называют критерием суммы рангов (Носенко И.А., 1981).
Данный критерий является продолжением критерия U на большее, чем 2, количество сопоставляемых выборок. Все индивидуальные значения ранжируются так, как если бы это была одна большая выборка. Затем все индивидуальные значения возвращаются в свои первоначальные выборки, и мы подсчитываем суммы полученных ими рангов отдельно по каждой выборке. Если различия между выборками случайны, суммы рангов не будут различаться сколько-нибудь существенно, так как высокие и низкие ранги равномерно распределятся между выборками. Но если в одной из выборок будут преобладать низкие значения рангов, в другой - высокие, а в третьей - средние, то критерий Н позволит установить эти различия.
Гипотезы
H0 : Между выборками 1, 2, 3 и т. д. существуют лишь случайные различия по уровню исследуемого признака.
H1 : Между выборками 1, 2, 3 и т. д. существуют неслучайные различия по уровню исследуемого признака.
Графическое представление критерия Н
Критерий Н оценивает общую сумму перекрещивающихся зон при сопоставлении всех обследованных выборок. Если суммарная область наложения мала (Рис. 2.6 (а)), то различия достоверны; если она достигает определенной критической величины и превосходит ее (Рис. 2.6 (б)), то различия между выборками оказываются недостоверными.
Рис. 2.6. 2 возможных варианта соотношения рядов значений в трех выборках; штриховкой отмечены зоны наложения
Ограничения критерия Н
При сопоставлении 3-х выборок допускается, чтобы в одной из них n=3, а двух других п=2. Но при таких численных составах выборок мы сможем установить различия лишь на низшем уровне значимости (Р0,05).
Для того, чтобы оказалось возможным диагностировать различия на более высоком уровнем значимости (р0,01), необходимо, чтобы в каждой выборке было не менее 3 наблюдений, или чтобы по крайней мере в одной из них было 4 наблюдения, а в двух других - по 2; при этом неважно, в какой именно выборке сколько испытуемых, а важно соотношение 4:2:2.
Критические значения критерия Н и соответствующие им уровни значимости приведены в Табл. IV Приложения 1. Таблица предусмотрена только для трех выборок и (n1, n2, n3 )5.
При большем количестве выборок и испытуемых в каждой выборке необходимо пользоваться Таблицей критических значений критерия X2 , поскольку критерий Крускала-Уоллиса асимптотически приближается к распределению X2 (Носенко И.А., 1981; J. Greene, M. DOlivera, 1982).
Количество степеней свободы при этом определяется по формуле: v=c-l где с - количество сопоставляемых выборок.
![]() 3. При множественном сопоставлении выборок достоверные различия между какой-либо конкретной парой (или парами) их могут оказаться стертыми. Это ограничение можно преодолеть, если провести все возможные попарные сопоставления, число которых будет равняться *[c*(c-1)]*1.
Для таких попарных сопоставлений используется, естественно, критерий для двух
выборок, например U или *.
3. При множественном сопоставлении выборок достоверные различия между какой-либо конкретной парой (или парами) их могут оказаться стертыми. Это ограничение можно преодолеть, если провести все возможные попарные сопоставления, число которых будет равняться *[c*(c-1)]*1.
Для таких попарных сопоставлений используется, естественно, критерий для двух
выборок, например U или *.
Пример
В эксперименте по исследованию интеллектуальной настойчивости (Е.В. Сидоренко, 1984) 22 испытуемым предъявлялись сначала разрешимые четырехбуквенные, пятибуквенные и шестибуквенные анаграммы, а затем неразрешимые анаграммы, время работы над которыми не ограничивалось. Эксперимент проводился индивидуально с каждым испытуемым. Использовалось 4 комплекта анаграмм. У исследователя возникло впечатление, что над некоторыми неразрешимыми анаграммами испытуемые продолжали работать дольше, чем над другими, и, возможно, необходимо будет делать поправку на то, какая именно неразрешимая анаграмма предъявлялась тому или иному испытуемому. Показатели длительности попыток в решении неразрешимых анаграмм представлены в Табл. 2.5. Все испытуемые были юношами-студентами технического вуза в возрасте от 20 до 22 лет.
Можно ли утверждать, что длительность попыток решения каждой из 4 неразрешимых анаграмм примерно одинакова?
Таблица 2.5
Показатели длительности попыток решения 4 неразрешимых анаграмм в секундах (N=22)
| Группа 1: анаграмма ФОЛИТОН (n1 =4) |
Группа 2: анаграмма КАМУСТО (n2 =8) |
Группа 3: анаграмма СНЕРАКО (n3 =6) |
Группа 4: анаграмма ГРУТОСИЛ (n4 =4) |
|
| 1 |
145 |
145 |
128 |
60 |
| 2 |
194 |
210 |
283 |
2361 |
| 3 |
731 |
236 |
469 |
2416 |
| 4 |
1200 |
385 |
482 |
3600 |
| 5 |
720 |
1678 |
||
| б |
848 |
2081 |
||
| 7 |
905 |
|||
| 8 |
1080 |
|||
| Сум-мы |
2270 |
4549 |
5121 |
8437 |
| Сред-ние |
568 |
566 |
854 |
2109 |
Сформулируем гипотезы.
Н0 : 4 группы испытуемых, получившие разные неразрешимые анаграммы, не различаются по длительности попыток их решения.
H1 : 4 группы испытуемых, получившие разные неразрешимые анаграммы, различаются по длительности попыток нх решения.
Теперь познакомимся с алгоритмом расчетов.
АЛГОРИТМ 5
Подсчет критерия Н Крускала-Уоллиса
1.Перенести все показатели испытуемых на индивидуальные карточки.
2.Пометить карточки испытуемых группы 1 определенным цветом, например, красным, карточки испытуемых группы 2 - синим, карточки испытуемых групп 3 и 4 - соответственно, зеленым к желтым цветом и т. д. (Можно использовать, естественно, и любые другие обозначения.)
3.Разложить все карточки в единый ряд по степени нарастания признака, несчитаясь с тем, к какой группе относятся карточки, как если бы мы работали с одной объединенной выборкой.
4.Проранжкровать значения на карточках, приписывая меньшему значению меньший ранг. Надписать на каждой карточке ее ранг. Общее количество рангов будет равняться количеству испытуемых в объединенной выборке.
5.Вновь разложить карточки по группам, ориентируясь на цветные или другие принятые обозначения.
6.Подсчитать суммы рангов отдельно по каждой группе. Проверить совпадение общей суммы рангов с расчетной.
7.Подсчитать значение критерия Н по формуле:
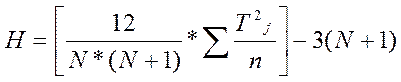
где N - общее количество испытуемых в объединенной выборке;
п - количество испытуемых в каждой группе;
Т - суммы рангов по каждой группе.
8а. При количестве групп с=3, n 1, n 2, n 3 5, определить критические значения и соответствующий им уровень значимости по Табл. IV Приложения 1.
Если Нэмп равен или превышает критическое значение H0,05 H0 отвергается.
с - количество выборок.
8б . При количестве групп с3 или количестве испытуемых n 1, n 2, n 3 5определить критические значения 2 по Табл. IX Приложения 1.
Если Нэмп равен или превышает критическое значение 2 , Но отвергается.
Воспользуемся этим алгоритмом при решении задачи о неразрешимых анаграммах. Результаты работы по 1-6 шагам алгоритма представлены в Табл. 2.6.
Таблица 2.6
Подсчет ранговых сумм по группам испытуемых, работавших над четырьмя неразрешимыми анаграммами
| Группа 1: анаграмма ФОЛИТОН (n1 =4) |
Группа 2: анаграмма КАМУСТО (n2 =8) |
Группа 3: анаграмма СНЕРАКО (n3 =6) |
Группа 4: анаграмма ГРУТОСИЛ (n4 =4) |
|||||||||
| Длитель-ность |
Ранг |
Длитель-ность |
Ранг |
Длительность |
Ранг |
Длитель-ность |
Ранг |
|||||
| 60 |
1 |
|||||||||||
| 128 |
2 |
|||||||||||
| 145 |
3.5 |
145 |
3.5 |
|||||||||
| 194 |
5 |
|||||||||||
| 210 |
6 |
|||||||||||
| 236 |
7 |
|||||||||||
| 283 |
8 |
|||||||||||
| 385 |
9 |
|||||||||||
| 469 |
10 |
|||||||||||
| 482 |
11 |
|||||||||||
| 720 |
12 |
|||||||||||
| 731 |
13 |
|||||||||||
| 848 |
14 |
|||||||||||
| 905 |
15 |
|||||||||||
| 1080 |
16 |
|||||||||||
| 1200 |
17 |
|||||||||||
| 1678 |
18 |
|||||||||||
| 2081 |
19 |
|||||||||||
| 2361 |
20 |
|||||||||||
| 2416 |
21 |
|||||||||||
| 3600 |
22 |
|||||||||||
| Суммы |
38,5 |
82,5 |
68 |
64 |
||||||||
| Средние |
9.6 |
10,3 |
11.3 |
16,0 |
||||||||
Общая сумма рангов =38,5+82,5+68+64=253.
Расчетная сумма рангов:
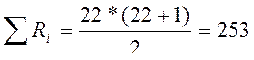
Равенство реальной и расчетной сумм соблюдено.
Теперь определяем эмпирическое значение Н:
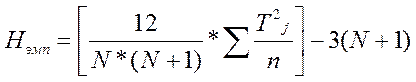
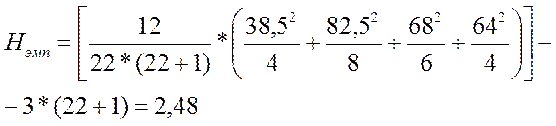
Поскольку таблицы критических значений критерия Н предусмотрены только для количества групп с = 3, а в данном случае у нас 4 группы, придется сопоставлять полученное эмпирическое значение Н с критическими значениями 2 . Для этого вначале определим количество степеней свободы V для с=4:
V = c- 1 = 4 - 1 = 3
Теперь определим критические значения по Табл. IX Приложения 1 для V=3:
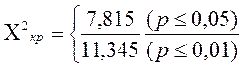
Ответ: H0 принимается: 4 группы испытуемых, получившие разные неразрешимые анаграммы, не различаются по длительности попыток их решения.
Вопрос 5. S - критерий тенденций Джонкира
Описание этого критерия дается с использованием руководства J.Greene, M.DOlivera (1982). Он описан также у М. Холлендера, ДА. Вулфа (1983).
Назначение критерия S
Критерий S предназначен для выявления тенденций изменения признака при переходе от выборки к выборке при сопоставлении трех и более выборок.
Описание критерия S
Критерий S позволяет нам упорядочить обследованные выборки по какому-либо признаку, например, по креативности, фрустрацноннон толерантности, гибкости и т.п.
Мы сможем утверждать, что на первом месте по выраженности исследуемого признака стоит выборка, скажем, Б, на втором - А, на третьем - В и т.д. Интерпретация полученных результатов будет зависеть от того, по какому принципу были образованы исследуемые выборки. Здесь возможны два принципиально отличных варианта.
1) Если обследованы выборки, различающиеся по качественным признакам (профессии, национальности, месту работы и т. п.), то с помощью критерия S мы сможем упорядочить выборки по количественно измеряемому признаку (креативности, фрустрационной толерантности, гибкости и т.п.).
2) Если обследованы выборки, различающиеся или специально сгруппированные по количественному признаку (возрасту, стажу работы, социометрическому статусу и др.), то, упорядочивая их теперь уже по другому количественному признаку, мы фактически устанавливаем меру связи между двумя количественными признаками. Например, мы можем показать с помощью критерия S, что при переходе от младшей возрастной группы к старшей фрустрационная толерантность возрастает, а гибкость, наоборот, снижается.
Меру связи между количественно измеренными переменными можно установить с помощью вычисления коэффициента ранговой корреляции или линейной корреляции. Однако критерий тенденции S имеет следующие преимущества перед коэффициентами корреляции:
а) критерий тенденций S более прост в подсчете;
б) он применим и в тех случаях, когда один из признаков варьирует в узком диапазоне, например, принимает всего 3 или 4 значения, в то время как при подсчете ранговой корреляции в этом случае мы получаем огрубленный результат, нуждающийся в поправке на одинаковые ранги.
Критерий S основан на способе расчета, близком к принципу критерия Q Розенбаума. Все выборки располагаются в порядке возрастания исследуемого признака, при этом выборку, в которой значения в общем ниже, мы помещаем слева, выборку, в которой значения выше, правее, и так далее в порядке возрастания значений. Таким образом, все выборки выстраиваются слева направо в порядке возрастания значений исследуемого признака.
При упорядочивании выборок мы можем опираться на средние значения в каждой выборке или даже на суммы всех значений в каждой выборке, потому что в каждой выборке должно быть одинаковое количество значений. В противном случае критерий S неприменим (подробнее об этом см. в разделе Ограничения критерия S).
Для каждого индивидуального значения подсчитпывается ко личество значений справа, превышающих его по величине. Если тенденция возрастания признака слева направо существенна, то большая часть значений справа должна быть выше. Критерий S позволяет определить, преобладают ли справа более высокие значения или нет. Статистика S отражает степень этого преобладания. Чем выше эмпирическое значение S, тем тенденция возрастания признака является более существенной.
Следовательно, если Sэмп равняется критическому значению или превышает его, нулевая гипотеза может быть отвергнута.
Гипотезы
H0 : Тенденция возрастания значений признака при переходе от выборки к выборке является случайной.
H1 : Тенденция возрастания значений признака при переходе от выборки к выборке не является случайной.
Графическое представление критерия
Фактически критерий S позволяет определить, достаточно ли велика суммарная зона неперекрещивающихся значений в сопоставляемых выборках: действительно ли в первом ряду значения в общем ниже, чем в последующих, во втором - ниже, чем в оставшихся справа последующих и т. д.
Графически это представлено на Рис. 2.7.
На Рис. 2.7(а) у сопоставляемых рядов значений есть непере-крещивающиеся зоны, но их суммарная площадь может оказаться слишком небольшой, чтобы признать тенденцию возрастания признака существенной.
На рис. 2.7(6) сумма неперекрещивающихся зон, по-видимому, достаточно велика, чтобы тенденция возрастания признака была признана достоверной. Точно определить это мы сможем лишь с помощью критерия S.
![]()
Рис. 2.1 . Варианты соотношения 3-х рядов значений: S1-2 - зона тех значений 2-го ряда, которые выше всех значений 1-го ряда; S1-3 - зона тех значений 3-го ряда, которые выше всех значений 1-го ряда; S2-3 - зона тех значений 3-го рада, которые выше всех значений 2-го ряда
Ограничения критерия S
1. В каждой из сопоставляемых выборок должно быть одинаковое число наблюдений. Если число наблюдений неодинаково, то придется искусственно уравнивать выборки, утрачивая при этом часть полученных наблюдений.
Например, если в двух выборках по 7 наблюдений, а в третьей - 11, то 4 из них необходимо отсеять. Для этого карточки с индивидуальными значениями переворачиваются лицевой стороной вниз и перемешиваются, а затем из них случайным образом извлекается 7 карточек. Оставшиеся 4 карточки с индивидуальными значениями не включаются в дальнейшее рассмотрение и в подсчет критерия S. Ясно, что при таком подходе часть информации утрачивается, и общая картина может быть искажена.
Если исследователь хочет избежать этого, ему следует воспользоваться критерием Н, позволяющим выявить различия между тремя и более выборками без указания на направление этих различий (см. вопрос 4).
2. Нижний порог: не менее 3 выборок и не менее 2 наблюдений в каждой выборке. Верхний порог в существующих таблицах: не более 6 выборок и не более 10 наблюдений в каждой выборке (см. Табл. III Приложения 1 для определения критических значений S). При большем количестве выборок или наблюдений в них придется пользоваться критерием Н Крускала-Уоллиса.
Пример
Выборка претендентов на должность коммерческого директора в Санкт-Петербургском филиале зарубежной фирмы была обследована с помощью Оксфордской методики экспресс-видеодиагностики, использующей диагностические ролевые игры. Были обследованы 20 мужчин в возрасте от 25 до 40 лет, средний возраст 31,5 года. Оценки производились по 15 значимым, с точки зрения зарубежной фирмы, психологическим качествам, обеспечивающим эффективную деятельность на посту коммерческого директора. Одним из этих качеств была Авторитетность. В конце 8-часового сеанса диагностических ролевых игр и упражнений проводился социометрический опрос участников группы, в котором они должны были ответить на вопрос: Если бы я сам был представителем фирмы, я выбрал бы на должность коммерческого директора: 1).... 2).... 3).... Участники знали, что каждый их шаг является материалом для диагностики, и что в данном случае, в частности, проверяется, помимо прочего, их способность к объективному суждению о людях. В результате этой процедуры каждый участник получил то или иное количество выборов от других участников, отражающее его социометрический статус в группе претендентов.
Результаты исследования представлены в Табл. 2.7 (данные Е. В. Сидоренко, И. В. Дермановой, 1991).
Можно ли считать, что группы с разным статусом различаются и по уровню авторитетности, определявшейся независимо от социометрии с помощью экспресс-видеодиагностики?
Таблица 2.7
Показатели по шкале Авторитетности в группах с разным социометрическим статусом (N=20)
| Номера испытуемых |
Группа 1 0 выборов (n1 =5) |
Группа 2 1 выбор (n2 =5) |
Группа 3 2-3 выбора (n3 =5) |
Группа 4 4 и более выборов (n4 =5) |
| 1 |
5 |
5 |
5 |
9 |
| 2 |
5 |
6 |
6 |
9 |
| 3 |
2 |
7 |
7 |
8 |
| 4 |
5 |
6 |
7 |
8 |
| 5 |
4 |
4 |
5 |
7 |
| Суммы |
21 |
28 |
30 |
41 |
| Средние |
4,2 |
5,6 |
6,0 |
8,2 |
Сформулируем гипотезы.
H0 : Тенденция повышения значений по шкале Авторитетности при переходе от группы к группе (слева направо) случайна.
H1 : Тенденция повышения значений по шкале Авторитетности при переходе от группы к группе (слева направо) неслучайна.
Для того, чтобы нам было удобнее подсчитывать количества более высоких значении (S;), лучше упорядочить значения в каждой группе по их возрастанию (Табл. 2.8).
Таблица 2.8
Расчет критерия S при сопоставлении групп с разным социометрическим статусом по показателю Авторитетности (N=20)
| Места испыту-емых |
Группа 1 0 выборов (n1 =5) |
Группа 2 1 выбор (n2 =5) |
Группа 3 2-3 выборf (n3 =5) |
Группа 4 4 и более выборов (n4 =5) |
|||
| Индиви-дуальные значения |
Si |
Индиви-дуальные значения |
Si |
Индиви-дуальные значения |
Si |
Индиви-дуальные значения |
|
| 1 |
2 |
(15) |
4 |
(10) |
5 |
(5) |
7 |
| 2 |
4 |
(14) |
5 |
(8) |
5 |
(5) |
8 |
| 3 |
5 |
(11) |
6 |
(7) |
6 |
(5) |
8 |
| 4 |
5 |
(11) |
6 |
(7) |
7 |
(4) |
9 |
| 5 |
5 |
(11) |
7 |
(4) |
7 |
(4) |
9 |
| Суммы |
(62) |
(36) |
(23) |
||||
После того, как все индивидуальные значения расположены в порядке возрастания, легко подсчитать, сколько значений справа превышают данное значение слева. Начнем с крайнего левого столбца. Значение 2 превышают все 15 значений из трех правых столбцов; значение 4 - 14 значений из трех правых столбцов; значение 5 превышают 11 значений из трех правых столбцов. Полученные количества превышений запишем в скобках слева от каждого индивидуального значения, как это сделано в Табл. 2.8.
Расчет для второго столбца производим по тому же принципу. Мы видим, что значение 4 превышают все 10 значений из оставшихся столбцов справа; значение 5 - 8 значений из столбцов справа и т.д.
Сумма всех чисел в скобках (S1 ) составит величину А, которую нам нужно будет подставить в формулу для подсчета критерия S. Однако вначале определим максимально возможное значение А, которое мы получили бы, если бы все значения справа были больше значений слева. Эта величина называется величиной В и вычисляется по формуле:
2 Для крайнего правого столбца S, не указываются, поскольку они равны нулю.
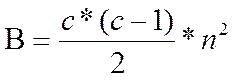
где с - количество столбцов (групп);
n - количество испытуемых в каждом столбце (груапе).
В данном случае:
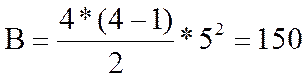
Эмпирическое значение критерия S вычисляется по формуле:
S =2*А- В
где А- сумма всех превышений по всем значениям;
В- максимально возможное количество всех превышений.
В данном случае:
S =[2*[(62+36+23+0)]-150=-92
По Табл. III Приложения 1 определяем критические значения S для с=4, п=5:
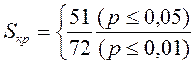
Построим ось значимости.
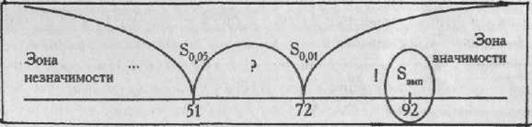
Мы помним, что критерий S построен на подсчете количества превышающих значений. Чем это количество больше, тем более достоверные различия мы сможем констатировать. Поэтому зона значимости простирается вправо, в область более высоких значений, а зона незначимости - влево, в область более низких значении.
Sэмп SKP . (р0.01)
Ответ: H0 отвергается. Принимается H1 . Тенденция повышения значений по шкале Авторитетности при переходе от группы к группе не случайна (р0,01).
Отвечая на вопрос задачи, мы можем сказать, что группы с разным статусом различаются по показателю Авторитетности, определявшемуся независимо от социометрической процедуры. Критерий S по![]() эволяет указать на тенденцию этих изменений: с ростом статуса растут и показатели по шкале Авторитетности. Однако мы имеем дело здесь, конечно же, не с причинно-следственными связями, а с сопряженными изменениями двух признаков. Возможно, оба они изменяются под влиянием одних и тех же общих факторов, например, последовательно проявляющейся в поведении привычки к лидерству, внушающей способности или харизмы.
эволяет указать на тенденцию этих изменений: с ростом статуса растут и показатели по шкале Авторитетности. Однако мы имеем дело здесь, конечно же, не с причинно-следственными связями, а с сопряженными изменениями двух признаков. Возможно, оба они изменяются под влиянием одних и тех же общих факторов, например, последовательно проявляющейся в поведении привычки к лидерству, внушающей способности или харизмы.
Теперь мы можем суммировать все сказанное, алгоритмизировав процесс подсчета критерия S.
АЛГОРИТМ 6
Подсчет критерия S Джонкнра
1.Перенести все показатели испытуемых на индивидуальные карточки.
2.Если количества испытуемых в группах не совпадают, уравнять группы, ориентируясь на количество наблюдений в меньшей из групп. Например, если в меньшей из групп n=3, то из остальных групп необходимо случайным образом
извлечь по три карточки, а остальные отсеять.
Если во всех группах одинаковое количество испытуемых (n10), можно сразу переходить к п. 3.
3.Разложить карточки первой группы в порядке возрастания признака и занести полученный ряд значений в крайний слева столбец таблицы, затем проделать то же самое для второй группы и занести полученный ряд значений во второй
слева столбец, и так далее, пока не будут заполнены все столбцы таблицы.
4.Начиная с крайнего левого столбца подсчитать для каждого индивидуального значения количество превышающих его значений во всех столбцах справа (Si).
Полученные суммы записать в скобках рядом с каждым индивидуальным значением.
5.Подсчитать суммы показателей в скобках по столбцам.
6.Подсчитать общую сумму, просуммировав все суммы по столбцам. Эту общую сумму обозначить как А.
7.Подсчитать максимально возможное количество превышающих значений (В), которое мы получили бы, если бы все значения справа были выше значений слева:

где с - количество столбцов (сопоставляемых групп);
п - количество наблюдений в каждом столбце (группе),
8.Определить эмпирическое значение S по формуле:
S
=2*
A
-
B
9.Определить критические значения S по Табл. III Приложения 1 для данного количества групп (с) и количества испытуемых в каждой группе (n).
Если эмпирическое значение S превышает или по крайней мере равняется критическому значению, H0 отвергается.
ВНИМАНИЕ! При выборе критерия рекомендуется пользоваться АЛГОРИТМОМ 7.
Алгоритм принятия решения о выборе критерия для сопоставлений
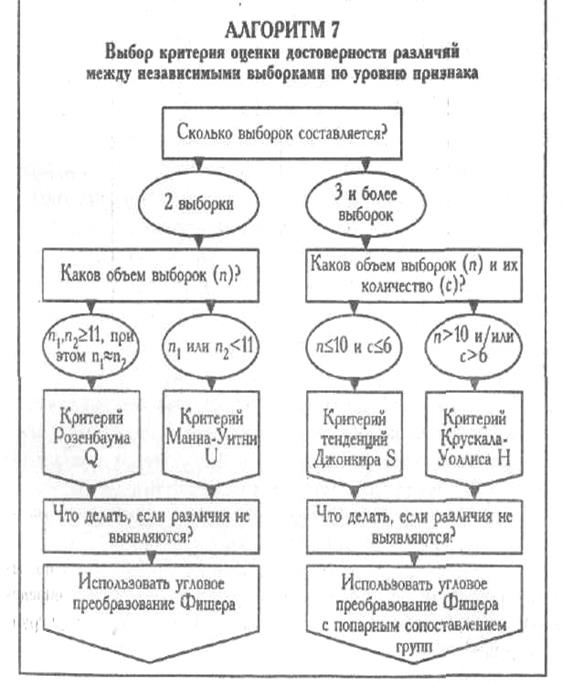
Курс «Математические методы в психологии»
(Материалы для самостоятельного изучения студентами психологами и социальными работниками)
Лекция № 5
ОЦЕНКА ДОСТОВЕРНОСТИ СДВИГА В ЗНАЧЕНИЯХ ИССЛЕДУЕМОГО ПРИЗНАКА
Вопросы:
1. Обоснование задачи исследования изменений
2. G – критерий знаков
3. T – критерий Вилкоксона
4. Критерий 2 r Фридмана
5. L – критерий тенденций Пейджа
6. Алгоритм принятия решения о выборе критерия оценки изменений
Вопрос 1
Обоснование задачи исследований изменений
В психологических исследованиях часто бывает важно доказать, что в результате действия каких-либо факторов произошли достоверные изменения (сдвиги) в измеряемых показателях. К числу таких факторов должен быть отнесён, прежде всего, фактор времени. Сопоставление показателей, полученных у одних и тех же испытуемых по одним и тем же методикам, но в разное время, дает нам временной сдвиг.
Многократные обследования одних и тех же лиц на протяжении достаточно длительного отрезка их жизненного пути, измеряемого иногда десятками лет, представляет собой так называемое лонгитюдинальное исследование, суть которого хорошо известна любому представителю Ленинградской-Петербургской школы психологии. Этот метод позволяет определить генетические связи между фазами психического развития и дать научно обоснованный прогноз дальнейшего психического развития (Ананьев Б.Г., 1976, с. 26-27).
Сопоставление показателей, полученных по одним и тем же методикам, но в разных условиях измерения (например, покоя и стресса), дает нам ситуационный сдвиг. Условия измерения могут изменяться не только реально, но и умозрительно. Например, мы можем попросить испытуемого представить себе, что он оказался в других условиях измерения: в будущем, в позиции других людей, которые оценивают его как бы со стороны, в состоянии разгневанного отца и т. п. Сопоставляя показатели, измеренные в обычных и воображаемых условиях, мы получаем умозрительный сдвиг.
Мы можем создать специальные экспериментальные условия, предположительно влияющие на те или иные показатели, и сопоставить замеры, произведенные до и после экспериментального воздействия. Если сдвиги окажутся статистически достоверными, это позволит нам утверждать, что экспериментальные воздействия были существенными, или эффективными.
Например, мы можем сделать вывод о том, что данная программа тренинга действительно способствует развитию уверенности, или что данный способ внушающего воздействия влияет на изменение отношения испытуемых к той или иной проблеме, или что психодраматическая замена ролей подтверждает постулат Дж.Л. Морено о сближении позиции спорщиков после того, как им пришлось играть роль своего оппонента и т.п.
Во всех этих случаях мы говорим - о сдвиге под влиянием контролируемых или не контролируемых воздействий. И здесь мы наталкиваемся на методическую трудность, которую оказывается возможным преодолеть только путем введения контрольной группы, которая не испытывала бы на себе воздействия данного экспериментального фактора. Если нет контрольной группы, то сдвиг в экспериментальной группе может объясняться действием самых разных причин: временем суток, в которое производились замеры, важным для испытуемых событием, которое произошло между 1-м и 2-м замерами н по мощности воздействия значительно перекрыло экспериментальный фактор и т. п. Мы никогда не сможем исключить той возможности, что изменения, достигнутые, как нам кажется, в результате наших воздействий, на самом деле объясняются неучтенными причинами, вот если в экспериментальной группе сдвиги окажутся достоверными, а в контрольной группе - недостоверными, то это, действительно, может свидетельствовать об эффективности воздействий. При отсутствии контрольной группы мы констатируем, что сдвиг произошел, но не имеем права приписать его именно данным, изучаемым нами, факторам воздействия.
Допустим, мы установили, что после того, как двум конфликтующим подгруппам пришлось играть роль своих оппонентов в споре, усилилось ощущение понимания этих оппонентов изнутри. Но мы не можем исключить возможности, что если бы мы не проводили психодраматической замены ролей, взаимопонимание все-таки бы улучшилось просто в силу того, что обе подгруппы какое-то время учились и работали вместе. Бывают случаи, когда мы не располагаем контрольной группой, но зато в нашем распоряжении есть 2 или более экспериментальных, различающихся по условиям и способам воздействия на них. Это
могут быть, помимо экспериментальных, и разнообразные естественные условия жизни, обучения, работы, общения и даже питания, водоснабжения, географического расположения и т. д. Сопоставление групп, различающихся по этим признакам, позволит нам уточнить специфическое действие экспериментальных или естественно действующих факторов, хотя при этом нам следует помнить, что воздействие неучтенных факторов может оказаться еще более мощным.
В выводах мы все-таки будет ограничены, если не проверили свои результаты на контрольной группе, в которой измерения производились параллельно.
Помимо рассмотренных сдвигов: временных, ситуационных, умозрительных и сдвигов под влиянием, - можно рассмотреть еще особую категорию структурных сдвигов.
Мы можем сопоставлять между собой разные показатели одних и тех же испытуемых, если они измерены в одних и тех же единицах, по одной и той же шкале . Например, мы можем исследовать перепад между вербальным и невербальным интеллектом, измеренными по методике Д. Векслера, или сопоставлять экспертные оценки эмпатичности и наблюдательности, измеренные по одинаковой 10-балльной шкале, или время решения двух задач, измеренное в секундах, или экзаменационную успешность по разным дисциплинам и т.п.
В принципе, мы могли бы для такого рода перепадов использовать критерии оценки достоверности в средних тенденциях для независимых выборок: U - критерий, Q - критерий и угловое преобразование Фишера. Однако, строго говоря, перед нами - зависимые ряды значений, поскольку они измерены на одних и тех же испытуемых, поэтому будет более обоснованным использовать критерии оценки достоверности сдвигов для связанных выборок. Исключение представляют случаи, когда мы сопоставляем величины сдвигов в двух независимых группах испытуемых, например экспериментальной и контрольной (см. Табл. 3.1). Допустим, если мы установили, что положительный сдвиг в сторону улучшения взаимопонимания наблюдается и в экспериментальной, и в контрольной группах, мы можем попробовать доказать, что в экспериментальной группе этот сдвиг достоверно больше, чем в контрольной, и что, следовательно, экспериментальное воздействие все-таки существенно.
Последний важный вопрос касается того, должны ли мы всегда производить оба замера на одной и той же выборке, или сдвиг можно изучать на сходных, так называемых уравновешенных выборках, совпадающих друг с другом по полу, возрасту, профессии и другим значимым для исследователя характеристикам.
В сущности, допускается сопоставление показателей разных выборок, уравновешенных по всем значимым для исследования признакам. Иными словами, можно уровень тревоги или объем внимания до экзамена измерять у одной подгруппы, а после экзамена - у другой подгруппы, если они уравновешены. Опыт показывает, однако, что создать уравновешенные подгруппы практически невозможно. Мы всегда упираемся в факт существования различий между выделенными подгруппами, которые могут в значительной степени повлиять на результат. В итоге окажется, что мы исследовали не влияние экзаменационного стресса на уровень тревоги или объем внимания, а различия по этому показателю между двумя выделенными подгруппами. К сожалению, в значительной степени это относится и к проблеме сопоставления экспериментальной и контрольной групп: мы почти никогда не можем быть уверены, что выявленные различия объясняются действием исследуемых факторов, а не различиями между двумя выборками.
Многие исследователи обходят эту проблему самым простым образом: они вообще не заботятся о контрольной группе. Сдвиг есть - значит, воздействие эффективно! И действительно, при отсутствии контрольной выборки тоже можно порассуждать на тему о том, какими же причинами, кроме предполагаемой, могут объясняться полученные сдвиги...
Другой вариант уравновешивания – ведение параллельных форм теста. В тех случаях, когда на результатах повторных замеров могут сказаться эффекты научения, приходится до измерять реакции испытуемого с помощью одного инструмента, а после - с помощью другого. В результате на измерениях может отразиться и действие фактора времени, и различия в параллельных формах теста, и непонятно что еще. Создать параллельную форму методики не менее трудно, чем подобрать уравновешенную группу испытуемых. И все же, в тех случаях, когда у нас нет другого выхода, приходится прибегать к этому способу.
При сопоставлении двух, замеров, произведенных на одной и той же (экспериментальной) выборке, применяются критерии знаков G и критерий Т Вилкоксона. При сопоставлении трех и более замеров, произведенных на одной и той же выборке, применяются критерий тенденций L Пейджа, а если он неприменим из-за большого объема выборок - критерий 2 r Фридмана.
В тех случаях, когда мы хотим оценить различия в интенсивности сдвига в двух группах испытуемых (контрольной и экспериментальной или двух экспериментальных), мы можем использовать различные варианты сопоставлений:
1) производить сопоставления отдельно в двух группах, используя критерии L и 2 r ;
2) сопоставлять показатели сдвига1 в двух группах. Поскольку группы независимы, значения сдвигов также независимы, и мы можем применять по отношению к ним уже известные нам критерии Q Розенбаума, U Манна-Уитни и * -угловое преобразование Фишера.
Сдвиг - это разность между вторым и первым замерами. 1. Сначала вычисляются разности отдельно для каждой из групп, а уж затем проводятся сопоставления Двух рядов разностей (сдвигов), полученных в разных группах. Примером такого сопоставления сдвигов в ощущении психологической дистанции является Задача 1.
Вопрос 2
G - критерий знаков
Назначение критерия G
Критерий знаков2 G предназначен для установления общего направления сдвига исследуемого признака.
2. Критерий знаков с математической точки зрения является частным случаем биномиального критерия для двух равновероятных альтернатив. При вероятности каждой из альтернатив Р=Q=0,50 критерий знаков является зеркальным отражением^ биномиального критерия (см. параграф 5.3). В некоторых руководствах критерий знаков называют критерием Мак-Немара (McCall R., 1970; Рунион Р., 1982).
Он позволяет установить, в какую сторону в выборке в целом изменяются значения признака при переходе от первого измерения ко второму: изменяются ли показатели в сторону улучшения, повышения или усиления или, наоборот, в сторону ухудшения, понижения или ослабления.
Описание критерия G
Критерий знаков применим и к тем сдвигам, которые можно определить лишь качественно (например, изменение отрицательного отношения к чему-либо на положительное), так и к тем сдвигам, которые могут быть измерены количественно (например, сокращение времени работы над заданием после экспериментального воздействия).
Во втором случае , однако, если сдвиги варьируют в достаточно широком диапазоне, лучше применять критерий Т Вилкоксона. Он учитывает не только направление, но и интенсивность сдвигов и может оказаться более мощным в определении достоверности сдвигов, чем критерий знаков.
Как правило, исследователь уже в процессе эксперимента может заметить, что у большинства испытуемых показатели во втором замере имеют тенденцию, скажем, повышаться. Однако ему еще требуется доказать, что положительный сдвиг является преобладающим.
Для начала мы назовем сдвиги, которые нам кажутся преобладающими, типичными сдвигами, а сдвиги более редкого, противоположного направления, нетипичными. Если значения показателя повышаются у большего количества испытуемых, то этот сдвиг мы будем считать типичным. Если мы исследуем отношение испытуемых к какому-либо событию или предложению, и после экспериментальных воздействий у большинства испытуемых отрицательное отношение сменилось на положительное, то этот сдвиг мы назовем типичным.
Есть еще, правда, возможность нулевых сдвигов, когда реакция не изменяется или показатели не повышаются и не понижаются, а остаются на прежнем уровне. Однако такие нулевые сдвиги в критерии знаков исключаются из рассмотрения. При этом количество сопоставляемых пар уменьшается на число таких нулевых сдвигов.
Суть критерия знаков состоит в том, что он определяет, не слишком ли много наблюдается нетипичных сдвигов, чтобы сдвиг в типичном направлении считать преобладающим? Ясно, что чем меньше нетипичных сдвигов, тем более вероятно, что преобладание типичного сдвига является преобладающим. G эмп - это количество нетипичных сдвигов. Чем меньше G эмп , тем более вероятно, что сдвиг в типичном направлении статистически достоверен.
Гипотезы
Н0 : Преобладание типичного направления сдвига является случайным.
H1 : Преобладание типичного направления сдвига не является случайным.
Графическое представление критерия знаков
На Рис. 3.1 типичные сдвиги изображены в виде светлого облака, а нетипичные сдвиги - темного облака. Мы видим, что на рисунке темное облако значительное меньше. Допустим, после выступления оратора большинство слушателей изменили свое отрицательное отношение к какому-то предложению на положительное. Вместе с тем, часть слушателей изменила свое положительное отношение на отрицательное, проявив нетипичную реакцию. Критерий знаков позволяет определить, не слишком ли значительная часть слушателей нетипично прореагировала на выступление оратора? Поглощает ли масса светлого облака небольшое темное облако?
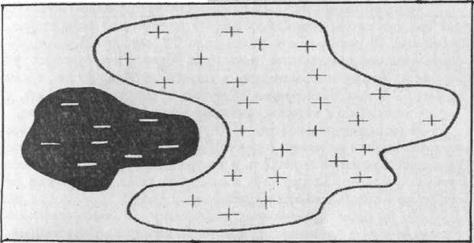
Рис. 3.1. Графическое представление положительных и отрицательных сдвигов в форме облаков: светлое облако - положительные сдвиги, темное облако - отрицательные сдвиги
Таблице V Приложения 1 даны критические значения критерия знаков для разных n.
Поскольку критерий знаков представляет собой одно из трех исключений из общего правила, представим обобщенную ось значимости для этого критерия графически (Рис. 3.2)
Нетипичных Нетипичных
сдвигов мало ? сдвигов много
Зона
неопределенности
! Зона значимости G 0,01 G 0,05 … Зона незначимости
Рис. 3.2. Обобщенная «ось значимости» для критерия знаков
Зона значимости простирается влево, в сторону более низких значений, поскольку чем меньше нетипичных знаков, тем достовернее типичный сдвиг. Зона незначимости, напротив, простирается вправо, в сторону более высоких значений G. Постепенно нетипичных сдвигов становится так много, что теряется само ощущение какого-то преобладания в направленности сдвигов. Зона незначимости характеризует ситуацию, когда сдвиги обоих направлений перемешаны.
Ограничения критерия знаков
Количество наблюдений в обоих замерах - не менее 5 и не более
300.
Пример
В исследовании Г.А. Бадасовой (1994) изучались личностные факторы суггестора, способствующие его внушающему воздействию на аудиторию. В эксперименте участвовало 39 слушателей колледжа и спецфакультета практической психологии Санкт-Петербургского университета, 9 мужчин и 30 женщин в возрасте от 18 до 39 лет, средний возраст 23,5 года. Испытуемые выступали в качестве суггерендов, т.е. лиц, по отношению к которым оказывалось внушающее воздействие.
В экспериментальной группе (n1 =16) испытуемые просматривали видеозапись речи суггестора о целесообразности применения физических наказаний в воспитании детей, а в контрольной группе (n2 =23) испытуемые просто читали про себя письменный текст. Содержание речи суггестора и текста полностью совпадали.
До и после предъявления видеозаписи (в экспериментальной группе) и текста (в контрольной группе) испытуемые отвечали на 4 вопроса, оценивая степень согласия с их содержанием по 7-балльной шкале:
1. Я считаю возможным иногда шлепнуть своего ребенка за дело, если он этого заслужил:
Не согласен 1 2 3 4 5 6 7 Согласен
2. Если, придя домой, я узнаю, что кто-то из близких, бабушка или дедушка, шлепнул моего ребенка за дело, то я буду считать, что это нормально:
Не согласен 1 2 3 4 5 6 7 Согласен
3. Если мне станет известно, что воспитательница детского сада или учительница в школе шлепнула моего ребенка за дело, то я восприму это как должное:
Не согласен 1 2 3 4 5 6 7 Согласен
4. Я бы согласился отдать своего ребенка в школу, где применяется система физических наказаний по итогам недели:
Не согласен 1 2 3 4 5 6 7 Согласен
Суггестор был подобран по признакам, которые были выявлены в пилотажном исследовании (Бадасова Г. А., 1994).
Результаты двух замеров по обеим группам представлены в Табл. 3.2 и Табл. 3.3.
Таблица 3.2
Оценки степени согласия с утверждениями о допустимости телесных наказаний до и после предъявления видеозаписи в экспериментальной
группе (n1 =16)
| Оценки и сдвиги оценок («после»-«до») по шкалам |
|||||||||||||||
| № |
Я сам |
«Бабушка » |
Воспитатель |
«Школа » |
|||||||||||
| п/п |
ДО |
после |
сдвиг |
ДО |
после |
сдвиг |
до |
после |
сдвиг |
ДО |
после |
сдвиг |
|||
| 1 |
4 |
4 |
0 |
2 |
4 |
+2 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 2 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 3 |
5 |
5 |
0 |
4 |
4 |
0 |
4 |
4 |
0 |
1 |
1 |
0 |
|||
| 4 |
4 |
5 |
+1 |
3 |
3 |
0 |
2 |
3 |
+1 |
1 |
2 |
+1 |
|||
| 5 |
3 |
3 |
0 |
3 |
4 |
+1 |
2 |
3 |
+1 |
1 |
1 |
0 |
|||
| 6 |
4 |
5 |
+1 |
5 |
5 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 7 |
3 |
3 |
0 |
3 |
3 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 8 |
5 |
6 |
+1 |
5 |
б |
+1 |
3 |
3 |
0 |
2 |
1 |
-1 |
|||
| 9 |
6 |
7 |
+1 |
5 |
7 |
+2 |
3 |
3 |
0 |
1 |
2 |
+1 |
|||
| 10 |
2 |
3 |
+1 |
2 |
3 |
+1 |
2 |
1 |
-1 |
1 |
1 |
0 |
|||
| 11 |
6 |
6 |
0 |
3 |
3 |
0 |
2 |
1 |
-1 |
1 |
1 |
0 |
|||
| 12 |
5 |
5 |
0 |
3 |
5 |
+2 |
4 |
4 |
0 |
1 |
1 |
0 |
|||
| 13 |
7 |
7 |
0 |
5 |
5 |
0 |
4 |
4 |
0 |
1 |
1 |
0 |
|||
| 14 |
5 |
б |
+1 |
5 |
6 |
+1 |
2 |
2 |
0 |
1 |
2 |
+1 |
|||
| 15 |
5 |
6 |
+1 |
5 |
6 |
+1 |
4 |
3 |
-1 |
2 |
2 |
0 |
|||
| 16 |
6 |
7 |
+1 |
6 |
7 |
+1 |
4 |
4 |
0 |
2 |
2 |
0 |
|||
Таблица 3.3
Оценки степени согласия с утверждениями о допустимости телесных наказаний до и после предъявления письменного текста в контрольной группе (n2 =23)
| Оценки и сдвиги оценок («после»-«до») по шкалам |
|||||||||||||||
| № |
Я сам |
«Бабушка » |
Воспитатель |
«Школа » |
|||||||||||
| п/п |
ДО |
после |
сдвиг |
ДО |
после |
сдвиг |
до |
после |
сдвиг |
ДО |
после |
сдвиг |
|||
| 1 |
4 |
4 |
0 |
5 |
5 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 2 |
7 |
7 |
0 |
7 |
7 |
0 |
7 |
7 |
0 |
4 |
4 |
0 |
|||
| 3 |
2 |
2 |
0 |
1 |
1 |
0 |
3 |
1 |
-2 |
1 |
1 |
0 |
|||
| 4 |
4 |
3 |
-1 |
3 |
2 |
-1 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 5 |
3 |
5 |
+2 |
5 |
5 |
0 |
3 |
3 |
0 |
1 |
1 |
0 |
|||
| 6 |
2 |
1 |
-1 |
2 |
1 |
-1 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 7 |
5 |
5 |
0 |
3 |
3 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 8 |
2 |
2 |
0 |
2 |
3 |
+1 |
1 |
3 |
+2 |
1 |
3 |
+2 |
|||
| 9 |
3 |
4 |
+1 |
3 |
4 |
+1 |
1 |
1 |
0 |
1 |
6 |
+5 |
|||
| 10 |
5 |
5 |
0 |
5 |
5 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 11 |
5 |
5 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 12 |
2 |
2 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 13 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
2 |
+1 |
6 |
7 |
+1 |
|||
| 14 |
4 |
3 |
-1 |
7 |
5 |
-2 |
2 |
4 |
+2 |
1 |
1 |
0 |
|||
| 15 |
3 |
4 |
+1 |
2 |
3 |
+1 |
1 |
2 |
+1 |
1 |
1 |
0 |
|||
| 16 |
4 |
4 |
0 |
3 |
3 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 17 |
3 |
3 |
0 |
2 |
2 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 18 |
6 |
6 |
0 |
6 |
6 |
0 |
6 |
6 |
0 |
1 |
3 |
+2 |
|||
| 19 |
2 |
2 |
0 |
2 |
1 |
-1 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 20 |
1 |
2 |
+1 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
| 21 |
2 |
2 |
0 |
2 |
2 |
0 |
2 |
1 |
-1 |
1 |
1 |
0 |
|||
| 22 |
6 |
6 |
0 |
6 |
6 |
0 |
3 |
3 |
0 |
1 |
1 |
0 |
|||
| 23 |
3 |
2 |
-1 |
1 |
2 |
+1 |
1 |
1 |
0 |
1 |
1 |
0 |
|||
Вопросы:
1. Можно ли утверждать, что после просмотра видеозаписи о пользе телесных наказании наблюдается достоверный сдвиг в сторону большего принятия их в экспериментальной группе?
2. Достоверны ли различия по выраженности положительного сдвига между экспериментальной и контрольной группами?
3. Является ли достоверным сдвиг оценок в контрольной группе?
Решение
Подсчитаем сначала количество положительных, отрицательных и нулевых сдвигов по каждой шкале в каждой из выборок. Это необходимо для выявления типичных знаков изменения оценок и значительно облегчит нам дальнейшие расчеты и рассуждения.
Таблица 3.4
Расчет количества положительных, отрицательных и нулевых сдвигов в двух группах суггерендов
| Количество сдвигов в группах |
Шкалы |
||||
| «Я сам» |
«Бабушка» |
«Воспитатель» |
«Школа» |
Суммы |
|
| 1. ЭКПЕРИМЕНТАЛЬНАЯ ГРУППА |
|||||
| А) положительных |
8 |
9 |
2 |
3 |
22 |
| Б) отрицательных |
0 |
0 |
3 |
1 |
4 |
| В) нулевых |
8 |
7 |
11 |
12 |
38 |
| 2. КОНТРОЛЬНАЯ ГРУППА |
|||||
| А) положительных |
4 |
4 |
4 |
4 |
16 |
| Б) отрицательных |
4 |
4 |
2 |
0 |
10 |
| В) нулевых |
15 |
15 |
17 |
19 |
66 |
| Сумма |
23 |
23 |
23 |
23 |
92 |
Из Табл. 3.4. мы видим, что наиболее типичными являются нулевые сдвиги, то есть отсутствие сдвига в оценках после предъявления видеозаписи или письменного текста. И все же, в экспериментальной группе но шкале Я сам наказываю и Бабушка наказывает положительные сдвиги наблюдаются примерно в половине случаев.
Нам необходимо учитывать только положительные и отрицательные сдвиги, а нулевые отбрасывать. Количество сопоставляемых пар значений при этом уменьшается на количество этих нулевых сдвигов. Теперь для шкалы Я сам n=8; для шкалы Бабушка n=9; шкалы Воспитатель n=5 и шкалы Школа n=4. Мы видим, что по отношению к последней шкале критерий знаков вообще неприменим, так как количество сопоставляемых пар значений меньше 5.
Мы можем сразу же проверить и гипотезу о преобладании положительного сдвига в ответах по сумме 4 шкал. Сумма положительных и отрицательных сдвигов по 4 шкалам составляет: n=8+9+5+4=26.
Сформулируем гипотезы.
Н0 : Сдвиг в сторону более снисходительного отношения к телесным наказаниям после внушения является случайным.
Н1: Сдвиг в сторону более снисходительного отношения к
телесным наказаниям после внушения является неслучайным.
По Табл. V Приложения 1 определяем критические значения критерия знаков G . Это максимальные количества нетипичных, менее часто встречающихся, знаков, при которых сдвиг в типичную сторону еще можно считать существенным.
1) Шкала Я сам наказываю
n=8
Типичный сдвиг - положительный. Отрицательных сдвигов нет.
G
кр
=
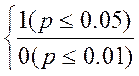
Gэмп= 0
G эмп G кр
Н0 отклоняется. Принимается Н1 (р 0,01).
2) Шкала Бабушка наказывает
n=9
Типичный сдвиг - положительный. Отрицательных сдвигов нет.
G
кр
=
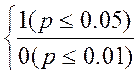
Gэмп= 0
G эмп G кр
Н0 отклоняется. Принимается Н1 (р 0,01).
Шкала Воспитательница наказывает
N=5
Типичный сдвиг - отрицательный.
Положительных сдвигов - 2.
Gкр =0 (p 0.05)
Gкр =(p 0.05) при данном n определить невозможно
G эмп =2
G эмп G кр
H0 принимается.
4) Шкала Школа наказывает
n=4
n5, критерий знаков неприменим.
5) Сумма по 4-м шкалам
n =26
Типичный сдвиг - положительный. Отрицательных сдвигов - 4
G
кр
=
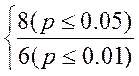
Gэмп= 4
G эмп G кр
Н0 отклоняется. Принимается H1 (p0,01).
Ответ : Сдвиг в сторону более снисходительного отношения к телесным наказаниям в экспериментальной группе после просмотра видеозаписи является неслучайным для шкал Я сам наказываю, Бабушка наказывает и по сумме четырех шкал (р 0,01 во всех случаях).
Сформулируем гипотезы для контрольной группы.
Н0 : Сдвиг в сторону более снисходительного отношения к телесным наказаниям после прочтения текста является случайным.
H1 : Сдвиг в сторону более снисходительного отношения к телесным наказаниям после прочтения текста не является случайным.
Далее действуем по тому же принципу: вначале определяем количество сдвигов в ту или иную сторону (n), выявляем типичный сдвиг и количество нетипичных сдвигов (Gэмп ) сопоставляем с критическими значениям G, определяемыми по Табл. V
Приложения 1.
1) Шкала Я сам наказываю
п=8
Положительных сдвигов - 4, отрицательных сдвигов - 4.
Типичный сдвиг установить невозможно, т.к. положительных и отрицательных сдвигов поровну.
Н0 принимается.
2) Шкала Бабушка наказывает
п=8
Положительных сдвигов - 4, отрицательных сдвигов - 4.
Н0 принимается по тем же основаниям, что и для предыдущей шкалы.
3) Шкала Воспитательница наказывает
п=6
Типичный сдвиг - положительный.
Отрицательных сдвигов - 2.
Скр =0 (р 0,05)
GKp (p 0,01) при данном п определить невозможно.
G эмп = 2
G эмп G кр
H0 принимается.
4) Шкала Школа наказывает
n
=4
Поскольку п5, критерий знаков неприменим.
5) Сумма по 4-м шкалам
п=26
Типичный сдвиг - положительный.
Количество отрицательных сдвигов - 10.
G
кр
=
Gэмп= 10
G эмп G кр
Н0 принимается.
Ответ: Сдвиг в сторону более снисходительного отношения к телесным наказаниям в контрольной группе является случайным - и по каждой из шкал в отдельности, и по сумме шкал.
Мы можем определенно ответить на 1-ый вопрос
задачи: да
, можно утверждать, что после просмотра видеозаписи о пользе телесных![]() наказаний наблюдается достоверный сдвиг в пользу большего принятия их в экспериментальной группе. Мы можем ответить и на 3-й вопрос
задачи: нет
, сдвиг оценок в контрольной группе недостоверен. Однако мы пока не ответили на второй
вопрос - о том, достоверны ли различия по выраженности положительного сдвига между экспериментальной и контрольной группами?
наказаний наблюдается достоверный сдвиг в пользу большего принятия их в экспериментальной группе. Мы можем ответить и на 3-й вопрос
задачи: нет
, сдвиг оценок в контрольной группе недостоверен. Однако мы пока не ответили на второй
вопрос - о том, достоверны ли различия по выраженности положительного сдвига между экспериментальной и контрольной группами?
Дело в том, что нами был избран вариант сопоставлений, предполагающий сравнение значений после и до экспериментального воздействия отдельно в экспериментальной и контрольной выборках. Для того, чтобы ответить на вопрос 2, необходимо выбрать второй вариант сопоставлений, предусматривающий сравнение сдвигов в двух группах с помощью критериев для сравнения независимых выборок -Q - критерия Розенбаума, U - критерия Манна-Уитни и критерия * Фишера (см. Табл. 3.1). Однако такого рода сопоставления, как правило, проводятся только в том случае, если и в экспериментальной, и в контрольной группах выявлен достоверный однонаправленный эффект, и нужно доказать, что в экспериментальной выборке он достоверно больше, выраженнее (см. Задачу 1). В данном же случае нами доказано, что в контрольной выборке не произошло сколько-нибудь значимых изменений, и мы можем этим удовлетвориться.
Казалось бы, мы доказали все, что необходимо: в экспериментальной группе испытуемые стали снисходительнее относиться к телесным наказаниям, а в контрольной группе достоверных сдвигов не обнаружено. Похоже, сугтестор, отобранный по выявленным Г. А. Бадасовой качествам, действительно повлиял на изменение оценок, и притом именно он, что-то в его личности оказало это воздействие, потому что контрольной группе предъявлялся тот же по содержанию текст, но без суггестора. Однако, на самом деле мы установили лишь то, что в тех случаях, когда наблюдался какой-то сдвиг в оценках, он был скорее положительным, чем отрицательным в экспериментальной группе и скорее случайным в контрольной группе. Все нулевые сдвиги мы отбросили, а ведь они составляют от 43,8 до 50% по тем шкалам, где обнаружен положительный достоверный сдвиг в экспериментальной выборке. Похоже, что многие, очень многие испытуемые экспериментальной выборки просто проигнорировали выступление суггестора... Однако статистический критерий свидетельствует: положительный сдвиг в оценках достоверен, по крайней мере для первых двух шкал и для тех испытуемых, которые хоть как-то прореагировали на выступление суггестора.
АЛГОРИТМ 8
Расчет критерия знаков G
1. Подсчитать количество нулевых реакций и исключить их из рассмотрения.
В результате n уменьшится на количество нулевых реакций.
2. Определить преобладающее направление изменений. Считать сдвиги в преобладающем направлении типичными.
3. Определить количество нетипичных сдвигов. Считать это число эмпирическим значением G .
4. По Табл. V Приложения 1 определить критические значения G
для данного п.
5. Сопоставить G эмп с GKp . Если G эмп меньше GKp или по крайней мере равен ему, сдвиг в типичную сторону может считаться достоверным.
Вопрос 3
Т - критерий Вилкоксона
Назначение критерия
Критерий применяется для сопоставления показателей, измеренных в двух разных условиях на одной и той же выборке испытуемых.
Он позволяет установить не только направленность изменений, но и их выраженность . С его помощью мы определяем, является ли сдвиг показателей в каком-то одном направлении более интенсивным, чем в другом.
Описание критерия Т
Этот критерий применим в тех случаях, когда признаки измерены по крайней мере по шкале порядками сдвиги между вторым и первым замерами тоже могут быть упорядочены. Для этого они должны варьировать в достаточно широком диапазоне. В принципе, можно применять критерий Т и в тех случаях, когда сдвиги принимают только три значения: —1, 0 и +1, но тогда критерий Т вряд ли добавит что-нибудь новое к тем выводам, которые можно было бы получить с помощью критерия знаков. Вот если сдвиги изменяются, скажем, от —30 до +45, тогда имеет смысл их ранжировать и потом суммировать ранги
|
|
|
|
Суть метода состоит в том, что мы сопоставляем выраженность сдвигов в том и ином направлениях по абсолютной величине. Для этого мы сначала ранжируем все абсолютные величины сдвигов, а потом суммируем ранги. Если сдвиги в положительную и в отрицательную сторону происходят случайно, то суммы рангов абсолютных значений их будут примерно равны. Если же интенсивность сдвига в одном из направлений перевешивает, то сумма рангов абсолютных значений сдвигов в противоположную сторону будет значительно ниже, чем это могло бы быть при случайных изменениях.
Первоначально мы исходим из предположения о том, что типичным сдвигом будет сдвиг в более часто встречающемся направлении, а нетипичным, или редким, сдвигом - сдвиг в более редко встречающемся направлении.
Гипотезы
Но: Интенсивность сдвигов в типичном направлении не превосходит интенсивности сдвигов в нетипичном направлении.
Н1 . Интенсивность сдвигов в типичном направлении превышает интенсивность сдвигов в нетипичном направлении.
Графическое представление критерия Т
Сдвига в противоположные стороны мы можем представить себе в виде двух облаков, как и в критерии знаков. Величина облака зависит не только от количества соответствующих сдвигов, но и от их интенсивности, отраженной в длине стрелок (Рис. 3.3). В сущности, облака противостоят друг другу, как два воздушных фронта: они не просто соревнуются по величине, они меряются силами! При определенных п, а именно при п 18, мы вообще можем отказаться от понятия типичного сдвига. Сдвигов в ту и другую сторону может оказаться поровну, но если 9 меньших сдвигов будут относиться к одному направлению, а 9 больших сдвигов - к противоположному, то мы можем констатировать достоверное преобладание этого противоположного направления сдвигов. Вспомним, что критерий знаков в этом случае не выявил бы никаких достоверных различий.
|
|
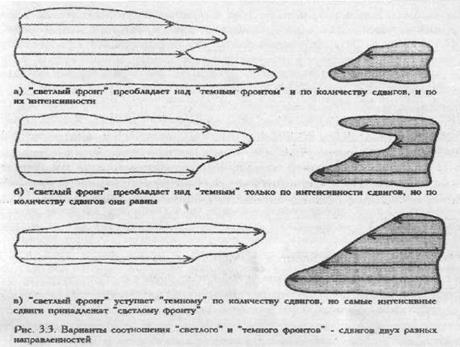
А) «Светлый фронт» преобладает над «тёмным фронтом» и по количеству сдвигов, и по их интенсивности.
Б) «Светлый фронт» преобладает над «тёмным фронтом» только по интенсивности сдвигов, но по количеству сдвигов они равны.
в) светлый фронт уступает темному по количеству сдвигов, но самые интенсивные сдвиги принадлежат «светлому фронту».
Рис. 3.3. Варианты соотношения светлого и темного фронтов - сдвигов двух разных направленностей
На Рис. З.З(а) светлый фронт преобладает над темным фронтом и по количеству сдвигов, и по их интенсивности. На Рис. 3.3(6) светлый фронт преобладает только по интенсивности сдвигов, но не по их количеству; на Рис. З.З(в) в светлом фронте наблюдаются более интенсивные сдвиги, но их меньше, чем в темном фронте. Здесь критерии знаков мог бы констатировать преобладание изменений, соответствующих темному фронту. Между тем, интенсивность противоположных, хотя и редких, сдвигов, столь велика, что делать какие-то однозначные выводы было бы опрометчиво.
Ограничения в применения критерия Т Внлкоксона
1. Минимальное количество испытуемых, прошедших измерения в двух условиях - 5 человек. Максимальное количество испытуемых - 50 человек, что диктуется верхней границей имеющихся таблиц. Критические значения Т приведены в Табл. VI Приложения 1.
2. Нулевые сдвиги из рассмотрения исключаются, и количество наблюдений n уменьшается на количество этих нулевых сдвигов (McCall R., 1970, р. 36). Можно обойти это ограничение, сформулировав гипотезы, включающие отсутствие изменений, например: Сдвиг в сторону увеличения значений превышает сдвиг в сторону уменьшения значений и тенденцию сохранения их на прежнем уровне.
Пример
В выборке курсантов военного училища (юноши в возрасте от 18 до 20 лет) измерялась способность к удержанию физического волевого усилия на динамометре. Сначала у испытуемых измерялась максимальная мышечная сила каждой из рук, а на следующий день им предлагалось выдерживать, на динамометре с подвижной стрелкой мышечное усилие, равное 1/2 максимальной мышечной силы данной руки. Почувствовав усталость, испытуемый должен был сообщить об этом экспериментатору, но не прекращать опыт, преодолевая усталость и неприятные ощущения - бороться, пока воля не иссякнет. Опыт проводился дважды; вначале с обычной инструкцией, а затем, после того, как испытуемый заполнял опросник самооценки волевых качеств по методике А.Ц. Пуни (Пуни А.Ц., 1977), ему предлагалось представить себе, что он уже добился идеала в развитии волевых качеств, и продемонстрировать соответствующее идеалу волевое усилие. Подтвердилась ли гипотеза экспериментатора о том, что обращение к идеалу способствует возрастанию волевого усилия? Данные представлены в Табл. 3.5.
Таблица 3.5
Расчет критерия Т при сопоставлении замеров физического волевого усилия
| Код имени испытуемого |
Длительность удержания усилия на динамометре (с) |
Разность (tпосле- tдо ) |
Абсолютное значение разности |
Рангоаый номер разности |
||
| До измерения волевых качеств и обращения к идеалу (tдо ) |
После измерения волевых качеств и обращения к идеалу (tпосле ) |
|||||
| 1 |
Г. |
64 |
25 |
-39 |
39 |
11 |
| 2 |
Кос. |
77 |
50 |
-27 |
27 |
8 |
| 3 |
Крив. |
74 |
77 |
+3 |
3 |
1 |
| 4 |
Кур. |
95 |
76 |
-19 |
19 |
6 |
| 5 |
Л. |
105 |
67 |
-38 |
38 |
9,5 |
| 6 |
М. |
83 |
75 |
-8 |
8 |
4 |
| 7 |
Р. |
73 |
77 |
+4 |
4 |
2,5 |
| 8 |
С. |
75 |
71 |
-4 |
4 |
2,5 |
| 9 |
Т. |
101 |
63 |
-38 |
38 |
9,5 |
| 10 |
Х. |
97 |
122 |
+25 |
25 |
7 |
| 11 |
Ю. |
78 |
60 |
-18 |
18 |
5 |
| Сумма |
66 |
|||||
Для подсчета этого критерия нет необходимости упорядочивать ряды значений по нарастанию признака. Мы можем использовать алфавитный список испытуемых, как в данном случае.
Первый шаг в подсчете критерия Т - вычитание каждого индивидуального значения до из значения после»3 . Мы видим из Табл. 3.5, что 8 полученных разностей - отрицательные и лишь 3 - положительные. Это означает, что у 8 испытуемых длительность удержания мышечного усилия во втором замере уменьшилась, а у 3 - увеличилась. Мы столкнулись с тем случаем, когда уже сейчас мы не можем сформулировать статистическую гипотезу, соответствующую первоначальному предположению исследователя. Предполагалось, что обращение к идеалу будет увеличивать длительность мышечного усилия, а экспериментальные данные свидетельствуют, что лишь в 3 случаях из 11 этот показатель действительно увеличился. Мы можем сформулировать лишь гипотезу, предполагающую несущественность сдвига этого показателя в сторону снижения.
3 Можно вычитать значения после из значений до, это никак не повлияет на расчет критерия. Но лучше во всех случаях придерживаться одной системы, чтобы не запутаться самим.
Сформулируем гипотезы.
H0 : Интенсивность сдвигов в сторону уменьшения длительности мышечного усилия не превышает интенсивности сдвигов в сторону ее увеличения.
Н1 : Интенсивность сдвигов а сторону уменьшения длительности мышечного усилия превышает интенсивность сдвигов в сторону ее увеличения.
На следующем шаге все сдвиги, независимо от их знака, должны быть проранжированы по выраженности. В Табл. 3.5 в четвертом слева столбце приведены абсолютные величины сдвигов, а в последнем столбце (справа) - ранги этих абсолютных величин. Меньшему значению соответствует меньший ранг. При этом сумма рангов равна 66, что соответствует расчетной:
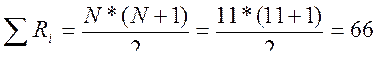
Теперь отметим те сдвиги, которые являются нетипичными, в данном случае - положительными. В Табл. 3.5 эти сдвиги и соответствующие им ранги выделены цветом. Сумма рангов этих редких сдвигов и составляет эмпирическое значение критерия Т:
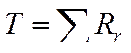
где Rr - ранговые значения сдвигов с более редким знаком. Итак, в данном случае,
Тэмп =1+2,5+7=10,5
По Таблице VI Приложения 1 определяем критические значения Т для п =11:
Построим ось значимости.
| Т0,01 |
? |
Т0,05 |
| Зона значимости ! |
Тэмп |
…Зона незначимости |
| 7 |
10,5 |
13 |
Зона значимости в данном случае простирается влево. Действительно, если бы редких, в данном случае положительных, сдвигов не было совсем, то и сумма их рангов равнялась бы нулю. В данном же случае эмпирическое значение Т попадает в зону неопределенности:
Ответ: Но отвергается. Интенсивность отрицательного сдвига показателя физического волевого усилия превышает интенсивность положительного сдвига (р0,05).
Попытаемся графически отобразить интенсивность отрицательных и положительных сдвигов. На Рис. 3.4 слева сдвиги представлены в секундах, а справа - в своих ранговых значениях. Мы видим, что ранжирование несколько уменьшает площади сопоставляемых облаков, или фронтов.
Рис. 3.4. Графическое представление отрицательных и положительных сдвигов в длительности удержания мышечного усилия; слева - и секундах; справа - в ранговых значениях
Таким образом, исследователю придется признать, что продолжительность удержания мышечного волевого усилия во втором замере снижается, и этот сдвиг неслучаен. Инструкция, ориентирующая испытуемого на соответствие идеалу в развитии воли, оказалась гораздо менее мощным фактором, чем какая-то иная сила - возможно, мышечное утомление, может быть, разочарование в себе или в возможностях данного психологического эксперимента. А может быть, в момент второго замера просто перестает действовать какой-то мощный фактор, который был активен вначале? На все эти вопросы статистические методы не могут ответить, если в схему эксперимента не включена контрольная группа - в данном случае, выборка, уравновешенная с экспериментальной группой по всем значимым характеристикам (полу, возрасту, профессии, месту обучения), у которой просто измерили бы вторично волевое усилие через такой же промежуток времени, не призывая соответствовать идеалу в развитии воли.
Представим выполненные действия в виде алгоритма:
АЛГОРИТМ 9
Подсчет критерия Т Вилкоксона
1. Составить список испытуемых в любом порядке, например, алфавитном.
2. Вычислить разность между индивидуальными значениями во втором и первом замерах (после - до). Определить, что будет считаться типичным сдвигом и сформулировать соответствующие гипотезы.
3. Перевести разности в абсолютные величины и записать их отдельным столбцом (иначе трудно отвлечься от знака разности).
4. Проранжировать абсолютные величины разностей, начисляя меньшему значению меньший ранг. Проверить совпадение полученной суммы рангов с расчетной.
5. Отметить кружками или другими знаками ранги, соответствующие сдвигам в нетипичном направлении.
S. Подсчитать сумму этих рангов по формуле:
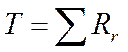
где Rr - ранговые значения сдвигов с более редким знаком.
7. Определить критические значения Т для данного n по Табл. VI Приложения 1. Если Тэмп меньше или равен Ткр , сдвиг в типичную сторону по интенсивности достоверно
преобладает.
Вопрос 4
Критерий X 2 r Фридмана
Назначение критерия
Критерий X 2 r применяется для сопоставления показателей, измеренных в трех или более условиях на одной и той же выборке испытуемых.
Критерий позволяет установить, что величины показателей от условия к условию изменяются , но при этом не указывает на направление изменений.
Описание критерия
Данный критерий является распространением критерия Т Вилкоксона на большее, чем 2, количество условий измерения. Однако здесь мы ранжируем не абсолютные величины сдвигов, а сами индивидуальные значения, полученные данным испытуемым в 1, 2, 3 и т. д. замерах.
Например, если у испытуемого в первом замере определена скорость прохождения графического лабиринта 54 сек, во втором замере - 42 сек, а в третьем замере - 63 сек, то эти показатели получат ранги, соответственно, 2, 1, 3, поскольку меньшему значению, полученному во втором замере, мы начислим ранг 1, среднему значению, полученному в первом замере - ранг 2, а наибольшему значению, полученному в третьем замере - ранг 3.
После того, как все значения будут проранжированы, подсчитываются суммы рангов по столбцам для каждого из произведенных замеров.
Если различия между значениями признака, полученными в разных условиях, случайны, то суммы рангов по разным условиям будут приблизительно равны. Но если значения признака изменяются в разных условиях каким-то закономерным образом, то в одних условиях будут преобладать высокие ранги, а в других - низкие. Суммы рангов будут достоверно различаться между собой. Эмпирическое значение критерия X 2 r и указывает на то, насколько различаются суммы рангов. Чем больше эмпирическое значение X 2 r , тем более существенные расхождения сумм рангов оно отражает.
Если X 2 r равняется критическому значению или превышает его, различия статистически достоверны.
Гипотезы
Н0 : Между показателями, полученными (измеренными) в разных условиях, существуют лишь случайные различия.
H1 : Между показателями, полученными в разных условиях, существуют неслучайные различия.
Графическое представление критерия
Графически это будет выглядеть как пучок ломаных линий с изломами в одних и тех же местах. На Рис. 3.5 представлены графики изменения времени решения анаграмм в ходе эксперимента по исследованию интеллектуальной настойчивости. Мы видим, что сырые значения пяти испытуемых дают довольно-таки рассыпающийся пучок, хо-
![]() тя и с заметной тенденцией к излому в одной и той же точке - на анаграмме № 2. На Рис. 3.6 представлены графики, построенные по ранжированным данным того же исследований. Мы видим, что здесь пучок собран практически в одну жирную линию, с единственной выбивающейся из него кривой. В сущности, критерий X
2
r
позволяет нам оценить, достаточно ли согласованно изгибается пучок при переходе от условия к условию. X
2
r
тем больше, чем более выраженными являются различия.
тя и с заметной тенденцией к излому в одной и той же точке - на анаграмме № 2. На Рис. 3.6 представлены графики, построенные по ранжированным данным того же исследований. Мы видим, что здесь пучок собран практически в одну жирную линию, с единственной выбивающейся из него кривой. В сущности, критерий X
2
r
позволяет нам оценить, достаточно ли согласованно изгибается пучок при переходе от условия к условию. X
2
r
тем больше, чем более выраженными являются различия.
Анаграмма 1: Анаграмма 2; Диаграмма 3:
КРУА АЛСТЬ ИНААМШ
Рис. 3.5. Графики изменения времени решения трех последовательно предъявлявшихся анаграмм (в сек) у пяти испытуемых

![]() Анагаамма 1: Анаграмма 2: Анаграмма 3:
Анагаамма 1: Анаграмма 2: Анаграмма 3:
КРУА АЛСТЬ ИНААМШ
Рис. 3.6. Графики изменения ранжированных показателей времени решении анаграмм
Ограничения критерия
1. Нижний порог: не менее 2-х испытуемых (п 2), каждый из которых прошел не менее 3-х замеров (с 3).
2.
При с=3, п
9,
уровень значимости полученного эмпирического значения X
2
r
определяется по Таблице V11-A Приложения 1; при с=4, n
4, уровень значимости полученного эмпирического значения X
2
r
определяется по Таблице VII-Б Приложения 1; при больших количествах испытуемых или условий полученные эмпирические значения X
2
r
сопоставляются с критическими значениями X
2
,
определяемыми
по Таблице IX Приложения 1. Это объясняется тем, что X
2
r
имеет распределение, сходное с распределением X
2
.
Число степеней свободы
определяется по формуле:
= c -1,
где с - количество условий измерения (замеров).
Пример
На Рис. 3.5. представлены графики изменения времени решения анаграмм в эксперименте по исследованию интеллектуальной настойчивости (Сидоренко Е. В., 1984). Анаграммы нужно было подобрать таким образом, чтобы постепенно подготовить испытуемого к самой трудной - а фактически неразрешимой - задаче. Иными словами, испытуемый должен был постепенно привыкнуть к тому, что задачи становятся все более и более трудными, и что над каждой последующей анаграммой ему приходится проводить больше времени. Достоверны ли различия во времени решения испытуемыми анаграмм?
Таблица 3.5
Показатели времени решения анаграмм (сек.)
| № п/п |
Код имени испытуемого |
Анаграмма 1: КРУА (РУКА) |
Анаграмма 2: АЛСТЬ (СТАЛЬ) |
Анаграмма 3: ИНААМШ (МАШИНА) |
| 1 |
Л-в |
5 |
235* |
7 |
| 2 |
П-о |
7 |
604 |
20 |
| 3 |
К-в |
2 |
93 |
5 |
| 4 |
Ю-ч |
2 |
171 |
8 |
| 5 |
Р-о |
35 |
141 |
7 |
| Суммы |
51 |
1244 |
47 |
|
| Средние |
10,2 |
248,8 |
9,4 |
*Испытуемый Л-в так и не смог правильно решить анаграмму 2.
Проранжируем значения, полученные по трем анаграммам каждым испытуемым. Например, испытуемый К-в меньше всего времени провел над анаграммой 1 - следовательно, она получает ранг 1. На втором месте у него стоит анаграмма 3 - она получает ранг 2. Наконец, анаграмма 2 получает ранг 3, потому что она решалась им дольше двух других.
Сумма рангов по каждому испытуемому должна составлять 6. Расчетная общая сумма рангов в критерии определяется по формуле:
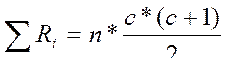
где n - количество испытуемых
с - количество условий измерения (замеров).
В данном случае,
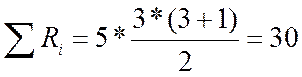
Таблица 3.6
Показатели времени решения анаграмм 1, 2, 3 и их ранги (n=5)
| Код имени испытуемого |
Анаграмма 1 |
Анаграмма 2 |
Анаграмма 3 |
|||
| Время (сек) |
Ранг |
Время (сек) |
Ранг |
Время (сек) |
Ранг |
|
| 1. Л-в |
5 |
1 |
235 |
3 |
7 |
2 |
| 2. П-о |
7 |
1 |
604 |
3 |
20 |
2 |
| 3. К-в |
2 |
1 |
93 |
3 |
5 |
2 |
| 4. Ю-ч |
2 |
1 |
171 |
3 |
8 |
2 |
| 5. Р-о |
35 |
2 |
141 |
3 |
7 |
1 |
| Суммы |
6 |
15 |
9 |
|||
Общая сумма рангов составляет: 6+15+9=30, что совпадает с расчетной величиной.
Мы помним, что испытуемый Л-в провел 3 минуты и 55 сек над решением второй анаграммы, но так и не решил ее. Поскольку он решал ее дольше остальных двух анаграмм, мы имеем право присвоить ей ранг 3. Ведь назначение трех первых анаграмм - подготовить испытуемого к тому, что над следующей анаграммой ему, возможно, придется думать еще дольше, в то время как сам факт нахождения правильного ответа не так существен.
Сформулируем гипотезы.
Н0 : Различия во времени, которое испытуемые проводят над решением трех различных анаграмм, являются случайными.
Н1 : Различия во времени, которое испытуемые проводят над решением трех различных анаграмм, не являются случайными.
Теперь нам нужно определить эмпирическое значение 2 r по формуле:
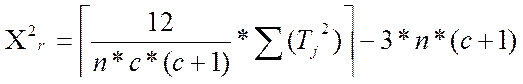
где с - количество условий;
n - количество испытуемых;
Tj - суммы рангов по каждому из условий.
Определим 2 r для данного случая:
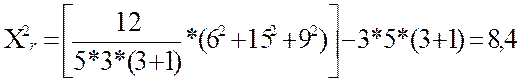
Поскольку в данном примере рассматриваются три задачи, то есть 3 условия, с=3. Количество испытуемых n=5. Это позволяет нам воспользоваться специальной таблицей 2 r , а именно Табл. VII-A Приложения 1. Эмпирическое значение 2 r = 8,4 при с=3, п=5 точно соответствует уровню значимости р==0,0085.
Ответ: Н0 отклоняется. Принимается Н1 . Различия во времени, которое испытуемые проводят над решением трех различных анаграмм, неслучайны (р=0,0085).
Теперь мы можем сформулировать общий алгоритм действий по применению критерия 2 r .
АЛГОРИТМ 10
Подсчет критерия 2 r Фридиана
1. Проранжировать индивидуальные значения первого испытуемого, полученные им в 1-м, 2-м, 3-м и т. д. замерах.
2. Проделать то же самое по отношению ко всем другим испытуемым.
3. Просуммировать ранги по условиям, в которых осуществлялись замеры. Проверить совпадение общей суммы рангов с расчетной суммой.
4. Определить эмпирическое значение 2 r по формуле:
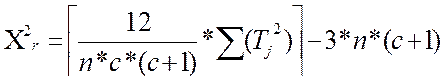
где с - количество условии;
n - количество испытуемых;
Tj - суммы рангов по каждому из условий.
5. Определить уровни статистической значимости для 2 r эмп :
а) при с=3, n 9 - по Табл. VII-A Приложения 1;
б) при с=4, n 4 - по Табл. VII-Б Приложения 1.
6. При большем количестве условий и/или испытуемых
количество степеней свободы по формуле:
= c —1,
где с - количество условии (замеров).
По Табл. IX Приложения 1 определить критические значения критерия 2 r при данном числе степеней свободы .
Если 2 r эмп равен критическому значению 2 r или превышает его, различия достоверны.
Вопрос 5
L - критерий тенденций Пейджа
Описание критерия L дается с использованием руководства J.Greene, M. DOlivera (1989).
Назначение L - критерия тенденций
Критерий L Пейджа применяется для сопоставления показателей, измеренных в трех и более условиях на одной и той же выборке испытуемых.
Критерий позволяет выявить тенденции в изменении величин признака при переходе от условия к условию. Его можно рассматривать как продолжение теста Фридмана, поскольку он не только констатирует различия, но и указывает на направление изменений.
Описание критерия тенденций L
Критерий позволяет проверить наши предположения об определенной возрастной или ситуативно обусловленной динамике тех или иных признаков. Он позволяет объединить несколько произведенных замеров единой гипотезой о тенденции изменения значений признака при переходе от замера к замеру. Если бы не его ограничения, критерий был бы незаменим в продольных, или лонгитюдинальных, исследованиях.
К сожалению, имеющиеся таблицы критических значений рассчитаны только на небольшую выборку (n 12) и ограниченное количество сопоставляемых замеров (с 6).
В случае, если эти ограничения не выполняются, приходится использовать критерий 2 r Фридмана, рассмотренный в предыдущем параграфе.
В критерии L применяется такое же ранжирование условий по каждому испытуемому, как и в критерии 2 r . Если испытуемый в первом опыте допустил 17 ошибок, во втором - 12, а в третьем - 5, то 1-й ранг получает третье условие, 2-й ранг - второе, а 3-й ранг - первое условие. После того, как значения всех испытуемых будут проранжиро-ваны, подсчитываются суммы рангов по каждому условию. Затем все условия располагаются в порядке возрастания ранговых сумм: на первом месте слева окажется условие с меньшей ранговой суммой, за ним -условие со следующей по величине ранговой суммой, и т. д., пока справа не окажется условие с самой большой ранговой суммой. Далее мы с помощью специальной формулы подсчета L проверяем, действительно ли значения возрастают слева направо. Эмпирическое значение критерия L отражает степень различия между ранговыми суммами, поэтому чем выше значение L, тем более существенны различия.
Гипотезы
Н0 : Увеличение индивидуальных показателей при переходе от первого условия ко второму, а затем к третьему и далее, случайно.
Н1 : Увеличение индивидуальных показателей при переходе от первого условия ко второму, а затем к третьему и далее, неслучайно. При формулировке гипотез мы имеем в виду новую нумерацию
условий, соответствующую предполагаемым тенденциям.
Графическое представление критерия
Используем для иллюстрации пример с предъявлением анаграмм предположительно возрастающей сложности. Замысел экспериментатора состоял в том, чтобы каждая последующая задача требовала от испытуемых все более длительных раздумий.
Судя по графику на Рис. 3,6, у большинства испытуемых анаграмма 1 стоит на первом ранговом месте, то есть решается быстрее двух других, анаграмма 3 на 2-м ранговом месте, а анаграмма 2 - на 3-м. По-видимому, их следовало бы предъявлять в иной последовательности: 1, 3, 2. График, отражающий такую гипотетическую последовательность задач, представлен на Рис. 3.7 .

Анаграмма 1: Анаграмма 3: Анаграмма 2:
КРУА ИНААМШ АЛСТЬ
Рис. 3.7. Графики изменения показателей времени решения (сек.) анаграмм пятью испытуемыми в новой (гипотетической) последовательности их предъявления
Символом достоверной, отчетливой тенденции в изменении показателей при переходе от условия к условию будет достаточно собранная ломаная кривая, устремленная кверху или, наоборот, книзу. Если на Рис. 3.6 характерной чертой всех индивидуальных кривых был крутой излом в одной и той же точке графика, то в данном случае на некоторых отрезках повышение кривой характеризуется большей крутизной, а на других - меньшей крутизной. Очевидно, достоверность тенденций будет обеспечиваться именно отрезками более крутого восхождения, но тест тенденций снисходительно распространит этот эффект и на более пологие отрезки.
На Рис. 3.8 графики представлены уже для ранжированных показателей. Здесь уже все различия в крутизне сглажены. L -тест построен на сопоставлении сумм рангов, а ранжирование неизбежно несколько огрубляет полученные показатели. Опыт показывает, однако, что L-тест является достаточно мощным критерием, хотя и ограниченным по сфере применения из-за отсутствия таблиц критических значений для больших n.
Анаграмма1: Анаграмма 3: Анаграмма 2:
КРУА ИНААМШ АЛСТЬ
Рис. 3.8. Графики изменены ранжированных показателен времени решения анаграмм пятью испытуемыми в новой (гипотетической) последовательности их предъявления
Ограничения критерия Пейджа
1. Нижний порог - 2 испытуемых, каждый из которых прошел не менее 3-х замеров в разных условиях. Верхний порог - 12 испытуемых и 6 условий (n 12, с 6). Критические значения критерия L даны по руководству J.Greene, M. DOlivera (1989). Они предусматривают три уровня статистической значимости: р 0,05; р 0,01; р 0,001.
2. Необходимым условием применения теста является упорядоченность столбцов данных: слева должен располагаться столбец с наименьшей ранговой суммой показателей, справа - с наибольшей. Можно просто пронумеровать заново все столбцы, а потом вести расчеты не слева направо, а по номерам, но так легче запутаться.
Пример
Продолжим рассмотрение примера с анаграммами. В Табл. 3.7 показатели времени решения анаграмм и их ранги представлены уже в упорядоченной последовательности, анаграмма 1, анаграмма 3, анаграмма 2. Действительно ли время решения увеличивается при такой последовательности предъявления анаграмм?
Таблица 3.7
Показатели времени решения анаграмм 1, 3, 2 и их ранги ( n =5)
| Код имени испытуемого |
Условие 1: Анаграмма 1 |
Условие 2: Анаграмма 3 |
Условие 3: Анаграмма 2 |
||||
| Время (сек) |
Ранг |
Время (сек) |
Ранг |
Время (сек) |
Ранг |
||
| 1 |
Л-в |
5 |
1 |
7 |
2 |
235 |
3 |
| 2 |
П-о |
7 |
1 |
20 |
2 |
604 |
3 |
| 3 |
К-в |
2 |
1 |
5 |
2 |
93 |
3 |
| 4 |
Ю-ч |
2 |
1 |
8 |
2 |
171 |
3 |
| 5 |
Р-о |
35 |
2 |
7 |
1 |
141 |
3 |
| Суммы |
51 |
6 |
47 |
9 |
1244 |
15 |
|
| Средние |
10,2 |
9,4 |
289 |
||||
Сумма рангов составляет: 6+9+5=30. Расчетная сумма:
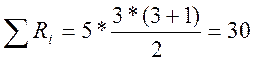
Реально полученная и расчетная суммы совпадают, мы можем двигаться дальше.
Как видно из Табл. 3.7, среднее время решения анаграммы 3 даже меньше, чем анаграммы 1. Однако мы исследуем не среднегруп-повые тенденции, а степень совпадения индивидуальных тенденций. Нам важен именно порядок, а не абсолютные показатели времени. Поэтому и формулируемые нами гипотезы - это гипотезы о тенденциях изменения индивидуальных показателей.
Сформулируем гипотезы.
Н0 : Тенденция увеличения индивидуальных показателей от первого условия к третьему является случайной.
H1 : Тенденция увеличения индивидуальных показателей от первого условия к третьему не является случайной. Эмпирическое значение L определяется по формуле:
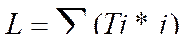
где Tj - сумма рангов по каждому условию;
j - порядковый номер, приписанный каждому условию в новой последовательности ,
Lэмп =(6*1)+(9*2)+(15*3)=69
По Табл. VIII Приложения 1 определяем критические значения L для данного количества испытуемых: n=5, и данного количества условий: с=3.
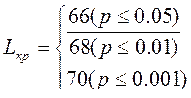
Построим ось значимости
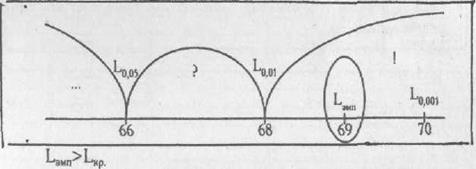
Ответ: Н0 отклоняется. Принимается Н1 . Тенденция увеличения индивидуальных показателей от первого условия к третьему не является случайной (р0,01). Последовательность анаграмм: 1(КРУА), З(ИНААМШ), 2(АЛСТЬ), - будет в большей степени отвечать замыслу экспериментатора о постепенном возрастании сложности задач, чем первоначально применявшаяся последовательность.
АЛГОРИТМ 11
Подсчет критерия тенденций L Пейджа
1. Проранжировать индивидуальные значения первого испытуемого, полученные им в 1-м, 2-м, 3-м и т. д. замерах.
При этом первым может быть любой испытуемый, например первый по алфавиту имен.
2. Проделать то же самое по отношению ко всем другим испытуемым.
3. Просуммировать ранги по условиям, в которых осуществлялись замеры. Проверить совпадение общей суммы рангов с расчетной суммой.
4. Расположить все условия в порядке возрастания их ранговых сумм в таблице.
5. Определить эмпирическое значение L по формуле:
где Tj - сумма рангов по данному условию;
j - порядковый номер, приписанный данному условию в упорядоченной последовательности условий.
6. По Табл. VIII Приложения 1 определить критические значения L для данного количества испытуемых n и данного количества условий с.
Если Lэмп равен критическому значению или превышает его, тенденция достоверна.
Вопрос 6. Алгоритм принятия решения о выборе критерия оценки изменений