Мікропроцесори архітектури Alpha, Sparc, Majc, Sharc
СОДЕРЖАНИЕ: Мікропроцесори архітектури сімейств Alpha, Sparc, Majc, Sharc: структура мікропроцесорів, принцип дії та особливості циклів виконання команд. Напрямки розвитку архітектури, реалізація памяті. Структурна схема та призначення функціональних блоків.Зміст
Вступ
1. Мікропроцесори архітектури ALPHA
1.1 Структура мікропроцесора 21264 и особливості виконання команд
1.2 Структура мікропроцесора 21364 у організації ММПС
2. Мікропроцесори архітектури SPARC
2.1 Напрямки розвитку архітектури. Реалізація памяті
2.2 Архітектура UltraSparc
3. Архітектура MAJC, SHARC
3.1 Структурна схема MAJC та призначення функціональних блоків
3.2 Архітектура SHARC сімейства ADSР-2106x
3.2.1 Мікропроцесор TigerSHARC - ADSP-TS001
3.2.2 Мікропроцесор ADSP-21535 Blackfin
Висновок
Література
Вступ
Тема реферату Мікропроцесори архітектури ALPHA, SPARC, MAJC, SHARC з дисципліни Мультимікропроцесорні системи.
Мультимікропроцесорні системи (ММПС) - це системи, що мають два й більше компонент, які можуть одночасно виконувати команди. Підпорядкованими процесорами можуть бути спецпроцесори, розраховані на виконання певного типу завдання або процесори широкого застосування. Спецпроцесори - співпроцесори, процесори вводу-виводу.
Мета роботи - розглянути структуру та принцип дії мікропроцесорів архітектури ALPHA, SPARC, MAJC, SHARC.
1. Мікропроцесори архітектури ALPHA
Концепція розробки даної архітектури отримала назву Spead Daemon - досягнення високої продуктивності за рахунок збільшення тактової частоти при відносно простій логіці функціонування. Перший мікропроцесор ALPHA 21064 (1993 р.) призначався для високопродуктивних робочих станцій і серверів. По нинішній час компанія DEC є лідером при порівнянні продуктивності власних мікропроцесорів і мікропроцесорів фірми Intel. При розробці застосовується концепція Brainiac, яка припускає складний механізм динамічного виконання команд.
Виконання команд мікропроцесора включає наступні цикли - вибірка команд з урахуванням прогнозів переходів, передача даних для команди в пристрій перейменування (відображення) регістрів, виконання перейменування (відображення) регістрів, вибір команд із черг на виконання, виконання команд з фіксованою або плаваючою крапкою, запис результатів виконання.
1.1 Структура мікропроцесора 21264 и особливості виконання команд
Для динамічного виконання розглядається відразу 80 команд (більше, ніж у будь-якого іншого мікропроцесора). Після декодування команда потрапляє в необхідну їй чергу. Команди, отримавши необхідні їм операнди для виконання, конкурують за доступ до виконавчих пристроїв і більший пріоритет мають команди, що знаходяться в черзі довше за всіх. Одночасно можуть виконуватися відразу шість команд.
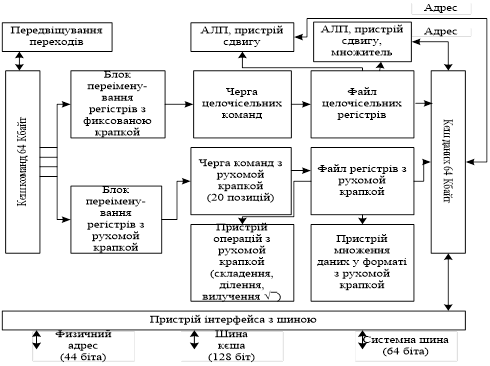
Малюнок 1. Структура мікропроцесора ALPHA 21264
1.2 Структура мікропроцесора 21364 у організації ММПС
Наступний представник даного сімейства мікропроцесор 21364, але оскільки в його розробці брали участь відразу декілька фірм (DEC, Compag, Hewlett Packard), основним його власником є фірма Hewlett Packard. Випуск даного мікропроцесора здійснений в 2002-2003 рр. Ядром є ядро мікропроцесора 21264 і внесені різні структурні поліпшення.
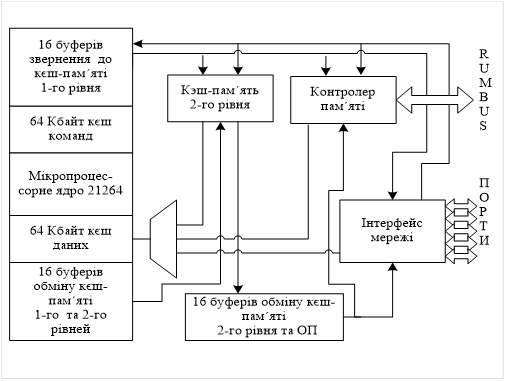
Малюнок 2. Структура мікропроцесора ALPHA 21364
Кеш-память другого рівня є 6-ти входовою множинно-асоціативною, місткістю 1,75 Мб. Контролер памяті - 8-канальний, динамічний, тип обслуговуваємой памяті - Direct Rambus. Швидкість обміну мікропроцесора з оперативною памяттю - 12,8 Гбайт/с. Завдяки вбудованому мережному інтерфейсу спрощується обєднання мікропроцесорів у високопродуктивну мультипроцесорну систему. Мережний інтерфейс підтримує 4 лінка, швидкість роботи кожного - 6,4 Гбайта/с. Затримка обмінних операцій через лінк, не більше 15 ns. Реалізований протокол когерентності в МПС, а також асинхронний обмін даними.
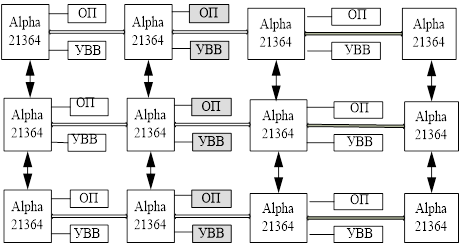
Малюнок 3. Схема зєднання 12 мікропроцесорів 21364 в ММПС
2. Мікропроцесори архітектури SPARC
2.1 Напрямки розвитку архітектури. Реалізація памят і
Архітектура SPARC була створена компанією Sun в 1985 р. За основу була прийнята концепція регістрових вікон, що спрощує створення однопрохідних компіляторів і істотно знижуюча кількість команд звернення до памяті в порівнянні з іншими реалізаціями RISC архітектури.
На даний момент існують 4 лінії розвитку даної архітектури:
MicroSparc - 32 розрядні;
SuperSparc - 32 розрядні;
HiperSparc - 32 розрядні;
UltraSparc - 64 розрядні.
Основними рисами архітектури є:
підтримка лінійного 32-розрядного адресного простору;
використовування 32-розрядних команд фіксованої структури з трьома базовими форматами;
реалізація доступу до памяті і вводу/виводу за допомогою команд завантаження/збереження;
невелика кількість способів адресації (регістр-регістр, регистр - беспосередній операнд);
використовування триадресних регістрових команд. Велика частина команд виконується над двома операндами, результат поміщається в регістр приймач;
великий регістровий файл з регістровими вікнами. В кожен момент часу доступно 8 глобальних цілочисельних регістрів і регістрове вікно (24 регістри), що відображається на регістровий файл. Використовування регістрових вікон дозволяє значно скоротити невигідні витрати, повязані з перемиканням контекста при виконанні паралельних процесів;
мікропроцесор архітектура функціональний блок
окремий регістровий файл для операндів рухомої крапки (як набір з 32-32-розрядних регістрів для одинарної точності або 16 64-розрядних регістрів подвійної точності, 8 128-розрядних регістрів збільшеної учетверо точності або як суміш регістрів різної точності);
відкладена передача управління. Процесор завжди вибирає команду, наступну за командою відкладеної передачі управління. Ця команда може бути виконаний чи ні, залежно від стану аннулирующего розряду в команді передачі управління;
швидкі обробники переривань. Генерація переривань приводить до формування в регістровому файлі нового регістрового вікна;
тегіровані команди. Ці арифметичні команди інтерпретують два молодші значущі розряди операндів, як інформацію про типи операндів. Ці команди встановлюють біт переповнювання в регістрі стану при арифметичному переповнюванні або у разі коли який-небудь з теговых бітів операндів не рівний нулю. Є варіанти команд, які за вказаних умов генерируют переривання;
команди міжпроцесорної синхронізації - одна команда виконує безперервну операцію читання з подальшим записом, інша команда виконує безперервний обмін вмісту регістра і памяті;
підтримка співпроцесора (простий набір команд співпроцесора, який може використовуватися наряду з АЛУ);
двійкова сумісність програм користувачів у всіх реалізаціях архітектури.
Склад процесора - цілочисельний пристрій, пристрій для формату ПТ, співпроцесор. Кожний пристрій має свій набір регістрів, які мають фіксовану довжину - 32 біт.
Режими роботи - призначений для користувача і привілейований (виконання - аналог 486) При зверненні до памяті адреса доповнюється ідентифікатором адресного простору, який містить інформацію про режим роботи процесора, а також про те до якої памяті (команд або даних) здійснюється обіг.
Конкретна апаратна реалізація цілочисельного пристрою може містити від 40 до 520 32-розрядних регістра загального призначення, які розбиті на групи з восьми глобальних регістрів і циклічного стека, що містить набір від 2-х до 32-х наборів по 16 регістрів в кожному (регістрове вікно). В кожний момент часу виконуваній програмі доступно вісім глобальних регістрів і регістрове вікно (24 регістри). Регістри вікна розбиті на три групи; восьми вхідних, восьми локальних і восьми вихідних, які в той же час є вхідними регістрами суміжного вікна (тобто сусідні вікна перекриваються на 8 регістрів). Поточне вікно задається полем покажчика поточного вікна в слові стану процесора.
В даній архітектурі реалізована стандартна модель памяті, що має повну назву - повне впорядковування обігу (TSO - Total Store Ordering). Дана модель застосовна як до однопроцесорних так і до багатопроцесорних систем із загальною памяттю. Реалізація даної моделі дає гарантію, що всі команди запису, сбросу і безперервні команди читання/запису на всіх процесорах відпрацьовуються памяттю серіями в тому порядку, в якому вони завершуються процесором. Підтримується також додаткова модель памяті - часткове впорядковування обігу (PSO - Partial Store Ordering), яка у ряді випадків дозволяє підвищити продуктивність систем.
2.2 Архітектура UltraSparc
В даній архітектурі вперше функції по обробці графічних і відео зображень реалізовані апаратний, через окремий модуль для обробки графіки і відеозображень.
Основний набір блоків наступний:
пристрій видачі команд, що включає кеш-память команд, чергу команд, логіку управління;
цілочисельний пристрій (логіка залежності, конвейєрне АЛУ, файл робочих і архітектурних регістрів). Рознесення робочих і архітектурних регістрів зроблений з наступною метою - результат неврегульований, але виконання операцій, записаних в робочі регістри або може бути відмінено або переписано в архітектурні регістри;
пристрій з рухомою комою (множення, складання, віднімання, графічний пристрій);
кеш-память даних;
пристрій зовнішньої памяті (контроллер SDRAM, теги зовнішньої памяті, контроллер SRAM;
системний інтерфейс, що складається з контроллера обмінних операцій памяті і контроллера перемикання даних.
3. Архітектура MAJC, SHARC
Архітектура MAJC розроблена фірмою Sun і призначена для використовування в системах обробки мультимедійних даних і виконання Internet - додатків.
MAJC 5200 складається з двух 128-розрядних VLIW (Very - Long Instruction Word) мікропроцесорних ядра, інтегрованих на одному кристалі. В даному мікропроцесорі реалізовано 4 рівні паралелізму (мультитредова структура кристала, мультитредове виконання програми, VLIW - паралелізм на рівні команд, SIMD обробка даних). Система команд RISC - процесорів орієнтована на потокову обробку мультимедійної інформації і апаратну підтримку високорівневої конструкції мови Java. Сама назва MAJC утворена від Microprocessor Architecture for Java Computing - микропроцессорна обробка для обчислень на Java. Дана архітектура є тією, що масштабується. На одному кристалі MAJC може розташовуватися декілька ідентичних процесорів залежно від конкретної реалізації, кожний з яких містить від одного до чотирьох функціональних блоків - RISC - процесорів і кеш - команд. Кожний з розташованих на кристалі процесорів може виконувати до 4 команд за такт.
3.1 Структурна схема MAJC та призначення функціональних блоків
Крім функціональних блоків і кєшів команд (16 Кб) на кристалі розташовані: загальний для процесорів кєш даних (16 Кб), контролер PCI, контролер Rambus - памяті, графічний препроцесор, 64-розрядні високошвидкісні інтерфейси для між процесорних зєднань і підключення графічної підсистеми, а також комутатор, обєднуючий процесори і всю решту компонентів кристала.
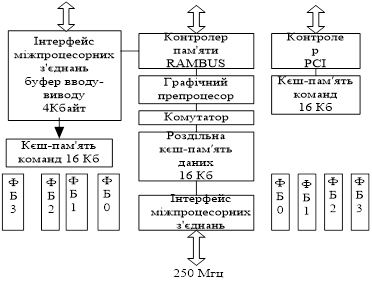
Малюнок 4. Структурна схема MAJC
Командне слово MAJC обєднує від однієї до чотирьох 32-розрядних команд, кожна з яких призначена для одного з 4 процесорів. У тому випадку, коли не представляється можливим одночасно задіяти всі процесори, окремі команди можуть бути відсутні, тому командне слово MAJC може мати змінну довжину. Для вказівки кількості команд в слові використовуються його перші два біти: 00 - 1 команда, 01 - 2 команди, 10 - 3 команди, 11 - 4 команди. Призначення команд здійснюється в порядку номерів функціональних блоків.
Один з функціональних блоків (номер 0) відрізняється по виконуваних командах від трьох інших (номери з 1 по 3). Крім АЛП команд, він виконує команди завантаження/збереження і команди переходів. АЛП команди виконуються над даними у форматах: цілочисельному (8-,16-,32-.64 - біт), з фіксованою крапкою (16 біт) і рухомою крапкою (32-,64-бит), а також бітовими послідовностями. Є команди SIMD-обробки пар даних у форматі з фіксованою точкою 16-біт.
Кожний процесор має файл локальних регістрів, логіку управління (декодування) команд, і регістри стану. Є також глобальні регістри доступні для всіх процесорів. Реалізована в мікропроцесорі апаратна підтримка мультітредового виконання програми передбачає можливість одночасного виконання до 4-х потоків команд.
3.2 Архітектура SHARC сімейства ADSР-2106x
Дане сімейство, дуже східне з раніше розглянутими мікропроцесорами ADSC-210хx по структурі ядра і сумісним знизу-вверх за системою команд, проте володіє істотними архітектурними відмінностями, що дозволило розробникам виділити їх в окреме сімейство SHARC (Super Harvard Architecture Computer). Архитектура SHARC продовжує розвиток трансп`ютерного напрямку в мікропроцесорній техніці і задає новий стандарт інтеграції сигнальних процесорів в мультіпроцесорну систему. Ця архітектура є прикладом гармонійного поєднання принципів побудови розподілених і звязаних систем, обєднуючи в собі простоту і ефективність масштабування розподілених систем із зручністю програмування систем з памяттю, що розділяється.
В SHARC - мікропроцесорі зєднані високоефективне процесорне ядро, що виконує обробку даних у форматі з рухомою крапкою, інтерфейс з хост-процесором, контролер ПДП, послідовні порти, комутаційні линки і шина, що розділяється.
Шинний комутатор сполучає ядро процесора з незалежним процесором вводу-виводу, двухвходовой памяттю і портом шини мультіпроцесорної системи. Загальний простір мікропроцесора, що адресується, складає 4 Гслова. Встроєний контролер зовнішньої оперативної памяті дозволяє задавати різне число тактів очікування, що генеруються, і підтримує сторінковий обмін з динамічною памяттю.
Інтерфейс з хост-процесором забезпечує просте зєднання із стандартною 16 - або 32 - розрядною мікропроцесорною шиною. Передача даних через інтерфейс здійснюється асихронно, з швидкістю, обмеженою тактовою частотою мікропроцесора. Хост-інтерфейс доступний через зовнішній порт і відображається в адресний простір мікропроцесора. Чотири канали ПДП забезпечують обмін даними і командами через хост-інтерфейс з мінімальною участю процесорного ядра.
Розташований на кристалі 10-канальний контролер ПДП забезпечує обмін даними між внутрішньою і зовнішньою памяттю, периферійними пристроями, хост-процесором, послідовними портами і линками мікропроцесора. Мікропроцесор має два синхронні послідовні порти для звязку з різноманітними периферійними пристроями. Максимальна швидкість передачі даних через послідовний порт складає 40 Мбіт/с. Передача може здійснюватися одночасно в двох напрямах в режимі ПДП. В процесі обміну може виконуватися додаткове перетворення даних, таке як - або А - командування.
Дана архітектура надає розробникам широкі можливості по створенню мультіпроцесорних сигнальних систем. Загальний адресний простір може бути розділений межу декількома процесорами. Забезпечується автоматична підтримка семафорів для послідовностей операцій читання - модифікація - запис в память. Вбудована розподілена шинна логіка дозволяє створювати системи, що містять до 6-ти взаємодіючих процесорів і хост-процесор. Міжпроцесорне управління здійснюється за допомогою механізму переривань.
Додаткові можливості вводу-виводу процесору надають шести 4-розрядних лінков. Лінки передають дані по передньому і задньому фронту тактового імпульсу, забезпечуючи, таким чином, передачу 8 біт за такт. Лінки використовуються в мультипроцесорних системах для зєднання типу крапка-крапка, Передача даних по лінку може здійснюватися 32-х або 48-ми розрядними словами безпосередньо в процесорне ядро, або, з використанням ПДП каналів, у внутрішню память. Кожний линк містить власні буферні вхідні і вихідні регістри. Максимальна швидкість міжпроцесорного обміну через линки або зовнішній порт складає 240 Мбайт/с.
Лінки мікропроцесора.
Кожен лінк складається з 4 двонаправлених ліній даних і двох двонаправлених управляючих ліній, що забезпечують асинхронну передачу в режимі запрос - відповідь. Порти на протилежних кінцях лінка настроюються на передачу і прийом, або знаходяться в третьому стані. Порт кожного лінка може вибрати для передачі або прийому один з шести буферів. Дані читаються або пишуться в буфери під управлінням або КПДП або центрального процесора. Алгоритм роботи КПДП не відрізняється від стандартного, а саме - він програмується для роботи з буфером шляхом завдання розміру буфера, початкової адреси в памяті, приростом адреси, а також напрями передачі, Коли контроллер ПДП завершує операцію, виробляється переривання, індивідуальне для кожного з 10 ПДП каналів.
Буфери можуть бути прочитані або доповнені процесором за допомогою операцій читання/запису в області памяті зовнішніх пристроїв. Якщо робиться спроба читання з порожнього буфера, процесор повинен перейти в стан очікування до тих пір, поки не поступлять дані ззовні. При записі в заповнені буфери операція повинна припинитися, аж до появи вільного місця в буфері.
В системах, в яких затримка, що вноситься контроллером ПДП, неприпустимо велика, процесор повинен працювати безпосередньо з буферами, а контролер ПДП переведений в неактивний стан.
При роботі лінків генеруються наступні переривання:
якщо канал ПДП активізований, то по завершенню передачі повідомлення ПДП каналом виробляється масковане переривання;
генерується масковане переривання, якщо ПДП контролер не активізований, а приймаючий буфер не порожній або передаючий буфер не повний. По перериванню потрібне виконання операцій з буфером;
масковане переривання, яке генерується при зовнішньому доступі в порт лінка, який не активізований.
Кожний буфер складається з внутрішнього і зовнішнього регістрів. При передачі внутрішній регістр використовується для прийому даних з внутрішньої памяті під управлінням ПДП контролера або ЦП. Зовнішній регістр використовується для розпаковування півбайтів для портів линка (старший півбайт слідує першим) Ці два регістри формують FIFO-чергу. При прийомі зовнішній регістр упаковує півбайти, що приймаються, в слова і передає їх через внутрішній регістр в память під управлінням ПДП контролера або ЦП. Якщо ПДП або ЦП не встигли витягнути дані з буфера прийом припиняється. Довжина регістрів настроюється програмно і складає 32 або 48 біт.
Перш, ніж два процесори починають взаємодіяти по звязуючому їх лінку, повинне бути визначений - хто з процесорів передаватиме дані, а хто приймати. Для цього використовується обмін маркером. При початковій установці маркер (програмно-доступний прапор) встановлюється в одному з процесорів, визначаючи його як господаря (master) лінка і дозволяючи йому передачу. Якщо приймаючий порт бажає стати господарем лінка для передачі даних, він повинен виставити сигнал на лінії запиту даних для поточного господаря лінка. Господар, використовуючи програмний протокол, визначає, коли приходить сигнал підтвердження даних, а коли запит на отримання маркера.
Якщо господар вирішив передати маркер, він посилає назад визначений користувачем як маркер ідентифікатор і скидає власний маркер. Одночасно відомий процесор перевіряє отримані дані і, якщо, в них міститься певне слово, то він встановлює свою мітку, переходячи в стан провідного процесора. Якщо отримані дані не містять необхідного ідентифікатора, то відомий процесор повинен зрозуміти, що ведучий починає нову передачу даних.
Виявлення помилок при передачі.
В спеціальному управляючому регістрі зберігається інформація про стан лічильника півбайтів кожного порту лінка. Якщо після закінчення передачі лічильник не обнулений, то виробляється сигнал, що свідчить про виявлення помилки при передачі. Для контролю цього сигналу застосовуються спеціальні протоколи на передаючому і приймаючому кінцях лінка.
3.2.1 Мікропроцесор TigerSHARC - ADSP-TS001
Шлях подальшого підвищення продуктивності компанія Analog Devices повязує із статичним виявленням паралелізму рівня команд. ADSP-TS001 - перший мікропроцесор з новою статичною суперскалярною архітектурою, поєднуючої можливості цифрової обробки сигналів з особливостями RISC і VLIW. В ньому придержуються на високому рівні властиві процесорам ЦОС характеристики, як короткий машинний такт, швидка реакція на переривання і ефективний інтерфейс з периферійними пристроями. Це досягається використовуванням VLIW - підходу до планування завантаження функціональних блоків (виявленню паралелізму рівня команд на етапі компіляції і можливість незалежного завдання в програмі порядку завантаження функціональних блоків) і RISC - підходу до виконання команд (фіксована структура команди, конвейєрне виконання за один такт до 4 32-розрядних операцій над даними в регістровому файлі, прогноз переходів і т.д.)
Основні характеристики мікропроцесора ADSP-TS001:
6 Мбіт вбудованої SRAM, загальної для даних і команд (відмінність від традиційної гарвардської архітектури);
адресний простір до 4 Гбайт;
вбудований контроллер динамічної памяті SDRAM;
швидкість передачі даних через зовнішню шину 600 Мбайт/с;
можливість обєднання в багатопроцесорну конфігурацію (до 8-ми процесорів) без використовування додаткових інтерфейсних схем;
4 порти вводу-виводу.
Разом із зовнішньою шиною для взаємодії між процесорами можуть використовуватися порти звязку. Передача даних через порти звязку виконується окремим процесором вводу-виводу і не вимагає втручання центрального процесора. Даний спосіб не має обмежень по числу взаємодіючих процесорів і володіє великою гнучкістю, проте забезпечує меншу пропускну спроможність.
3.2.2 Мікропроцесор ADSP-21535 Blackfin
Сумісне виробництво фірм Analog Devices і Intel і перший представник сімейства мікропроцесорів Blackfin, з мікросигнальною архітектурою (поєднання в одному мікропроцесорі можливостей сигнальної обробки, SIMD обробки мультимедійних даних і RISC подібного набору команд.
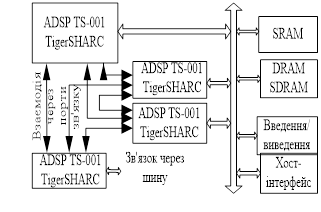
Малюнок 5. Використання ADSP-TS001 в багатопроцесорних системах
Структура мікропроцесора Blackfin (ADSP-21535)
Ядро ADSP-21535 складається з трьох компонентів: пристрій обчислення адреси, пристрої управління, і пристрої обробки даних. Пристрій обчислення адреси містить два генератори адреси (DAG0, DAG1), використовуючі загальний регістровий файл. Регістровий файл включає 4 набори регістрів: індексний, модифікатор, довжини, бази. Вісім додаткових 32-розрядних регістра можуть використовуватися спільно з основними індексними регістрами як покажчики позицій стека і памяті. Пристрій управління містить блок формування послідовності команд, блоки виділення і декодування команд, а також буфер команд циклу (для локального збереження команд з метою скорочення числа звернень до памяті команд). Пристрій обробки даних містить 9 обчислювальних пристроїв: два блоки виконання операцій множення з накопиченням, два 40-розрядних АЛП, 4 видео - АЛП і пристрій барабанного зсуву. Обчислювальні пристрої обробляють 8-, 16-, 32-розрядні дані, що містять в регістровому файлі.
На кристалі, крім процесорного ядра, містяться 256 Кб статичної памяті, контроллер ПДП, контроллер переривань, блок інтерфейсу системної шини, память завантаження, таймери, контроллер зовнішньої памяті, контролер шини PCI, інтерфейс USB, універсальний асинхронний інтерфейс UART, блок емуляції і відладки JTAG.
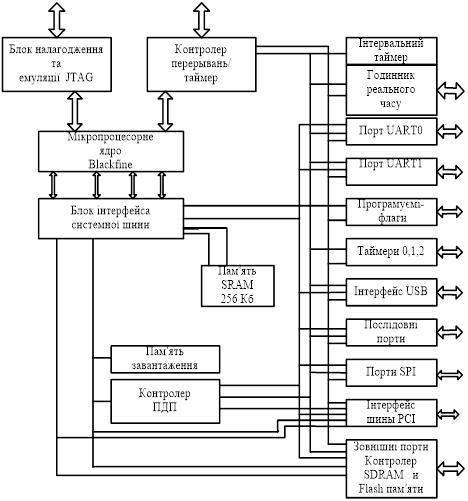
Малюнок 6. Структура мікропроцесора Blackfin
У мікропроцесорі реалізована модифікована гарвардська архітектура в комбінації з ієрархічною структурою памяті. Вся память мікропроцесора розглядається як уніфікований адресний простір розміром до 4 Гб. Перший рівень ієрархії памяті працює на частоті ядра і має мінімальний час доступу. Місткість памяті команд цього рівня - 16 Кб. Память даних цього рівня (два банки по 16Кб) містить, разом з даними, стек і локальні змінні. До цього ж рівня відноситься внутрішня память проміжних результатів розміром 4 Кб. Память першого рівня може бути конфігурована як швидка память прямого доступу або як кєш-память. Память другого рівня - внутрішня SRAM (256 Кб), доступ до якої здійснюється за декілька процесорних тактів. Память цього рівня є загальною як для команд так і для даних.
Висновок
У роботі були розглянути структурні схеми та архітектура мікропроцесорів архітектури ALPHA, SPARC, MAJC, SHARC, принцип дії.
Література
1. Б.В. Шевкопляс Микропроцессорные структуры. Инженерные решения М.: Радио и связь, 1990
2. В. Шевкопляс Микропроцессорные структуры. Инженерные решения. Дополнение первое. М.: Радио и связь, 1993
3. М. Гук Аппаратные средства IBM PC С. Петербург Питер 2000
4. В. Корнеев, А. Киселев Современные микропроцессоры Санкт-Петербург, БХВ - Петербург 2003
5. Локазюк В.М. и др Микропроцессоры и микроЭВМ в производственных системах Киев Издательский центр Академия 2002
6. В.В. Сташин, А.В. Урусов, О.Ф. Мологонцева Проектирование цифровых устройств на однокристальных микроконтроллерах Л. Энергоатомиздат
7. Под ред. А.Д. Викторова Руководство пользователя по сигнальным микропроцессорам семейства ADSP-2100 Санкт - Петербургский государственный электротехнический университет. Санкт - Петербург 1997
8. М. Предко Руководство по микроконтроллерам в 2-х томах М: Постмаркет, 2001