на тему: Язык xml. Язык запросов X query
СОДЕРЖАНИЕ: Этот язык используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документовМинистерство образования Республики Беларусь
Белорусский Государственный Университет
Экономический факультет
Кафедра экономической информатики и математической экономики
Реферат на тему:
Язык XML. Язык запросов X - Query .
Выполнили:
студентки 1 курса
отделения Менеджмент
Герасимова Серафима Валерьевна
Бизунова Вера Владимировна
Научный руководитель
Кожич П.П.
Минск 2007
Содержание
Возникновение языка XML и его задачи. 7
Объектная модель документа (DOM) 14
Определение типа документа(DTD) 25
Пример корректного XML- документа: 27
Модель содержимого элемента. 35
Использование правил из внешних схем. 38
Иллюстрация запросной модели. 45
Операции над последовательностями. 60
Основные элементы путей адресации. 69
Способы просмотра XML-документов. 77
Отображение XML во Всемирной паутине. 78
DTD-определение для XML-документа. 84
Введение
XML (Extensible Markup Language) - это новый SGML-производный язык разметки документов, позволяющий структурировать информацию разного типа, используя для этого произвольный набор инструкций.
XML предназначен для хранения структурированных данных (взамен существующих файлов баз данных), для обмена информацией между программами, а также для создания на его основе более специализированных языков разметки (например, XHTML), иногда называемых словарями. XML является упрощённым подмножеством языка SGML.
XML - это язык разметки, описывающий целый класс объектов данных, называемых XML- документами. Этот язык используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов.
Спецификация XML была предложена консорциумом W3C (организацией по стандартизации новых Web-технологий) в качестве рекомендации, утверждена в 1998 году.
Сегодня XML может использоваться в любых приложениях, которым нужна структурированная информация - от сложных геоинформационных систем, с гигантскими объемами передаваемой информации до обычных однокомпьютерных программ, использующих этот язык для описания служебной информации. Можно выделить множество задач, связанных с созданием и обработкой структурированной информации, для решения которых может использоваться XML:
• В первую очередь, эта технология может оказаться полезной для разработчиков сложных информационных систем, с большим количеством приложений, связанных потоками информации самой различной структурой. В этом случае XML - документы выполняют роль универсального формата для обмена информацией между отдельными компонентами большой программы.
• XML является базовым стандартом для нового языка описания ресурсов, RDF, позволяющего упростить многие проблемы в Web, связанные с поиском нужной информации, обеспечением контроля за содержимым сетевых ресурсов, создания электронных библиотек и т.д.
• Язык XML позволяет описывать данные произвольного типа и используется для представления специализированной информации, например химических, математических, физических формул, медицинских рецептов, нотных записей, и т.д. Это означает, что XML может служить мощным дополнением к HTML для распространения в Web нестандартной информации. Возможно, в самом ближайшем будущем XML полностью заменит собой HTML, по крайней мере, первые попытки интеграции этих двух языков уже делаются (спецификация XHTML).
• XML-документы могут использоваться в качестве промежуточного формата данных в трехзвенных системах. Обычно схема взаимодействия между серверами приложений и баз данных зависит от конкретной СУБД и диалекта SQL, используемого для доступа к данным. Если же результаты запроса будут представлены в некотором универсальном текстовом формате, то звено СУБД, как таковое, станет прозрачным для приложения. Кроме того, сегодня на рассмотрение W3C предложена спецификация нового языка запросов к базам данных XQL, который в будущем может стать альтернативой SQL.
• Информация, содержащаяся в XML-документах, может изменяться, передаваться на машину клиента и обновляться по частям. Разрабатываемые спецификации XLink и Xpointer позволят ссылаться на отдельные элементы документа c учетом их вложенности и значений атрибутов.
• Использование стилевых таблиц (XSL) позволяет обеспечить независимое от конкретного устройства вывода отображение XML- документов.
• XML может использоваться в обычных приложениях для хранения и обработки структурированных данных в едином формате.
XML-документ представляет собой обычный текстовый файл, в котором при помощи специальных маркеров создаются элементы данных, последовательность и вложенность которых определяет структуру документа и его содержание. Основным достоинством XML документов является то, что при относительно простом способе создания и обработки (обычный текст может редактироваться любым тестовым процессором и обрабатываться стандартными XML анализаторами), они позволяют создавать структурированную информацию, которую хорошо понимают компьютеры.
XML позволяет описывать и передавать такие структурированные данные, как:
• отдельные документы;
• метаданные, описывающие содержимое какого-либо узла Internet ;
• объекты, содержащие данные и методы работы с ними (например, элементы управления ActiveX или объекты Java);
• отдельные записи (например, результаты выполнения запросов к базам данных);
• всевозможные Web-ссылки на информационные и людские ресурсы Internet (адреса электронной почты, гипертекстовые ссылки и пр.).
Возникновение языка XML и его задачи
Язык XML был разработан группой XML Working Group (первоначально называемой SGML Editorial Review Board), сформированной в 1996 году под патронажем World Wide Web Consortium (W3C). Председательствовал в группе Jon Bosak из Sun Microsystems, принимавший также активное участие в работе группы XML Special Interest Group (ранее известной как SGML Working Group), которая тоже была сформирована W3C. Связь группы с W3C обеспечивает Dan Connolly.
При разработке языка XML ставились следующие задачи:
1. XML должен быть пригоден для непосредственного использования в Интернет.
2. XML должен иметь широкий круг применения.
3. XML должен быть совместим с SGML.
4. Обработчики документов XML должны быть просты в написании.
5. Количество факультативных свойств в XML должно быть сведено к абсолютному минимуму, в идеале число их вообще должно быть нулевым.
6. XML документы должны быть удобны для чтения и достаточно понятны.
7. Подготовка XML документа должна осуществляться быстро.
8. Процедура построения XML документа должна быть формальной и точной.
9. Процедура создания XML документов должна быть проста.
10. Краткость при разметке XML документа имеет минимальное значение.
Данная спецификация в сочетании с остальными связанными с нею стандартами (Unicode и ISO/IEC 10646 для символов, Internet RFC 1766 для тэгов идентификации языка, ISO 639 для кодов с названием языка и ISO 3166 для кодов с названием страны) дает всю необходимую информацию для понимания языка XML (версия 1.0) и создания компьютерных программ для его обработки.
Версии XML
• XML 1.0
• XML 1.1
Достоинства
• XML (человеко-ориентированный) — это формат, одновременно понятный и человеку и компьютеру.
• XML поддерживает Юникод.
• В формате XML могут быть описаны основные структуры данных — такие как записи, списки и деревья.
• XML — это самодокументируемый формат, который описывает структуру и имена полей также как и значения полей.
• XML имеет строго определённый синтаксис и требования к парсингу, что позволяет ему оставаться простым, эффективным и непротиворечивым.
• XML также широко используется для хранения и обработки документов как он-лайн, так и офф-лайн.
• XML — формат, основанный на международных стандартах.
• Иерархическая структура XML подходит для описания практически любых типов документов.
• XML представляет собой простой текст, свободный от лицензирования и каких-либо ограничений.
• XML не зависит от платформы.
• XML является подмножеством SGML (который используется с 1986 года). Уже накоплен большой опыт работы с языком и созданы специализированные приложения.
• XML не накладывает требований на расположение символов на строке.
Одним из очевидных достоинств XML является возможность использования его в качестве универсального языка запросов к хранилищам информации. Сегодня в глубинах W3C находится на рассмотрении рабочий вариант стандарта XML-QL(или XQL), который, возможно, в будущем составит серьезную конкуренцию SQL. Кроме того, XML-документы могут выступать в качестве уникального способа хранения данных, который включает в себя одновременно средства для разбора информации и представления ее на стороне клиента. В этой области одним из перспективных направлений является интеграция Java и XML - технологий, позволяющая использовать мощь обеих технологий при построении машинно-независимых приложений, использующих, кроме того, универсальный формат данных при обмене информации.
XML позволяет также осуществлять контроль за корректностью данных, хранящихся в документах, производить проверки иерархических соотношений внутри документа и устанавливать единый стандарт на структуру документов, содержимым которых могут быть самые различные данные. Это означает, что его можно использовать при построении сложных информационных систем, в которых очень важным является вопрос обмена информацией между различными приложениями, работающими в одной системе. Создавая структуру механизма обмена информации в самом начале работы над проектом, менеджер может избавить себя в будущем от многих проблем, связанных с несовместимостью используемых различными компонентами системы форматов данных.
Недостатки
· Синтаксис XML избыточен.
o Размер XML документа существенно больше бинарного представления тех же данных. В грубых оценках величину этого фактора принимают за 1 порядок (в 10 раз).
o Размер XML документа существенно больше, чем документа в альтернативных текстовых форматах передачи данных (например JSON) и особенно в форматах данных оптимизированных для конкретного случая использования.
o Избыточность XML может повлиять на эффективность приложения. Возрастает стоимость хранения, обработки и передачи данных.
o Для большого количества задач не нужна вся мощь синтаксиса XML и можно использовать значительно более простые и производительные решения.
· XML не содержит встроенной в язык поддержки типов данных. В нём нет понятий «целых чисел», «строк», «дат», «булевых значений» и т.д.
· Иерархическая модель данных, предлагаемая XML, ограничена по сравнению с реляционной моделью и объектно-ориентированными графами.
· Пространства имён XML сложно использовать и их сложно реализовывать в XML парсерах.
· Существуют другие, обладающие сходными с XML возможностями, текстовые форматы данных, которые обладают более высоким удобством чтения человеком (YAML , JSON, SweetXML).
Язык SGML
Standard Generalized Markup Language (SGML) - это некий метаязык, на котором можно определять язык разметки для документов. SGML — наследник разработанного в 1960 году в IBM языка GML (Generalized Markup Language).
Изначально SGML был разработан для возможности совместного использования машинно-читаемых документов в больших правительственных и аэрокосмических проектах. Также он широко использовался в печатной и издательской сфере, но его сложность затруднила его широкое распространения для повседневного использования.
Три основные части SGML документа, это
1. SGML декларация;
2. Document Type Definition;
3. Содержимое SGML-документа, по крайней мере, должен быть корневой элемент.
SGML предоставляет множество вариантов синтаксической разметки для использования различными приложениями. Изменяя SGML Declaration можно даже отказаться от использования угловых скобок, хотя, этот синтаксис считается стандартным, так называемым concrete reference syntax.
Пример SGML синтаксиса:
QUOTE TYPE=example
typically something like ITALICSthis/ITALICS
/QUOTE
И HTML и XML произошли от SGML. HTML это некоторое приложение SGML, а XML это подмножество SGML, разработанное для упрощения процесса машинного разбора документа. Другими приложениями SGML является SGML Docbook (документирование), и «Z Format» (типографика и документирование).
XML-генераторы
XML-документы могут служить промежуточным форматом для передачи информации от одного приложения к другому (например, как результат запроса к базе данных), поэтому их содержимое иногда генерируется и обрабатывается программами автоматически. Далеко не всегда XML документ нужно создавать вручную.
Пусть, например, нашей задачей является создание формата хранения данных регистрации каких-то происходящих в системе событий (log-файла). В простейшем случае можно ограничиться фиксированием успешных и ошибочных запросов к нашим ресурсам - в таком документе должна присутствовать информация о времени произошедшего события, его результате (удача/ошибка), IP адресе источника запроса, URI ресурса и коде результата.
Наш XML документ может выглядеть следующим образом:
?xml version=1.0 encoding=koi-8?
log
event date= 27/May/1999:02:32:46 result=success
ip-from 195.151.62.18 /ip-from
methodGET/method
url-to /misc//url-to
response200/response
/event
event date= 27/May/1999:02:41:47
result=success
ip-from 195.209.248.12 /ip-from
methodGET/method
url-to /soft.htm/url-to
response200/response
/event
/log
Структура документа довольно проста - корневым в данном случае является элемент log, каждое произошедшее событие фиксируется в элементе event и описывается при помощи его атрибутов (date - время и result - тип события) и внутренних элементов (method - метод доступа, ip-from - адрес источника, url-to - запрашиваемый ресурс, response - код ответа). Генерацией этого документа может заниматься, например, модуль аутентификации запросов в систему, а использованием - программа обработки регистрационных данных (log viewer).
DTD-определения
Итак, мы создали XML документ и убедились, что набор используемых при этом тэгов позволяет осуществлять любые манипуляции с нашей информацией. В таком случае, для того, чтобы утвердить правила нашего нового языка, т.е. список допустимых элементов, их возможное содержимое и атрибуты, мы должны создать DTD - определения (на момент написания статьи спецификация схем данных для XML- документов еще не утверждена и пока DTD являются единственным стандартным способом описания грамматики).
Вот небольшой пример для нашего XML-документа:
?xml encoding=koi8-r?
!ELEMENT log (event)+
!ELEMENT event (ip-from,method,uri-to,result)
!ELEMENT method (#PCDATA)
!ELEMENT ip-from (#PCDATA)
!ELEMENT url-to (#PCDATA)
!ELEMENT response (#PCDATA)
!ATTLIST event
result CDATA #IMPLIED
date CDATA #IMPLIED
Сохранить этот файл под именем log.dtd и включить в XML-документ новую строчку:
!--DOCTYPE log SYSTEM log.dtd--
Теперь верифицирующий XML-анализатор при обработке документа будет сверять порядок определения элементов и их атрибутов с тем, как это указано у нас в DTD-нотациях и в случае нарушения внутренней структуры выдавать сообщение об ошибке.
Объектная модель документа (DOM)
Одним из самых мощных интерфейсов доступа к содержимому XML документов является Document Object Model - DOM.
Объектная модель XML документов является представлением его внутренней структуры в виде совокупности определенных объектов. Для удобства эти объекты организуются в некоторую древообразную структуру данных - каждый элемент документа может быть отнесен к отдельной ветви, а все его содержимое, в виде набора вложенных элементов, комментариев, секций CDATA и т.д. представляется в этой структуре поддеревьями. Т.к. в любом правильно составленном XML-документе обязательно определен главный элемент, то все содержимое можно рассматривать как поддеревья этого основного элемента, называемого в таком случае корнем дерева документа. Для следующего фрагмента XML документа:
tree-node
node-level1
node-level2/
node-level2text/node-level2
node-level2/
/node-level1
node-level1
node-level2text/node-level2
node-level1
node-level2/
node-level2node-level3//node-level2
/node-level1
/tree-node
дерево элементов выглядит так:
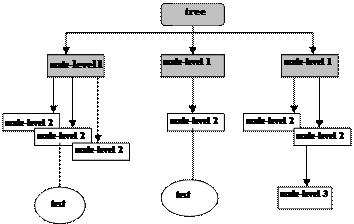
Объектное представление структуры документа не является чем-то новым для разработчиков. Для доступа к содержимому HTML страницы в сценариях давно используется объектно-ориентированный подход, - доступные для Java Script или VBScript элементы HTML документа могли создаваться, модифицироваться и просматриваться при помощи соответствующих объектов. Но их список и набор методов постоянно изменяется и зависит от типа браузера и версии языка. Для того чтобы обеспечить независимый от конкретного языка программирования и типа документа интерфейс доступа к содержимому структурированного документа в рамках W3 консорциума была разработана и официально утверждена спецификация объектной модели DOM Level 1.
DOM - это спецификация универсального платформо- и программно-независимого доступа к содержимому документов. DOM является стандартным способом построения объектной модели любого HTML или XML документа, при помощи которой можно производить поиск нужных фрагментов, создавать, удалять и модифицировать его элементы.
Для описания интерфейсов доступа к содержимому XML документов в спецификации DOM применяется платформонезависимый язык IDL и для использования их необходимо перевести на какой-то конкретный язык программирования. С точки зрения разработчиков прикладных программ DOM выглядит как набор объектов с определенными методами и свойствами.
Создание XML-документа
Для создания XML документа в простейшем случае вам не понадобится ничего кроме обычного текстового редактора. Вот пример небольшого XML-документа, используемого вместо обычной записной книжки:
?xml version=1.0 encoding=koi-8?
notepad
note id=1 date=12/04/99 time=13:40
subjectВажная деловая встреча /subject
importance/
text
Надо встретиться с person id=1625
Иваном Ивановичем/person, предварительно
позвонив ему по телефону tel123-12-12/tel
/text
/note
...
note id=2 date=12/04/99 time=13:58
subjectПозвонить домой /subject
text
tel124-13-13/tel
/text
/note
/notepad
При создании собственного языка разметки вы можете придумывать любые названия элементов, (почти любые, т.к. список допустимых символов ограничен и приведен в спецификации XML), соответствующих контексту их использования. В нашем примере приведен лишь один из многочисленных способ создания структуры дневника. В этом и заключается гибкость и расширяемость XML-производных языков - они создаются разработчиком на лету, согласно его представлениям о структуре документа, и могут затем использоваться универсальными программами просмотра наравне с любыми другими XML-производными языками, т.к. вся необходимая для синтаксического анализа информация заключена внутри документа.
Создавая новый формат, необходимо учитывать тот факт, что документов, написанных на XML, не может быть в принципе - в любом случае авторы документа для его разметки используют основанный на стандарте XML (т.н. XML-производный) язык, но не сам XML. Поэтому при сохранении созданного файла можно выбрать для него какое-то подходящее названию расширение (например, noteML).
XML может использоваться вами для создания документов какого-то определенного типа и структурой, необходимой для конкретного приложения.
Правила создания
В общем случае XML- документы должны удовлетворять следующим требованиям:
• В заголовке документа помещается объявление XML, в котором указывается язык разметки документа, номер его версии и дополнительная информация.
• Каждый открывающий тэг, определяющий некоторую область данных в документе обязательно должен иметь своего закрывающего напарника, т.е., в отличие от HTML, нельзя опускать закрывающие тэги.
• В XML учитывается регистр символов.
• Все значения атрибутов, используемых в определении тэгов, должны быть заключены в кавычки.
• Вложенность тэгов в XML строго контролируется, поэтому необходимо следить за порядком следования открывающих и закрывающих тэгов.
• Вся информация, располагающаяся между начальным и конечными тэгами, рассматривается в XML как данные и поэтому учитываются все символы форматирования (т.е. пробелы, переводы строк, табуляции не игнорируются, как в HTML).
Если XML- документ не нарушает приведенные правила, то он называется формально-правильным и все анализаторы, предназначенные для разбора XML- документов, смогут работать с ним корректно.
Однако кроме проверки на формальное соответствие грамматике языка, в документе могут присутствовать средства контроля над содержанием документа, за соблюдением правил, определяющих необходимые соотношений между элементами и формирующих структуру документа. Например, следующий текст, являясь вполне правильным, XML- документом будет абсолютно бессмысленным:
countrytitleRussia/titlecitytitle
Novosibirsk/country/title/city
Для того чтобы обеспечить проверку корректности XML- документов, необходимо использовать анализаторы, производящие такую проверку и называемые верифицирующими.
На сегодняшний день существует два способа контроля правильности XML- документа: DTD – определения (Document Type Definition) и схемы данных (Semantic Schema). Более подробно об использовании DTD и схемах мы поговорим в следующих разделах. В отличие от SGML, определение DTD- правил в XML не является необходимостью, и это обстоятельство позволяет нам создавать любые XML- документы, не ломая пока голову над весьма непростым синтаксисом DTD.
Структура документа
Простейший XML- документ может выглядеть так:
?xml version=1.0?
list_of_items
item id=1first/Первый /item
item id=2Второй sub_itemподпункт 1
/sub_item/item
item id=3Третий /item
item id=4last/Последний /item
/list_of_items
Обратите внимание на то, что этот документ очень похож на обычную HTML-страницу. Так же, как и в HTML, инструкции, заключенные в угловые скобки называются тэгами и служат для разметки основного текста документа. В XML существуют открывающие, закрывающие и пустые тэги.
Тело документа XML состоит из элементов разметки (markup) и непосредственно содержимого документа - данных (content). XML- тэги предназначены для определения элементов документа, их атрибутов и других конструкций языка.
Любой XML- документ должен всегда начинаться с инструкции ?xml?, внутри которой также можно задавать номер версии языка, номер кодовой страницы и другие параметры, необходимые программе-анализатору в процессе разбора документа.
Конструкции языка
Содержимое XML- документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней.
Элементы данных
Элемент - это структурная единица XML- документа. Заключая слово rose в в тэги flower /flower , мы определяем непустой элемент, называемый flower, содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, - т.е. практически любые части XML- документа.
Любой непустой элемент должен состоять из начального, конечного тэгов и данных, между ними заключенных. Например, следующие фрагменты будут являться элементами:
flowerrose/flower
cityNovosibirsk/city ,
а эти - нет:
rose
flower
rose
Набором всех элементов, содержащихся в документе, задается его структура и определяются все иерархические соотношения. Плоская модель данных превращается с использованием элементов в сложную иерархическую систему со множеством возможных связей между элементами. Например, в следующем примере мы описываем месторасположение Новосибирских университетов (указываем, что Новосибирский Университет расположен в городе Новосибирске, который, в свою очередь, находится в России), используя для этого вложенность элементов XML :
country id=Russia
cities-list
city
titleНовосибирск /title
stateSiberia/state
universities-list
university id=2
titleНовосибирский Государственный
Технический Университет/title
noprivate/
address URL=www.nstu.ru/
descriptionочень хороший институт/description
/university
university id=2
titleНовосибирский Государственный
Университет/title
noprivate/
address URL=www.nsu.ru/
descriptionтоже не плохой /description
/university
/universities-list
/city
/cities-list
/country
Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру - используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента university, находящегося внутри конкретного элемента city. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу.
В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является country
В некоторых случаях тэги могут изменять и уточнять семантику тех или иных фрагментов документа, по разному определяя одну и ту же информацию и тем самым предоставляя приложению-анализатору этого документа сведения о контексте использования описываемых данных. Например, прочитав фрагмент cityHolliwood/city мы можем догадаться, что речь в этой части документа идет о городе, а вот во фрагменте restaurantHolliwood/restaurant - о забегаловке.
В случае, если элемент не имеет содержимого, т.е. нет данных, которые он должен определять, он называется пустым. Примером пустых элементов в HTML могут служить такие тэги, как br, hr, img. Необходимо только помнить, что начальный и конечные тэги пустого элемента как бы объединяется в один, и надо обязательно ставить косую черту перед закрывающей угловой скобкой (например, empty/).
Комментарии
Комментариями является любая область данных, заключенная между последовательностями символов !-- и -- Комментарии пропускаются анализатором и поэтому при разборе структуры документа в качестве значащей информации не рассматриваются.
Атрибуты
Если при определении элементов необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты элемента. Атрибут - это пара название = значение, которую надо задавать при определении элемента в начальном тэге:
color RGB=true#ff08ff/color
color RGB=falsewhite/color
или
author id=0Ivan Petrov/author
Специальные символы
Для того, чтобы включить в документ символ, используемый для определения каких-либо конструкций языка (например, символ угловой скобки) и не вызвать при этом ошибок в процессе разбора такого документа, нужно использовать его специальный символьный либо числовой идентификатор. Например, lt; , gt; quot; или #036;(десятичная форма записи), #x1a (шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут определяться в XML документе при помощи компонентов (entity).
В XML определены два метода записи специальных символов: ссылка на сущность и ссылка по номеру символа. Сущностью (англ. entity) в XML называются именованные данные, обычно текстовые, в частности спецсимволы. Ссылка на сущность (англ. entity references) указывается в том месте, где должна быть сущность и состоит из амперсанда («»), имени сущности и точки с запятой («;»). В XML есть несколько предопределённых сущностей, таких как «lt» (ссылаться на неё можно написав «lt;») для левой угловой скобки и «amp» (ссылка — «amp;») для амперсанда, возможно также определять собственные сущности. Помимо записи с помощью сущностей отдельных символов, их можно использовать для записи часто встречающихся текстовых блоков. Ниже приведён пример использования предопределённой сущности для избежания использования знака амперсанда в названии:
company-nameATamp;T/company-name
Полный список предопределённых сущностей состоит из amp; («»), lt; («»), gt; («»), apos; («»), и quot; («») — последние две полезны для записи разделителей внутри значений атрибутов. Определить свои сущности можно в DTD-документе. Иногда бывает необходимо определить неразрывный пробел, который в XML записывается #160;
Cсылка по номеру символа (англ. numeric character reference) выглядит как ссылка на сущность, но вместо имени сущности указывается символ # и число (в десятичной или шестнадцатеричной записи), являющееся номером символа в кодовой таблице Юникод. Это обычно символы, которые невозможно закодировать напрямую, например буква арабского алфавита в ASCII-кодированном документе. Амперсанд может быть представлен следующим образом:
company-nameAT#038;T/company-name
Директивы анализатора
Инструкции, предназначенные для анализаторов языка, описываются в XML документе при помощи специальных тэгов - ? и ?;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, ? Xml version=”1.0”?) или создании пространства имен.
CDATA
Чтобы задать область документа, которую при разборе анализатор будет рассматривать как простой текст, игнорируя любые инструкции и специальные символы, но, в отличии от комментариев, иметь возможность использовать их в приложении, необходимо использовать тэги ![CDATA] и ]]. Внутри этого блока можно помещать любую информацию, которая может понадобится программе- клиенту для выполнения каких-либо действий (в область CDATA, можно помещать, например, инструкции JavaScript). Естественно, надо следить за тем, чтобы в области, ограниченной этими тэгами не было последовательности символов ]].
Определение типа документа( DTD)
DTD (англ. Document Type Definition - определение типа документа) — язык описания структуры XML-документа.
В XML- документах DTD определяет набор действительных элементов, идентифицирует элементы, которые могут находиться в других элементах, и определяет действительные атрибуты для каждого из них. Синтаксис DTD весьма своеобразен и от автора-разработчика требуются дополнительные усилия при создании таких документов (сложность DTD является одной из причин того, что использование SGML, требующего определение DTD для любого документа, не получило столь широкого распространения). Как уже отмечалось, в XML использовать DTD не обязательно - документы, созданные без этих правил, будут правильно обрабатываться программой-анализатором, если они удовлетворяют основным требованиям синтаксиса XML. Однако контроль за типами элементов и корректностью отношений между ними в этом случае будет полностью возлагаться на автора документа. До тех пор, пока грамматика нового языка не описана, нужно применять специально разработанное программное обеспечение, а не универсальные программы-анализаторы.
В DTD для XML используются следующие типы правил: правила для элементов и их атрибутов, описания категорий (макроопределений), описание форматов бинарных данных. Все они описывают основные конструкции языка - элементы, атрибуты, символьные константы внешние файлы бинарных данных.
Для того чтобы использовать DTD в документе, мы можем или описать его во внешнем файле и при описании DTD просто указать ссылку на этот файл или же непосредственно внутри самого документа выделить область, в которой определить нужные правила. В первом случае в документе указывается имя файла, содержащего DTD- описания:
?xml version=1.0 standalone=yes ?
! DOCTYPE journal SYSTEM journal.dtd
Внутри же документа DTD- декларации включаются следующим образом:
...
! DOCTYPE journal [
!ELEMENT journal (contacts, issues, authors)
...
]
...
В том случае, если используются одновременно внутренние и внешние описания, то программой-анализатором будут сначала рассматриваться внутренние, т.е. их приоритет выше. При проверке документа XML- процессор в первую очередь ищет DTD внутри документа. Если правила внутри документа не определены и не задан атрибут standalone =yes , то программа загрузит указанный внешний файл и правила, находящиеся в нем, будут считаны оттуда. Если же атрибут standalone имеет значение yes, то использование внешних DTD описаний будет запрещено.
Определение элемента
Элемент в DTD определяется с помощью дескриптора !ELEMENT, в котором указывается название элемента и структура его содержимого.
Например, для элемента flower можно определить следующее правило:
!ELEMENT flower PCDATA
Ключевое слово ELEMENT указывает, что данной инструкцией будет описываться элемент XML. Внутри этой инструкции задается название элемента (flower) и тип его содержимого.
В определении элемента мы указываем сначала название элемента (flower), а затем его модель содержимого - определяем, какие другие элементы или типы данных могут встречаться внутри него. В данном случае содержимое элемента flower будет определяться при помощи специального маркера PCDATA (что означает parseable character data - любая информация, с которой может работать программа-анализатор). Существует еще две инструкции, определяющие тип содержимого: EMPTY, ANY. Первая указывает на то, что элемент должен быть пустым (например, red/), вторая - на то, что содержимое элемента специально не описывается.
Последовательность дочерних для текущего элемента объектов задается в виде списка разделенных запятыми названий элементов. При этом для того, чтобы указать количество повторений включений этих элементов могут использоваться символы +,*, ? :
!ELEMENT issue (title, author+, table-of-contents?)
В этом примере указывается, что внутри элемента issue должны быть определены элементы title, author и table-of-contents, причем элемент title является обязательным элементом и может встречаться лишь однажды, элемент author может встречаться несколько раз, а элемент table-of-contents является опциональным, т.е. может отсутствовать. В том случае, если существует несколько возможных вариантов содержимого определяемого элемента, их следует разделять при помощи символа | :
!ELEMENT flower (PCDATA | title )*
Символ * в этом примере указывает на то, что определяемая последовательность внутренних элементов может быть повторена несколько раз или же совсем не использоваться.
Если в определении элемента указывается смешанное содержимое, т.е. текстовые данные или набор элементов, то необходимо сначала указать PCDATA, а затем разделенный символом | список элементов.
Пример корректного XML- документа:
?xml version=1.0?
! DOCTYPE journal [
!ELEMENT contacts (address, tel+, email?)
!ELEMENT address (street, appt)
!ELEMENT street PCDATA
!ELEMENT appt (PCDATA | EMPTY)*
!ELEMENT tel PCDATA
!ELEMENT email PCDATA
]...
contacts
address
streetMarks avenue/street
appt id=4
/address
tel12-12-12/tel
tel46-23-62/tel
emailinfo@j.com/email
/contacts
Определение атрибутов
Списки атрибутов элемента определяются с помощью ключевого слова !ATTLIST. Внутри него задаются названия атрибутов, типы их значений и дополнительные параметры. Например, для элемента article могут быть определены следующие атрибуты:
!ATTLIST article
id ID #REQUIRED
about CDATA #IMPLIED
type (actual | review | teach ) actual
В данном примере для элемента article определяются три атрибута: id, about и type, которые имеют типы ID (идентификатор), CDATA и список возможных значений соответственно. Всего существует шесть возможных типов значений атрибута:
CDATA - содержимым документа могут быть любые символьные данные.
ID - определяет уникальный идентификатор элемента в документе.
IDREF (IDREFS) - указывает, что значением атрибута должно выступать название (или несколько таких названий, разделенных пробелами во втором случае) уникального идентификатора определенного в этом документе элемента.
ENTITY (ENTITIES) - значение атрибута должно быть названием (или списком названий, если используется ENTITIES) компонента (макроопределения), определенного в документе.
NMTOKEN (NMTOKENS) - содержимым элемента может быть только одно отдельное слово (т.е. этот параметр является ограниченным вариантом CDATA).
Список допустимых значений - определяется список значений, которые может иметь данный атрибут.
Также в определении атрибута можно использовать следующие параметры:
#REQUIRED - определяет обязательный атрибут, который должен быть задан во всех элементах данного типа.
#IMPLIED - атрибут не является обязательным.
#FIXED значение - указывает, что атрибут должен иметь только указанное значение, однако само определение атрибута не является обязательным, но в процессе разбора его значение в любом случае будет передано программе-анализатору. Значение - задает значение атрибута по умолчанию.
Типизация данных
Довольно часто при создании XML- элемента разработчику требуется определить, данные какого типа могут использоваться в качестве его содержимого. Т.е. если мы определяем элемент last-modified10.10.98/last-modified, то хотим быть уверенными, что в документе в этом месте будет находиться строка, представляющая собой дату, а не число или произвольную последовательность символов. Используя типизацию данных, можно создавать элементы, значения которых могут использоваться, например, в качестве параметров SQL- запросов. Программа клиент в этом случае должна знать, к какому типу данных относится текущее значение элемента и в случае соответствия формирует SQL-запрос.
Если в качестве программы на стороне клиента используется верифицирующий XML-процессор, то информацию о типе можно передавать при помощи специально созданного для этого атрибута элемента, имеющего соответствующее DTD- определение. В процессе разбора программа-анализатор передаст значение этого атрибута клиентскому приложению, которое сможет использовать эту информацию должным образом. Например, чтобы указать, что содержимое элемента должно быть длинным целым, можно использовать следующее DTD- определение:
!ELEMENT counter (PCDATA)
!ATTLIST counter data_long CDATA #FIXED LONG
Задав атрибуту значение по умолчанию LONG и определив его как FIXED, мы позволили тем самым программе-клиенту получить необходимую информацию о типе содержимого данного элемента, и теперь она может самостоятельно определить соответствие типа этого содержимого указанному в DTD- определении .
Вот пример XML- документа, в котором определяются и используются несколько элементов с различными типами данных:
!ELEMENT price (PCDATA)
!ATTLIST price data_currency CDATA #FIXED CURRENCY
!ELEMENT rooms_num (PCDATA)
!ATTLIST rooms_num data_byte CDATA #FIXED BYTE
!ELEMENT floor (PCDATA)
!ATTLIST floor data_byte CDATA #FIXED INTEGER
!ELEMENT living_space (PCDATA)
!ATTLIST living_space data_float CDATA #FIXED FLOAT
!ELEMENT counter (PCDATA)
!ATTLIST counter data_long CDATA #FIXED LONG
!ELEMENT is_tel (PCDATA)
!ATTLIST is_tel data_bool CDATA #FIXED BOOL
!ELEMENT house (rooms_num, floor,living_space,
is_tel, counter, price)
!ATTLIST house id ID #REQUIED
...
house id=0
rooms_num5/rooms_num
floor2/floor
living_space32.5/living_space
is_teltrue/is_tel
counter18346/counter
price34 р . 28 к ./price
/house
...
Как видно из примера, механизм создания элементов документа при этом нисколько не изменился. Все необходимая для проверки типов данных информация заложена в определения элементов внутри блока DTD.
В заключении хотелось бы отметить, что DTD предоставляет весьма удобный механизм осуществления контроля за содержимым документа. На сегодняшний день, практически все программы просмотра документов Интернет используют DTD-правила. Однако это далеко не единственный способ проверки корректности документа. В настоящий момент в W3 консорциуме находится на рассмотрении новый стандарт языка описания структуры документов, называемый схемами данных. Сейчас идёт отказ от формата по ряду причин:
Во-первых, он использует отличный от XML синтаксис.
Во-вторых, отсутствует типизация узлов.
На смену DTD пришёл стандарт консорциума W3C XML Schema.
Схемы данных
Схемы данных (Schemas) являются альтернативным способом создания правил построения XML-документов. По сравнению с DTD, схемы обладают более мощными средствами для определения сложных структур данных, обеспечивают более понятный способ описания грамматики языка, способны легко модернизироваться и расширяться. Безусловным достоинством схем является также то, что они позволяют описывать правила для XML- документа средствами самого же XML.
Однако это не означает, что схемы могут полностью заменить DTD- описания - этот способ определения грамматики языка используется сейчас практическими всеми верифицирующими анализаторами XML и, более того, сами схемы, как обычные XML- элементы, тоже описываются DTD. Но серьезные возможности нового языка и его относительная простота, безусловно, дают основания утверждать, что будущий стандарт найдет широкое применение в качестве удобного и эффективного средства проверки корректности составления документов.
Внешний вид схем данных
Внешне документы схем очень похожи на те документы XML, с которыми мы уже встречались в предыдущих разделах. Мы размечаем документ при помощи специальных элементов, выполняющих в схемах роль инструкций. Эти инструкции составляют набор правил, используя которые, программа-клиент будет делать вывод о том, корректен документ или нет. Схема данных, например, может выглядеть следующем образом:
schema id=OurSchema
elementType id=#title
string/
/elementType
elementType id=photo
element type=#title
attribute name=src/
/elementType
elementType id=gallery
element type=#photo
/elementType
/schema
Если мы включим приведенные правила внутрь XML- документа, программа-клиент сможет использовать их для проверки. Т.е. она теперь сможет определить, что правильным будет являться следующий фрагмент:
gallery
photo id=1titleMy computer/title/photo
photo id=2titleMy family/title/photo
photo id=3titleMy dog/title/photo
/gallery ,
а некорректным этот:
gallery
photo id=1/
photo index=2titleMy family/title/photo
photo index=3title My dog /titledogname
Sharik/dogname/photo
/gallery
Область схемы данных
Создавая схемы данных, мы определяем в документе специальный элемент, schema, внутри которого содержатся описания правил:
schema id=OurSchema
!-- последовательность инструкций --
/schema
Если использовать отдельное пространство имен, то полный XML-документ, содержащий в себе схему данных, будет выглядеть следующим образом:
?XML version=1.0 ?
?xml:namespace
href=http://www.mrcpk.nstu.ru/schemas/ as=s/?
s:schema id=OurSchema
!-- последовательность инструкций --
/s:schema
Описание элементов
Для определения класса элемента, к которому в дальнейшем будут применяться инструкции, описывающие его содержимое и структуру, предназначен специальный элемент схемы elementType:
elementType id=issue
descriptЭлемент содержит информацию об очередном
выпуске журнала/descript
/elementType
Название элемента задается атрибутом id. Все дальнейшие инструкции, которые относятся к описываемому классу, определяют его внутреннюю структуру и набор допустимых данных, содержатся внутри блока, заданного тэгами elementType и /elementType. Мы рассмотрим эти инструкции чуть позже.
Как видно из примера, при определении класса элемента, можно также использовать комментарии к нему, которые заключаются в тэги descript/descript.
Атрибуты элемента
Для того, чтобы в описании элемента определить его атрибуты и описать свойства этих атрибутов мы должны использовать элемент attribute:
elementType id=photo
attribute name=src/
empty/
/elementType
В данном примере элементу photo определяется атрибут src, значением которого может быть любая последовательность разрешенных символов:
photo src=0/
photo src=some text
Подобно DTD, схемы данных позволяют устанавливать ограничения на значения и способ использования атрибутов. Для этого в дескрипторе attribute необходимо использовать параметр atttype.
Например, если мы хотим указать, что значение атрибута должно использоваться программой-анализатором как уникальный идентификатор, то нам необходимо создать следующее правило:
elementType id=bouquet
attribute name=id atttype=ID
/elementType
Если же требуется задать список возможных значений атрибута, то пример будет выглядеть следующим образом:
attribute name=flower atttype=ENUMERATION
values=red green blue default=red
Для приведенных примеров корректным будет являться следующий фрагмент XML-документа:
bouquet id=0
flower color=redrose/flower
flower color=greenleaf/flower
flower color=bluebluet/flower
/bouquet
Модель содержимого элемента
Под моделью содержимого в схеме данных понимают описание всех допустимых объектов XML- документа, использование которых внутри данного элемента является корректным. Модель содержимого определяется инструкциями, расположенными внутри блока elementType:
elementType id=article
attribute name=id atttype=ID
element type=#title
string/
/elementType
Для этого правила корректным будет являться следующий фрагмент документа:
article id=0
titleПсихи и маньяки в Интернет/title
/article
Вложенные элементы описываются при помощи инструкции element, в которой параметром type указывается класс объекта - ссылка на его определение:
elementType id=article
element type=#title/
element type=#author/
/elementType
Если требуется указать режим использования вложенного элемента, то надо определить параметр occurs:
elementType id=article
element type=#title occurs=REQUIRED/
element type=#author occurs=OPTIONAL/
element type=#subject occurs=ONEORMORE/
/elementType
Возможные значения этого параметра таковы:
REQUIRED - элемент должен быть обязательно определен.
OPTIONAL - использование элемента не является обязательным.
ZEROORMORE - вложенный элемент может встречаться несколько раз или ни разу.
ONEORMORE - элемент должен встречаться хотя бы один раз.
Примеры правильных XML-документов, использующих приведенную выше схему:
article
titleЗачем он нужен , XML?/title
authorИван Петров /author
subjectЧто такое XML/subject
subjectнужен ли он нам/subject
/article
или
article
titleЗачем он нужен , XML?/title
subjectЧто такое XML/subject
/article
Кроме элементов, содержимым XML-документа могут также является обычный текст и области CDATA. Для обозначения типов содержимого текущего элемента в схемах используются следующие инструкции:
string/ - указывает на то, что содержимым элемента является только свободная текстовая информация(секция PCDATA) :
elementType id=flower
string/
/elementType
any/ - указывает на то, что содержимым элемента должны являться только элементы, без текста, незаключенного ни в один элемент:
elementType id=issue
any/
/elementType
mixed - любое сочетание элементов и текста
elementType id=contacts
mixed/
/elementType
empty - пустой элемент
Пример:
elementType id=title
string/
/elementType
elementType id=chapter
string/
/elementType
elementType id=chapters-list
any/
/elementType
elementType id=content
element type=#chapters-list occurs=OPTIONAL
/elementType
elementType id=article
mixedelement type=#title/mixed
element type=#content occurs=OPTIONAL
/elementType
Иерархия классов
Для того, чтобы при описании класса ограничить список объектов, которые могут являться родительскими для данного элемента, необходимо использовать элемент схемы domain.
Инструкция domain указывает, что текущий объект должен определяться строго внутри элемента, заданного этим тэгом. Например, в следующем фрагменте указывается, что элемент author может быть определен строго внутри тэга article:
elementType id=author
element type=#lastname
element type=#firstname
domain type=#article/
/elementType
Ограничения на значения
Значения элементов могут быть ограничены при помощи тэгов min и max;:
elementType id=room
element type=#floormin0/minmax100/max
/elementType
Внутри этих элементов могут указываться и символьные ограничения:
elementType id=line
element type=#characterminA/minmaxZ/max
/elementType
Использование правил из внешних схем
Схема может использовать элементы и атрибуты из других схем. Для этого надо использовать атрибут href, в котором указывается название внешней схемы. Например:
?XML version=1.0 ?
?xml:namespace name=urn:uuid:BDC6E3F0-6DA3-11d1-
A2A3-00AA00C14882/ as=s/?
s:schema
elementType id=author
string/
/elementType
elementType id=title
string/
/elementType
elementType id=Book
element type=#title occurs=OPTIONAL/
element type=#author occurs=ONEORMORE/
element href=http://mrcpk.org/ /
/elementType/s:schema
/elementType
/s:schema
Типы данных
В разделе, посвященном DTD, мы уже выяснили, для чего программе-клиенту необходима информация о формате данных содержимого элемента. В схемах существует возможность задавать тот или иной тип данных, используя при определении элемента директиву datatype с указанием конкретного типа:
elementType id=counter
datatype dt=int
/elementType
В DTD мы должны были создать атрибут с конкретным названием, определяющим операцию назначения формата данных, и значением, определенным как fixed. Использование элемента datatype позволяет указывать это автоматически, но для обеспечения программной независимости необходимо сначала договориться об обозначениях типов данных (значения, которые должны передаваться параметру dt элемента dataype. В любом случае, как и прежде, все необходимые действия, связанные с конкретной интерпретацией данных, содержащихся в документе, осуществляются программой-клиентом и определяются логикой его работы. В разделе, посвященном DTD, мы уже рассматривали пример XML- документа, реализующего описанные нами возможности. Вот как выглядел бы этот пример при использовании схем данных:
schema id=someschema
elementType id=#rooms_num
string/
datatype dt=int
/schema
elementType id=#floor
string/
datatype dt=int
/schema
elementType id=#living_space
string/
datatype dt=float
/schema
elementType id=#is_tel
string/
datatype dt=boolean
/schema
elementType id=#counter
string/
datatype dt=float
/schema
elementType id=#price
string/
datatype dt=float
/schema
elementType id=#comments
string/
datatype dt=string
/schema
elementType id=#house
element type=#rooms_numoccurs=ONEORMORE/
element type=#floor occurs=ONEORMORE/
element type=#living_space occurs=ONEORMORE/
element type=#is_tel occurs=OPTIONAL/
element type=#counter occurs=ONEORMORE/
element type=#price occurs=ONEORMORE/
element type=#comments occurs=OPTIONAL/
/elementType
/schema
...
house id=0
rooms_num5/rooms_num
floor2/floor
living_space32.5/living_space
is_teltrue/is_tel
counter18346/counter
price34.28/price
commentsС видом на северный полюс /comments
/house
...
Язык запросов XQuery
XQuery — язык запросов, разработанный для обработки данных в формате XML. XQuery использует XML как свою модель данных.
Консорциум World Wide Web Consortium (W3C) образовал рабочую группу для разработки языка запросов к источникам данных, представленных на языке XML. Этот язык запросов, получивший название XQuery, развивается до сих пор и описан в серии предварительных документов. XQuery — функциональный язык, состоящий из нескольких видов выражений, которые могут использоваться в разных сочетаниях. Язык базируется на системе типов XML Schema и совместим с другими стандартами, связанными с XML.
Язык XML все чаще применяется в качестве формата для обмена информацией между разными приложениями в Internet. Популярность XML во многом объясняется его гибкостью при представлении разных видов информации. Применение тегов делает XML-данные самоописываемыми, а расширяемая природа XML позволяет определять новые виды специализированных документов. По мере роста значимости XML создается целая серия стандартов, многие из которых были подготовлены консорциумом W3C . Так, XML Schema обеспечивает нотацию для определения новых типов элементов и документов; XML Path Language (XPath) — нотацию для выбора элементов в документе XML; Extensible Stylesheet Language Transformations (XSLT) — нотацию для преобразования документов XML из одного представления в другое.
XML позволяет приложениям обмениваться данными в стандартном формате, не зависящем от способа их хранения. Скажем, одно приложение может использовать естественный для XML формат хранения, а другое — хранить данные в реляционной базе данных. Поскольку XML все больше утверждается в роли стандарта для обмена данными, естественно, что запросы, поступающие от приложений, должны быть выражены как запросы к данным в формате XML. Это вызывает потребность в языке запросов, явно ориентированном на источники XML-данных. В октябре 1999 года W3C образовал рабочую группу XML Query Working Group с целью разработки такого языка запросов, получившего название XQuery.
В XML-документах имеется внутренний порядок, а реляционные данные неупорядочены, если не принимать во внимание те случаи, когда порядок можно определить на основе значений данных. Реляционные данные обычно являются «плотными» (т.е. почти в каждом столбце имеется значение), а отсутствующая информация в реляционных системах часто представляется специальным значением null. XML-данные часто бывают «разреженными», а отсутствие информации может представляться отсутствием элемента. По этим и другим причинам имеющиеся языки реляционных запросов не подходят напрямую для запросов XML-данных.
На разработку XQuery влияет целый ряд факторов. Возможно, важнее всего совместимость с существующими стандартами W3C, в том числе, XML Schema, XSLT, XPath и сам XML. В частности, язык XPath настолько тесно связан с XQuery, что XQuery определяется как надмножество XPath. В начальном виде XQuery устремлен только на извлечение информации и не включает средств для модификации существующих документов XML
Модель данных
Формально входные и выходные данные XQuery определяются в терминах модели данных. «Запросная» модель данных обеспечивает абстрактное представление одного или нескольких документах или фрагментов XML-документов. Модель данных опирается на понятие последовательности. Последовательность (sequence) — это упорядоченный набор нулевого или большего числа объектов. Объект (item) может быть узлом или атомарным значением. Атомарное значение (atomic value) — экземпляр одного из встроенных типов данных, определенных в XML Schema, таких как строки, целые и десятичные числа, даты. Узел (node) соответствует одному из семи видов: элементы, атрибуты, тексты, документы, комментарии, команды обработки и пространства имен. Узел может иметь другие узлы в качестве потомков, что позволяет образовывать одну или несколько иерархий узлов. Некоторые виды узлов, такие как элементы и атрибуты, имеют имена или типизированные значения, либо и то, и другое. Типизированное значение (typed value) — это последовательность из нуля или большего числа атомарных значений. Узлы индивидуальны (т. е. два узла можно различить, даже если они имеют одинаковые имена и значения), но атомарные величины такой индивидуальностью не обладают. Для всех узлов иерархии имеется полный порядок, называемый порядком документа (document order), в соответствии с которым каждый узел предшествует своему потомку. Порядок документа соответствует порядку, в котором следовали бы узлы, если бы иерархия узлов представлялась в формате XML. Порядок документа между узлами в разных иерархиях определяется в реализации, но он должен быть последовательным, т.е. все узлы одной иерархии должны располагаться либо до, либо после всех узлов другой иерархии.
Последовательности могут быть неоднородными, т.е. могут содержать смесь узлов и атомарных значений разного типа. Однако последовательность никогда не может быть объектом в другой последовательности. Все операции, создающие последовательность, определены так, что результат операции — одноуровневая последовательность. Не проводится различие между объектом и последовательностью единичной длины, т.е. узел и атомарное значение величины считаются идентичными последовательности единичной длины, содержащей эти узел или атомарное значение.
Допускаются последовательности нулевой длины, и иногда они используются для представления отсутствующей или неизвестной информации, во многом так же, как в реляционных системах используются неопределенные значения.
Помимо последовательностей в запросной модели данных определяется специальное значение, называемое значением ошибки (error value), которое является результатом вычисления выражения, содержащего ошибку. Значение ошибки не может присутствовать в последовательности вместе с каким-либо другим значением.
Входные XML-документы могут быть преобразованы в запросную модель данных с помощью процесса, называемого проверкой корректности по схеме (schema validation). Этот процесс выполняет грамматический разбор документа, проверяет его корректность в соответствии с некоторой схемой и представляет документ в виде иерархии узлов и атомарных значений, помеченных типом полученным из схемы. Если входной документ не имеет схемы, проверка его корректности выполняется в соответствии с используемой по умолчанию рекомендательной схемой, которая присваивает родовые типы — узлы маркируются как anyType, а атомарные величины — как anySimpleType.
Результат запроса может быть преобразован из запросной модели данных запросов в XML-представление с помощью процесса, называемого сериализацией (serialization). Следует отметить, что результат запроса не всегда является правильно построенным XML-документом. Например, запрос может возвращать атомарное значение или последовательность элементов, не имеющих общего предка.
Иллюстрация запросной модели
Чтобы проиллюстрировать запросную модель данных и обеспечить основу для последующих примеров, рассмотрим небольшую базу данных, содержащую данные интерактивного аукциона. Эта база данных содержит два XML-документа с именами items.xml и bids.xml.
Документ items.xml содержит корневой элемент с именем items, который, в свою очередь, содержит элемент item для каждого из товаров, предложенных к продаже на аукционе. Каждый элемент item имеет атрибут status и подэлементы с именами itemno, seller, description, reserve-price и end-date. Элемент reserve-price указывает минимальную продажную цену, установленную владельцем товара, а end-date определяет дату окончания торгов.
Документ bids.xml содержит корневой элемент с именем bids, который, в свою очередь, содержит элемент bid для каждой ставки, которая предлагается за товар. Каждый элемент bid имеет подэлементы с именами itemno, bidder, bid-amount и bid-date.
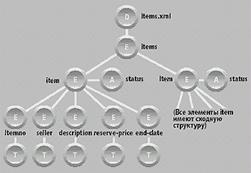
Рис. 1. Представление модели данных из items.xml
На рис. 1 и 2 показаны модельные представления документов items.xml и bids.xml соответственно (включающие только образцы товара и ставки). Круги, помеченные буквами D, E, A и T, обозначают узлы документов, элементов, атрибутов и тестов соответственно.
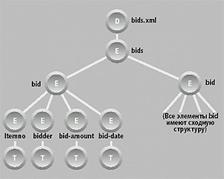
Рис. 2. Представление модели данных из bids.xml
Выражения XQuery
Основы
Подобно XML и XPath, в XQuery различаются прописные и строчные буквы, а все ключевые слова состоят из строчных букв. Символы, заключенные между «{—» и «—}» считаются комментариями и при обработке запроса игнорируются (конечно, кроме тех случаев, когда они входят в строку, заключенную в кавычки, и считаются частью этой строки).
Простейший вид выражения XQuery — литерал (literal), который представляет атомарное значение.
Атомарные значения других типов могут создаваться путем вызова конструкторов. Конструктор (constructor) представляет собой функцию, которая создает значение определенного типа на основе строки, содержащей лексическое представление значения этого типа. В общем случае конструктор имеет то же имя, что и тип, значения которого он конструирует. Ниже конструктор используется для создания значения типа date.
date(«2002-5-31»)
Переменная (variable) в XQuery — имя, начинающееся со знака доллара. Переменная может быть связана со значением и использоваться в выражении для представления этого значения. Один из способов связывания переменной состоит в использовании выражения LET, которое связывает одну или несколько переменных, а затем вычисляет внутреннее выражение. Значение выражения LET — результат вычисления внутреннего выражения со связанными переменными. Следующий пример иллюстрирует выражение LET, которое возвращает последовательность 1, 2, 3.
let $start := 1, $stop := 3
return $start to $stop
Выражение LET — частный случай выражения FLWR (for, let, where, return), которое обеспечивает дополнительные способы связывания переменных.
Выражения пути
Выражения пути в XQuery базируются на синтаксисе XPath. Выражение пути состоит из серии шагов, разделенных символом слэша («/»). Результат каждого шага — последовательность узлов. Значение выражения пути — последовательность узлов, которая формируется на последнем шаге.
Каждый шаг вычисляется в контексте некоторого узла, называемого контекстным узлом (context node). В общем случае шаг может быть любым выражением, возвращающим последовательность узлов. Один из важных видов шага, называемый осевым шагом (axis step), можно считать перемещением от контекстного узла по иерархии узлов в некотором направлении, называемом осью (axis). При перемещении по указанной оси осевой шаг выбирает узлы, которые удовлетворяют критерию выбора. Критерий выбора может выбирать узлы на основе их имен, положения по отношению к контекстному узлу или предикату, базирующемуся на значении узла. В XPath определяются 13 осей, и часть из них или все будут поддерживаться и в XQuery. Пока планируется реализовать в XQuery поддержку шести осей: child, descendant, parent, attribute, self и descendant-or-self.
Выражения пути могут быть записаны в полном или в сокращенном синтаксисе. Полный синтаксис для осевого шага предусматривает указание оси и критерия выбора, разделенных парой двоеточий. Q1 иллюстрирует четырехшаговое выражение пути, оформленное в полном синтаксисе. На первом шаге вызывается встроенная функция document, которая возвращает узел-документ документа items.xml. Второй шаг — осевой шаг, который находит всех потомков узла-документа («*» выбирает все узлы на данной оси; в данном случае будет выбран единственный узел-элемент с именем items). Третий шаг снова выполняет поиск вдоль оси child, чтобы найти на следующем уровне все элементы-потомки с именем item, которые, в свою очередь, имеют потомков с именем seller и значением «Smith». Результатом третьего шага является последовательность узлов-элементов item. Каждый из этих узлов item служит контекстным узлом для четвертого шага, который опять предусматривает поиск по оси child элементов description, являющихся потомками данного item. Окончательный результат выражения пути — результат четвертого шага: последовательность узлов-элементов description, перечисленных в порядке документа.
(Q1) Перечислить описания всех товаров, предлагаемых к продаже Смитом.
document(items.xml)/child::*
/child::item [child::seller = Smith]
/child::description
На практике, выражения пути часто записываются с помощью сокращенного синтаксиса. Пожалуй, наиболее важным является то, что спецификатор оси может быть пропущен в том случае, когда используется ось child. Поскольку child является наиболее часто используемой осью, такое сокращение помогает сократить длину многих выражений пути. К примеру, Q1 можно сократить следующим образом:
document(items.xml)
/*/item[seller = Smith]/description
Разделение двух шагов двойным, а не одинарным слэшем означает, что второй шаг может выполнять поиск в нескольких уровнях иерархии, используя для этого ось descendants, а не одноуровневую ось child. Так, Q2 выполняет поиск элементов description, которые являются потомками (необязательно прямыми) корневого узла данного документа. Результат Q2 — это последовательность узлов-элементов, которые могут, в принципе, быть найдены на различных уровнях иерархии узлов (хотя в нашем примере все узлы description находятся на одном и том же уровне).
(Q2) Перечислить все элементы описания товаров, имеющиеся в документе items.xml.
document(«items.xml»)//description
В выражении пути одинарная точка («.») указывает на контекстный узел, а две последовательные точки («..») — на предка контекстного узла. Эти нотации представляют собой сокращенное указание осей self и axes соответственно. Имена, присутствующие в выражениях пути, как правило, интерпретируются как имена узлов-элементов, однако если имя имеет префикс «@», оно интерпретируется как имя узла-атрибута. Это сокращение для шага, который выполняет поиск вдоль оси attribute. Эти аббревиатуры иллюстрируются в Q3, где поиск начинается с узла, связанного с переменной $description, вдоль оси parent к родительскому узлу item, а затем — вдоль оси attribute в поисках атрибута с именем status. Результатом Q3 является единственный узел-атрибут.
(Q3) Найти атрибут статуса для товара, который является предком данного описания товара.
$description/../@status
Предикаты
В XQuery предикат (predicate) — это заключенное в квадратные скобки выражение, которое используется для фильтрации последовательности значений. Предикаты часто применяются в шагах выражения пути. Например, в шаге item[seller = «Smith»] фраза seller = «Smith» — это предикат, который применяется для выбора определенных узлов item и отбрасывания остальных. Будем называть объекты последовательности, фильтруемые с помощью предиката, объектами-кандидатами. Предикат вычисляется для каждого объекта-кандидата с использованием этого объекта-кандидата в качестве контекстного объекта для вычисления выражения предиката. Термин «контекстный объект» — это обобщение термина «контекстный узел», и ему может соответствовать как узел, так и атомарное значение. В предикатном выражении одинарная точка («.») обозначает контекстный объект. Каждый объект-кандидат выбирается или отвергается в соответствии со следующими правилами.
Если в результате вычисления предикатного выражения получается булевское значение, то объект-кандидат выбирается в том случае, если значение предикатного выражение равно true. Этот тип предиката иллюстрируется в примере, где выбираются узлы item, имеющие узел-потомок reserve-price, чье значение больше 1000:
item [reserve-price 1000]
Если результатом вычисления предикатного выражения является число, то объект-кандидат выбирается в том случае, если его порядковый номер в списке объектов-кандидатов равен этому числу. Такой тип предиката представлен в примере, где выбирается пятый узел item по оси child:
item [5]
Если в результате вычисления предикатного выражения получается пустая последовательность, объект-кандидат отвергается. Однако если результат вычисления предикатного выражения представляет собой последовательность, содержащую хотя бы один узел, объект-кандидат выбирается. Такая форма предиката может применяться для проверки существования узла-потомка, удовлетворяющего некоторому условию. Это иллюстрирует пример, где выбираются узлы item, у которых имеется узел-потомок reserve-price, вне зависимости от его значения:
item [reserve-price]
Внутри предикатов часто используется несколько видов операций и функций.
Операции сравнения значений (value comparison operator): eq, ne, lt, le, gt, ge. Эти операции могут сравнивать два скалярных значения, но порождают ошибку, если любой из операндов является последовательностью с длиной, большей единицы. Если один из операндов — узел, то прежде, чем выполнить сравнение, операция сравнения значений извлекает его значение. Например, item[reserve-price gt 1000] выбирает узел item только в том случае, если он имеет в точности один узел-потомок reserve-price со значением, большим 1000.
Общие операции сравнения (general comparison operator): =, !=, , =, , =. Эти операции могут работать с операндами, которые представляются собой последовательности, при условии неявного наличия семантики «существования» для обоих операндов. Как и операции сравнения значений, общие операции сравнения автоматически извлекают значения узлов. Например, item[reserve-price = 1000] выбирает узел item, если у него имеется хотя бы один узел-потомок со значением, большим 1000.
Операции сравнения узлов (node comparison operator): is и isnot. Эти операторы определяют идентичность двух узлов. Например, $node1 is $node2 принимает значение «истина», если переменные $node1 и $node2 связаны с одним и тем же узлом (т. е. для обеих переменных узел один и тот же).
Операции сравнения порядка (order comparison operator). Эти операции сравнивают позиции двух узлов. Например, $node1 $node2 принимает значенией true, если узел, связанный с $node1, в порядке документа встречается раньше, чем узел, связанный с $node2.
Логические операции (logical operator): and и or. Эти операции могут использоваться для объединения логических условий в предикате. Например, следующий предикат выбирает узлы item, имеющие ровно один элемент-потомок seller со значением «Smith», а также, по крайней мере, один элемент-потомок reserve-price с любым значением.
item [seller eq «Smith» and reserve-price].
Отрицание (negation): not. Это скорее функция, а не операция. Она служит для инвертирования булевых величин.
Во всех приведенных примерах имена элементов и атрибутов были простыми идентификаторами. Однако в соответствии с рекомендацией XML Namespace [19], элементами и атрибутам позволяется иметь имена, состоящие из двух частей, где первая часть — префикс пространства имен, за которым следует двоеточие. Имя, имеющее префикс пространства имен, называется QName. Каждый префикс пространства имен должен быть связан с URI (универсальный идентификатор ресурсов), который уникальным образом определяет пространство имен. Это соглашение позволяет каждому приложению определять имена в своем собственном пространстве, не опасаясь коллизий с именами, определенными другими приложениями, что дает возможность однозначно ссылаться на имена, указываемые в различных приложениях. Если бы префикс auction был связан с URI пространства имен нашего приложения для проведения интерактивного аукциона, то шаг item [reserve-price 1000] мог бы быть записан с помощью QName следующим образом:
auction:item [auction:reserve-price 1000]
Процесс связывания префикса с URI пространства имен описан в предпоследнем разделе. В большинстве наших примеров используются одиночные имена, а не QName. Эти примеры реалистичны, поскольку XQuery обеспечивает способ указания пространства имен для запроса по умолчанию. Этот подход позволяет не использовать в запросах QName, если не нужно ссылаться на имена из других пространств имен.
Конструкторы элементов
Выражения пути — мощное средство, но им свойственно существенное ограничение: они способны выбирать только существующие узлы. В полном языке запросов необходимо наличие средства конструирования новых элементов и атрибутов, а также возможность указания их информационного наполнения и взаимосвязи. Это обеспечивается в XQuery с помощью вида выражения, называемого конструктором элементов (element constructor).
Простейший конструктор элементов создает элемент в полном соответствии с синтаксисом XML. Например, следующее выражение конструирует элемент с именем highbid, имеющий атрибут status и два элемента-потомка с именами itemno и bid-amount.
highbid status = «pending»
itemno4871/itemno
bid-amount250.00/bid-amount
/highbid
В этом примере значения элементов и атрибутов — константы. Однако во многих случаях необходимо создавать элемент или атрибут, значением которых является вычисляемое выражение. Выражение, заключенное в фигурные скобки, необходимо вычислить, а не трактовать как символьный текст. В конструкторе элемента это выражение вычисляется и заменяется своим значением. В следующем примере значения элементов и атрибутов вычисляются. Переменные $s, $i и $bids, используемые в этих выражениях, должны быть связаны с некоторыми выражениями.
highbid status = «{$s}»
itemno{$i}/itemno
bid-amount
{max($bids[itemno = $i]/bid-amount)}
/bid-amount
/highbid
В следующем примере конструктор элементов содержит выражение, заключенное в фигурные скобки, которое генерирует один атрибут и два подэлемента. Переменная $b должна быть связана с некоторым выражением.
highbid
{
$ b/@ status
$b/itemno
$b/bid-amount
}
/highbid
Узел-элемент, созданный конструктором элемента, является новым узлом, обладающим собственной индивидуальностью. Если, как в приведенном примере, вновь созданный элемент имеет узлы-потомки и атрибуты, порожденные из существующих узлов, то новые узлы-потомки и атрибуты являются копиями узлов, из которых они были получены, но как узлы они индивидуальны.
В приведенных примерах конструкторов элементов, хотя содержимое элементов может быть вычисляемым, имя конструируемого элемента — известная константа. Однако иногда необходимо сконструировать элемент, имя которого, как и его содержимое, вычисляется. Для этого в XQuery определяется специальный вид конструктора, называемого вычисляемым конструктором элемента (computed element constructor). Он состоит из ключевого слова element, за которым следуют два выражения в фигурных скобках — первое вычисляет имя элемента, а второе — его содержимое.
Чтобы привести пример использования вычисляемого конструктора, предположим, что переменная $e связана с элементом, имеющим числовое значение. Нам нужно сконструировать новый элемент, имеющий то же имя, что и $e, и те же атрибуты, что у $e, но его значение должно быть вдвое больше значения $e. Этого можно добиться с помощью выражения, в котором функция data используется для получения числового значения исходного узла.
element
{name($e)}
{$e/@*, data($e)*2}
Подобно вычисляемому конструктору элемента, в XQuery обеспечивается вычисляемый конструктор атрибута (computed attribute constructor), состоит из ключевого слова attribute, за которым следуют два выражения в фигурных скобках — первое вычисляет имя атрибута, а второе — значение. Конструктор атрибута может использоваться везде, где допустим атрибут. Следующий конструктор атрибута на основе связанной переменной $p мог бы сгенерировать атрибут, который выглядит как father = «Frank» или mother = «Mary».
attribute
{if $p/sex = M then father else mother}
{$p/name}
Итерация и сортировка
Итерация — важная часть языка запросов. XQuery предлагает способ выполнять итерацию над последовательностью значений, по очереди связывая переменную с каждым значением и вычисляя выражения для каждого связывания переменной.
В наиболее простой форме итерация в XQuery задается оператором for, в котором указывается имя переменной и предоставляется последовательность значений, над которой переменная итерируется. Далее указывается оператор return, который содержит выражение, вычисляемое для каждого связывания переменной; см. ниже.
for $n in (2, 3) return $n + 1
Результатом этого итеративного выражения будет последовательность (3, 4).
В операторе for можно указывать более одной переменной с последовательностью итерации для каждой из них. Такой оператор порождает кортежи связываний переменных, которые образуют декартово произведение итерационных последовательностей. Если не указано иное, кортежи связываний генерируются в порядке, сохраняющем порядок итерационных последовательностей, с использованием самой левой переменной как «самый внешний цикл», а самую правую — как «самый внутренний цикл». В примере оператор for содержит две переменные и две итерационные последовательности.
for $m in (2, 3), $n in (5, 10)
return fact{$m} times {$n} is
{$m * $n} /fact
В результате получается следующая последовательность из четырех элементов.
fact2 times 5 is 10 /fact
fact2 times 10 is 20 /fact
fact3 times 5 is 15 /fact
fact3 times 10 is 30/fact
Операторы for и let — частные случаи более общего выражения, называемого FLWR. В наболее общем виде выражение FLWR может иметь несколько операторов for, несколько операторов let, необязательный оператор where, а также оператор return. Функция операторов for и let — связывание переменных. Каждый из них содержит одну или несколько переменных и выражение, присваиваемое каждой переменной. Результатом вычисления выражений являются последовательности, и выражения могут содержать ссылки на переменные, для которых связывание было выполнено в предыдущих операторах. Оператор for итерирует каждую переменную над ассоциированной с ней последовательностью, связывая переменную по очереди с каждым объектом последовательности, а как оператор let связывает каждую переменную сразу со всей ассоциированной последовательностью. Это различие иллюстрируется следующей парой операторов.
for $i in (1 to 3)
let $j := (1 to $i)
Эта пара операторов не является полным выражением FLWR, поскольку в нем отсутствует условие return. Операторы for и let просто порождают последовательность кортежей связываний. Приведенный выше пример порождает следующую последовательность из трех пар связываний.
$i = 1, $j = 1
$i = 2, $j = (1,2)
$i = 3, $j = (1,2,3)
В общем случае, число кортежей связывания, порождаемых серией операторов for и let, равняется произведению мощностей выражений итерации в операторах for. Оператор let при отсутствии оператора for, конечно, порождает только один кортеж связывания.
Кортежи связывания, порожденные операторами for и let в FLWR-выражении, фильтруются в соответствии с необязательным условием where. Оператор where содержит выражение, которое вычисляется для каждого кортежа связывания. Если значением выражения where являются булевское значение true или непустая последовательность («проверка существования»), то кортеж связываний принимается; в противном случае он отвергается.
Затем в выражении FLWR вычисляется оператор return по очереди и по одному разу для каждого оставшегося после проверки условия where кортежа связывания. Результаты вычислений объединяется в последовательность, которая и является результатом выражения FLWR.
Возможности FLWR иллюстрируются в запросе к базе данных аукциона Q4.
(Q4) Для каждого товара, который имеет более десяти ставок, создать элемент popular-item, содержащий номер товара, описание и число ставок.
for $i in document(items.xml)/*/item
let $b := document(bids.xml)
/*/ bid[itemno = $i/itemno]
where count ($b) 10
return
popular-item
{
$i/itemno,
$i/description,
bid-count {count($b)} / bid-count
}
/popular-item
Операторы for и let порождают пару связывания для каждого item в items.xml. В каждой паре связывания $i связан с товаром, а $b — с последовательностью, содержащей все ставки для этого товара. Оператор where оставляет только те связанные кортежи, в которых $b содержит более десяти ставок. Затем оператор return для каждого из этих связываний генерирует выходной элемент, содержащий номер товара, описание и число ставок.
По умолчанию, порядок выходной последовательности выражения FLWR соответствует порядку итерационных последовательностей. Перед любым выражением может стоять префиксная операция unordered, указывающая, что порядок результата не имеет значения. Такое указание повышает гибкость реализации, позволяя оптимизировать вычисление выражения.
Конечно, каждое выражение упорядочивания должно возвращать единственный результат, и эти результаты должны быть сравнимы с помощью оператора gt. В случае применения условия sortby пустая последовательность может считаться либо больше любого другого значения, либо меньше любого другого значения — как то определит пользователь.
Условие sortby часто полезно для переупорядочивания результатов выражения FLWR. Если необходимо отсортировать по убыванию bid-count элементы popular-item, сгенерированные в запросе Q4, то в конец Q4 можно добавить следующий оператор.
sortby bid-count descending
Важно понимать, что sortby не является частью выражения FLWR, а представляет собой отдельный вид выражений XQuery, который может использоваться для переупорядочивания любой последовательности, вне зависимости от того, сгенерирована она выражением FLWR или нет. Однако если после выражения FLWR стоит sortby, интеллектуальный оптимизатор поймет, что переупорядочивание выходных объектов снимает обычные ограничения на порядок кортежей связываний.
Q4 показывает, как выражение FLWR может походить на запрос с соединением в системе управления реляционной базой данных, а также на запрос с группировкой. Q4 похож на запрос с соединением, поскольку в нем коррелируются элементы, находящиеся в двух разных файлах — items.xml и bids.xml. Он также напоминает запрос с группировкой, поскольку ставки группируются по номеру товара, и вычисляется число ставок в каждой группе.
Арифметические операции
В XQuery обеспечиваются обычные арифметические операции: +, — , *, div и mod, а также агрегатные функции sum, avg, count, max и min, которые применяются к последовательности чисел и возвращают числовой результат. Оператор деления в XQuery называется div, чтобы его можно было отличить от слэша. Если после оператора вычитания следует имя, перед ним должен стоять пробел, который позволяет отличить его от дефиса, поскольку в XML дефис — корректный символ для имени.
Арифметические операции определяются для числовых значений. К числовым значениям относятся значения типов integer, decimal, float, double или типов, производных от них. Если типы операндов арифметической операции различны, операнды приводятся к ближайшему общему типу в соответствии с иерархией приведения integer - decimal - float - double. Если операнд арифметического оператора является узлом, то автоматически извлекается его типизированное значение.
Важный частный случай — применение арифметических операций к пустым последовательностям. В XQuery пустая последовательность иногда используется для представления отсутствующей или неизвестной информации, во многом подобно тому, как неопределенное значение используется в реляционных системах. По этой причине операции +, -, *, div и mod определяются таким образом, что они возвращают пустую последовательность, если любой из операндов — пустая последовательность. Для иллюстрации этого правила предположим, что переменная $emps связана с последовательностью элементов emp, каждый из которых представляет сотрудника и содержит элементы name и salary, а также дополнительные элементы comission и bonus. Выражение в Q5 преобразует эту последовательность в последовательность элементов emp, каждый из которых содержит элементы name и pay, причем значение pay равно полной заработной плате сотрудника. Для тех сотрудников, комисионные (commission) или премия (bonus) которых не заданы ($e/commission или $e/bonus — пустая последовательность), генерируемый элемент pay будет пустым.
(Q5) Задана последовательность элементов emp. Заменить их подэлементы salary, commission и bonus на новый элемент pay, содержащий сумму значений исходных элементов, а результирующую последовательность отсортировать по убыванию значений элемента pay.
for $e in $emps
return
emp
{
$e/name,
pay {$e/salary + $e/commission+ $e/bonus} /pay
}
/emp
sortby (pay)
Иногда желательно определять значение по умолчанию, которое может заменять пропущенные операнды в арифметических выражениях. Ниже объясняется, как в этом случае может использоваться функция, определенная пользователем.
Операции над последовательностями
Оператор intersect порождает последовательность, в которую включены все узлы, имеющиеся в обоих операндах. Оператор except позволяет получить последовательность, содержащую все узлы, которые есть в первом операнде, но отсутствуют во втором.
Операторы union, intersect и except возвращают последовательность узлов в порядке документа и удаляют дубликаты из получившихся последовательностей с учетом индивидуальности узлов. Запрос Q6 является примером использования оператора intersect.
(Q6) Создать новый элемент с именем recent-large-bids, содержащий копии всех элементов bid документа bids.xml, которые имеют bid-amount со значением больше 1000 и bid-date со значением позже 1 января 2002 года.
recent-large-bids
document(bids.xml)
/*/ bid [bid-amount 1000.00]
intersect
document(bids.xml)
/*/ bid [bid-date date(2002-01-01)]
/recent-large-bids
Выражения, в которых используются операции union, intersect и except, часто можно представить в другом виде. Так, запросу Q6 эквивалентен следующий запрос.
recent-large-bids
document(bids.xml)/*/bid
[bid-amount 1000.00 and bid-date
date(2002-01-01)]
/recent-large-bids
Важно помнить о том, что intersect и except бессмысленно использовать для комбинирования узлов разных документов, поскольку узлы в разных документах никогда не могут быть идентичными. Рассмотрим следующий запрос.
document(items.xml)//itemno
except
document(bids.xml)//itemno
В этом запросе операция except применяется к двум последовательностям узлов itemno. Поскольку последовательности узлов выбираются из различных документов, ни один узел во второй последовательности не может быть идентичен узлу из первой последовательности. Результатом запроса будет последовательность всех узлов itemno документа items.xml. Если предполагалось с помощью этого запроса получить список элементов itemno для товаров, которые не имеют ставок, то можно добиться этого воспользовавшись библиотечной функцией empty, которая возвращает true, если ее операнд — пустая последовательность.
for $i in document(items.xml)//item
where empty(document(bids.xml)
//bid [itemno eq $i/itemno])
return $i/itemno
В этом примере предикат itemno eq $i/itemno сравнивает два узла itemno, извлекая и сравнивая их содержимое, а не проверяя их идентичность.
Операция |, оставленная для совместимости с XPath 1.0, эквивалентна операции union. Эти операции иногда применяются в шагах выражения пути. Например, следующее выражение пути находит объединение всех потомков b и потомков c узлов в последовательности, связанной с $a; узлы в этом объединении затем используются в качестве контекстных узлов для следующего шага в пути.
$a/(b | c)/d
Условные выражения
Условные выражения обеспечивают возможность выполнения одного из двух выражений в зависимости от значения третьего выражения. Это записывается в знакомом формате if...then...else, поддерживаемом во многих языках. Требуется наличие всех трех условий (if, then и else), а выражение в условии if должно быть заключено в скобки. Результат всего условного выражения зависит от значения выражения в условии if, называемого выражением проверки (test expression). Правила таковы.
Если значением выражения проверки являются булевское значение true или непустая последовательность (используемая как «проверка существования»), то выполняется оператор then.
Если значением выражения проверки являются булевское значение false или пустая последовательность, то выполняется оператор else.
В противном случае условное выражение возвращает значение ошибки.
Следующее простое условное выражение может быть использовано для получения стоимости товара, в зависимости от существования атрибута с именем discounted.
if ($part/@discounted) then $part/wholesale
else $part/retail
Кванторные выражения
Кванторные выражения позволяют проверить некоторое условие, устанавливая, истинно ли оно для некоторого значения последовательности (называется квантором существования) или для всех значений последовательности (называется квантором всеобщности). Результатом всегда является true или false.
Как и FLWR-выражение, кванторное выражение позволяет переменной выполнять итерацию над объектами в последовательности; выполняется поочередное связывание этой переменной с каждым элементом последовательности. Для каждого связывания переменной вычисляется проверочное выражение. Кванторное выражение, которое начинается с some, возвращает значение true, если выражение проверки истинно для некоторого связывания переменной.
some $n in (5,7,9,11)satisfies $n 10
Кванторное выражение, начинающееся с every, возвращает значение true, если выражение проверки истинно для всех связываний переменной. Например, следующее кванторное выражение возвращает значение false, поскольку выражение проверки истинно не для всех связываний.
every $n in (5,7,9,11)satisfies $n 10
Использование кванторных выражений иллюстрируется запросом Q7.
(Q7) Найти товары в items.xml, для которых все полученные ставки более чем вдвое превысили начальную цену. Получить копии всех таких элементов item, и поместить их в новый элемент с именем underpriced-items.
underpriced items
for $i in document(items.xml)
where every $b in document(bids.xml)
/*/bid [itemno = $i/itemno]
satisfies $b/bid-amount
2 * $i/reserve-price
return $i
underpriced items
Функции
В XQuery предусмотрена библиотека предопределенных функций, а также предоставляется возможность определения пользователями их собственных функций. При вызове аргументы связываются с параметрами функции, и выполняется ее тело, порождая результат вызова функции. Если тип параметра функции не указан, этот параметр может принимать значения любого типа. Если не указан тип результата функции, то функция может возвращать значение любого типа.
В следующем примере определена функция с именем highbid, в качестве параметра использующая узел-элемент и возвращающая десятичное значение. Функция интерпретирует свой параметр как элемент item и извлекает номер товара. Затем она находит и возвращает самую крупную ставку (bid-amount), которая была зафиксирована для товара с этим номером.
define function highbid(element $item)
returns decimal
{
max(document(bids.xml)
//bid [itemno = $item/itemno]/bid-amount)
}
highbid(document(items.xml)
//item [itemno = 1234])
Типы, используемые при объявлении типов аргументов и результата в определении функции, могут быть простыми, как decimal, или более сложными типами, например, элементами или атрибутами.
В XQuery не поддерживается перегрузка функций, определенных пользователем, т. е. не допускается наличие двух функций с одинаковыми именами. Тем не менее, некоторые встроенные функции являются перегруженными. Например, функция string может преобразовывать в строку аргумент почти любого типа.
Аргументы при вызове функции должны соответствовать объявленным типам параметров функции. С этой целью аргумент функции числового типа может быть приведен к объявленному типу параметра с помощью иерархии приведения integer - decimal - float - double. Аргумент также считается удовлетворяющим условию вызова, если тип этого аргумента является производным типом (т.е. подтипом) объявленного типа параметра. Если функция, ожидающая атомарное значение в качестве параметра, вызывается с аргументом, являющимся элементом, то до передачи аргумента функции из него извлекается типизированное значение элемента и проверяется на совместимость с ожидаемым типом параметра. Значение, производимое телом функции, должно также соответствовать возвращаемому типу, объявленному в определении; используются обычные правила проверки соответствия типов параметров.
Следующий пример иллюстрирует, как пользователь может написать функцию, которая предоставляет значение по умолчанию для отсутствующих данных. Функция с именем defaulted принимает два параметра: узел-элемент (возможно, отсутствующий) и значение по умолчанию. Если элемент присутствует и имеет непустое значение, функция возвращает это значение. Если же элемент отсутствует или пуст, функция возвращает значение по умолчанию.
define function defaulted
(element? $e, anySimpleType $d)
returns anySimpleType
{
if (empty($e))then $d
else if (empty($e/_)then $d
else data($e)
}
С помощь этой функции запрос Q5 можно переписать (здесь отсутствующие или пустые элементы commission и bonus считаются равными нулю).
for $e in $emps
return
emp
{
$e/name,
pay | {$e/salary
+ defaulted ($e/commission,0)
+ defaulted ($e/bonus,0)}
/pay
}
/emp
sortby(pay)
Функция, в теле которой присутствует вызов самой себя, называется рекурсивной (recursive), и две функции, в теле каждой из которых присутствует вызов другой функции пары, называются взаимно рекурсивными (mutually recursive). В следующем примере рекурсивная функция depth может быть вызвана для элемента и возвращает глубину элемента в иерархии, начинающейся с аргумента вызова. Если у элемент-аргумента отсутствуют потомки, глубина иерархии равна единице. Иначе глубина иерархии на единицу больше максимального значения глубины всех иерархий, корнем которых является потомок элемента-аргумента. Это значение вычисляется путем рекурсивного вызова функции depth.
define function depth(element $e)
returns integer
{
if (empty($e/*)) then 1
else 1 + max
(for $c in $e/* return depth($c))
}
depth(document(bids.xml))
Типы
При создании запроса иногда необходимо сослаться на некоторый тип. Например, как уже было отмечено, при определении функции требуется описать типы параметров функции и ее результата. В других видах выражений XQuery также требуется возможность ссылаться на некоторые типы.
Один из способов сослаться на тип — это указать его квалифицированное имя, или QName. QName может указывать на встроенный тип, такой как xs:integer, или на тип, который определен в некоторой схеме, такой как abc:address. Если в QName имеется префикс пространства имен (часть, расположенная слева от двоеточия), этот префикс должен быть привязан к некоторому идентификатору пространства имен. Это связывание достигается путем описываемого в следующем разделе объявления пространства имен в прологе запроса.
Еще один способ сослаться на тип — сделать это с помощью родового ключевого слова, такого как element или attribute. За этим ключевым словом может следовать QName, которое в большей степени ограничивает имя или тип узла.
За ссылкой на тип может следовать один из трех индикаторов присутствия: «*» означает «ноль или больше», «+» означает «один или больше», а «?» означает «ноль или один». Отсутствие индикатора присутствия означает присутствие ровно одного экземпляра указанного типа.
Проверка корректности
Процесс проверки корректности может выполняться применительно к документу XML или к части документа, например, отдельному элементу.
В запросной модели данных с каждым узлом-элементом ассоциируется аннотация типа. Аннотация типа свидетельствует о том, что данный элемент прошел проверку на соответствие определенному заявленному типу. Элементы, которые не прошли проверку или не соответствуют заявленному типу, получают аннотацию родового типа anyType.
Структура запроса
В XQuery запрос состоит из двух частей, называемых прологом запроса (query prolog) и телом запроса (query body). Пролог состоит из серии объявлений, которые определяют среду для обработки тела. Тело запроса — просто выражение, чье значение определяет результат запроса.
Пролог нужен только в том случае, если тело зависит от одного или нескольких пространств имен, схем или функций. Если такая зависимость существует, объекты, от которых зависит тело запроса должны быть объявлены в прологе запроса.
Помимо объявлений пространств имен пролог запроса может содержать одно или несколько объявлений импорта схемы. При объявлении импорта схемы указывается URI схемы, а также может быть указан второй URI, определяющий место, где может быть найден файл схемы. Цель импорта заключается в том, чтобы предоставить процессору запросов определения элементов, атрибутов и типов, которые объявлены в указанной схеме. Процессор запросов может использовать эти определения для проверки вновь сконструированных элементов, для оптимизации и для проведения статического анализа типов в запросе.
Помимо объявлений пространства имен и импорта схем пролог запроса может содержать одно или несколько определений функции. Функции, определенные в прологе запроса, могут использоваться в теле запроса или в телах других функций.
Итоги
XQuery определяется в терминах модели данных, основанной на неоднородных последовательностях узлов и атомарных значениях. Экземпляр этой модели данных может содержать один или несколько документов или фрагментов документов XML. Запрос состоит из пролога, который устанавливает среду обработки, и выражения, которое генерирует результат запроса.
В настоящее время XQuery определен на уровне предварительных рабочих документов. Обсуждаются функции полнотекстового поиска, сериализация результатов запроса, обработка ошибок и ряд других вопросов. Скорее всего, окончательная спецификация XQuery будет включать в себя несколько уровней соответствия; например, в ней может быть определено, как следует производить статическую проверку типов, но не будет требоваться, чтобы она выполнялась в каждой реализации, соответствующей спецификации.
Подобно тому, как XML применяется в качестве универсального формата обмена информацией в Сети, XQuery призван служить в качестве универсального формата обмена запросами. Если XQuery получит признание в качестве стандартного средства извлечения информации из источников XML-данных, это поможет реализовать потенциал XML.
XPath
XPath (XML Path Language) является языком для обращения к частям XML-документа.
XPath был создан чтобы организовать доступ к элементам документа XML из файла стилей XSLT. XPath создан на основе XML и является стандартом консорциума W3C.
В XPath используется компактный синтаксис, отличный от принятого в XML.
В 2007 году завершилась разработка версии 2.0, которая теперь является составной частью языка XQuery.
Основные элементы путей адресации
Здесь стоит остановиться и вспомнить, что XML документ имеет древовидную структуру. В документе имеется всегда один и только один корневой элемент. Инструкция ?xml version=1.0? к дереву отношения не имеет. У элементов дерева существуют потомки (или дети) и предки (или родители), у корневого элемента предков нет.
Элементы дерева могут иметь уровни вложенности (далее уровни). У элементов на одном уровне бывают предыдущие и следующие элементы; соответственно, у первого элемента нет предыдущего, а у последнего нет следующего.
root - корневой элемент
node1 - предок - root, следующий на уровне - node2, имеет потомка node11
node11/ - имеет предка node1
/node1
node2/ - предыдущий элемент - node1, следующий - node3, предок - root
node3/
/root
XPath призван помочь обходить всевозможные деревья, вытаскивать необходимые элементы из другой ветви относительно точки обхода, узнавать родителей, детей, атрибуты. Это полноценный язык навигации по дереву.
Для нахождения элемента (-ов) в дереве документа используются пути адресации. Например, рассмотрим такой XML документ:
html
body
divПервый див
spanспан в первом диве/span
/div
divВторой див/div
divТретий див
span class=textпервый спан в третьем диве/span
span class=textвторой спан в третьем диве/span
spanтретий спан в третьем диве/span
/div
img /
/body
/html
Рассмотрим также путь адресации /html/body/*/span[@class] (полный синтаксис имеет вид /child::html/child::body/child::*/child::span[attribute::class]), который вернет набор из двух элементов исходного документа (span class=textпервый спан в третьем диве/span и span class=textвторой спан в третьем диве/span). Путь делится на шаги адресации которые разделяются символом косая черта / . В свою очередь, каждый шаг адресации состоит из трех частей:
- ось (в данном примере child::), это обязательная часть;
- условие проверки узлов (в данном примере это имена элементов документа html, body, span, а символ * означает элемент с любым именем), это обязательная часть;
- предикат (в данном примере attribute::class), необязательная часть заключаемая в квадратные скобки в которой могут содержаться оси, условия проверки, функции, операторы (+, -, , ) и проч.
Анализ выражения
Анализ ведется слева направо. Если первый символ это / , то путь адресации считается абсолютным. При этом за узел контекста на первом шаге берется корневой элемент (html). Контекст - это некая точка отсчета, относительно которой расчитывается следующий шаг адресации. Поэтому на каждом шаге адресации мы получаем новый набор узлов документа, и этот набор становится контекстом для следующего шага адресации.
На втором шаге адресации (child::body) контекстом становится html элемент. Ось child:: говорит о том, что необходимо найти все непосредственные потомки элемента html, а условие проверки body говорит о том, что в формируемый набор элементов нужно включить все узлы с именем body. В ходе второго шага адресации получаем набор узлов, состоящий всего из одного элемента body, который и становится элементом контекста для третьего шага.
Третий шаг адресации: child::* . Ось child:: собирает все непосредственные потомки элемента body, а условие проверки * говорит о том, что в формируемый набор нужно включить элементы основного типа с любым именем. В ходе этого шага получаем набор узлов, состоящий из трех элементов div и одного элемента img.
Четвертый шаг адресации: child::span . Теперь контекстом является набор из четырех элементов. И следующий набор узлов создается в четыре прохода (за четыре итерации). При первой итерации узлом контекста становится первый div. Согласно заданной оси child:: и правилу проверки span, в набор включаются непосредственные потомки div-а, имя которых равно span. При второй итерации в набор ничего добавлено не будет, т.к. у второго div нет потомков. Третья итерация добавить в набор сразу три элемента span, а четвертая ничего не добавит, т.к. у элемента img нет потомков. Итак, в ходе проверки получен набор узлов, состоящий из четырех элементов span. Это и будет контекстом для последующей обработки.
Следующего шага нет, поэтому будет производиться фильтрация отобранного набора. В этом и состоит отличие предикатов от шагов адресации. На каждом шаге адресации получаем новый набор, отталкиваясь от контекста, полученного на предыдущем шаге. В ходе же обработки предиката новый набор получается из текущего методом фильтрации, когда из набора исключаются узлы, не прошедшие условие проверки. В данном случае ось attribute:: говорит о необходимости проверить, если ли у узлов контекста атрибуты, а условие class требует оставить лишь те узлы, у которых задан атрибут с именем class. Фильтрация происходит за четыре итерации, но в окончательный набор попадают только два элемента span.
Оси
Оси это база языка XPath.
ancestor:: Возвращает множество предков.
ancestor-or-self:: Возвращает множество предков и текущий элемент.
attribute:: Возвращает множество атрибутов текущего элемента.
child:: Возвращает множество потомков на один уровень ниже.
descendant:: Возвращает полное множество потомков.
descendant-or-self:: Возвращает полное множество потомков и текущий элемент.
following:: Возвращает необработанное множество, ниже текущего элемента.
following-sibling:: Возвращает множество элементов на том же уровне, следующих за текущим.
namespace:: Возвращает множество имеющее пространство имён (т.е. присутствует атрибут xmlns).
parent:: Возвращает предка на один уровень назад.
preceding:: Возвращает множество обработанных элементов исключая множество предков.
preceding-sibling:: Возвращает множество элементов на том же уровне, предшествующих текущему.
self:: Возвращает текущий элемент.
Существуют сокращения для некоторых осей, например:
attribute:: можно заменить на @
child:: часто просто опускают
descendant:: можно заменить на //
parent:: можно заменить на ..
self:: можно заменить на .
Дополнением к базе является набор функций, которые делятся на 5 групп:
Системные функции
node-set document (objec!, node-set?) - Возвращает документ указанный в параметре objec!.
string format-number (number, string, string?) - Форматирует число согласно образцу указанному во втором параметре, третий параметр указывает именованный формат числа, который должен быть учтён.
string generate-id (node-set?) - Возвращает строку, являющуюся уникальным идентификатором.
node-set key (string, objec!) - Возвращает множество с указанным ключом, аналогично функции id для идентификаторов.
string unparsed-entity-uri (string) - Возвращает непроанализированный URI, если такового нет, возвращает пустую строку.
boolean element-available (string) - Проверяет доступен ли элемент или множество указанное в параметре. Параметр рассматривается как XPath.
boolean function-available (string) - Проверяет доступна ли функция указанная в параметре. Параметр рассматривается как XPath.
objec! system-property (string) - Возвращает системные переменные параметр может быть:
xsl:version - возвращает версию XSL-T процессора.
xsl:vendor - возвращает производителя XSL-T процессора.
xsl:vendor-url - возвращает URL идентифицирующий производителя.
Если используется неизвестный параметр, функция возвращает пустую строку
boolean lang (string) - Возвращает истину если у текущего тэга имеется атрибут xml:lang, либо родитель тэга имеет атрибут xml:lang и в нем указан совпадающий строке символ.
Функции с множествами
* - обозначает любое имя или набор символов, @* - любой атрибут.
$name - обращение к переменной, где name - имя переменной или параметра.
[] - дополнительные условия выборки.
{} - если применяется внутри тега другого языка (например HTML), то XSL-T процессор, то что написанно в фигурных скобках рассматривает как XPath.
/ - определяет уровень дерева.
node-set node() - Возвращает элемент (-ы). Для этой функции часто используют заменитель *, но в отличии от звездочки - node() возвращает и текстовые элементы.
node-set current() - Возвращает множество из одного элемента, который является текущим. Если мы делаем обработку множества с условиями, то единственным способом дотянутся из этого условия до текущего элемента будет данная функция.
number position() - Возвращает позицию элемента в множестве. Корректно работает только в цикле xsl:for-each/.
number last() - Возвращает номер последнего элемента в множестве. Корректно работает только в цикле xsl:for-each/.
number count (node-set) - Возвращает количество элементов в node-set.
string name (node-set?) - Возвращает полное имя первого тэга в множестве.
string namespace-uri (node-set?) - Возвращает ссылку на uri определяющий пространство имён.
string local-name (node-set?) - Возвращает имя первого тэга в множестве, без пространства имён.
node-set id (objec!) - Находит элемент с уникальным идентификатором.
Строковые функции
string text() - Возвращает текстовое содержимое элемента. По сути возвращает объединенное множество текстовых элементов на один уровень ниже.
string string (object?) - Конвертирует объект в строку.
string concat (string, string, string*) - Объеденяет две или более строк
number string-length (string?) - Возвращает длину строки.
boolean contains (string, string) - Возвращает истину, если первая строка содержит вторую, иначе возвращает ложь.
string substring (string, number, number?) - Возвращает строку вырезанную из строки начиная с указанного номера, и если указан второй номер - количество символов.
string substring-before (string, string) - Если найдена вторая строка в первой, возвращает строку до первого вхождения второй строки.
string substring-after (string, string) - Если найдена вторая строка в первой, возвращает строку после первого вхождения второй строки.
boolean starts-with (string, string) - Возвращает истину, если вторая строка входит в начало первой, иначе возвращает ложь.
string normalize-space (string?) - Убирает лишние и повторные пробелы, а так же управляющие символы, заменяя их пробелами.
string translate (string, string, string) - Заменяет символы первой строки, которые встречаются во второй строке, на соответствующие по позиции символам из второй строки символы из третьей строки.
translate(bar,abc,ABC) - вернет BAr.
Логические функции
or - логическое или.
and - логическое и.
= - логическое равно.
(lt;) - логическое меньше.
(gt;) - логическое больше.
= (lt;=) - логическое меньше либо равно.
= (gt;=) - логическое больше либо равно.
boolean boolean (object) - приводит объект к логическому типу.
boolean true() - Возвращает истину.
boolean false() - Возвращает ложь.
boolean not (boolean) - Отрицание, возвращает истину, если аргумент ложь и наоборот.
Числовые функции
+ - сложение.
- - вычитание.
* - умножение.
div – деление.
mod - остаток от деления.
number number (object?) - Переводит объект в число.
number sum (node-set) - Вернёт сумму множества, каждый тэг множества будет преобразован в строку и из него получено число.
number floor (number) - Возвращает наибольшее целое число, не большее, чем аргумент.
number ceiling (number) - Возвращает наименьшее целое число, не меньшее, чем аргумент.
number round (number) - Округляет число по математическим правилам.
Способы просмотра XML-документов
XML никак не определяет способ отображения и использования описываемых с его помощью элементов документа, т.е. программе-анализатору предоставляется возможность самой выбирать нужное оформление. Этого требует принцип независимости определения внутренней структуры документа от способов представления этой информации. Например, задавая в документе элемент flowerроза/flower, мы лишь указываем, что rose в данном случае является цветком, но информации о том, как должен выглядеть данный элемент документа на экране клиента и должен ли он отображаться вообще, в таком определении нет.
Для того чтобы использовать данные, определяемые элементами XML, например, отображать их на экране пользователя, необходимо написать программу-анализатор, которая бы выполняла эти действия. Уже сегодня таких программ появилось достаточное количество и у разработчиков существует возможность выбора наиболее подходящей из них для решения конкретных проблем.
Как уже отмечалось ранее, в общем случае, программы- анализаторы можно разделить на две группы: верифицирующие (т.е. использующие DTD- описания для определения корректности документа) и не верифицирующие. Если создать свой язык и описывать его грамматику на основе DTD, то для анализа документов, написанных на этом языке, безусловно, потребуется программа, проверяющая корректность составления документа. Но так как использование DTD в XML не является обязательным, то любой правильно оформленный документ может быть распознан и разобран программой, предназначенной для анализа XML- документов. В любом случае, используя универсальные XML- анализаторы, можно быть уверенным в том, что если заданные в документе конструкции языка являются синтаксически правильными, то программа-анализатор сможет правильно извлечь определяемые ими элементы документа и передать их прикладной программе, выполняющей необходимые действия по отображению. Т.е. после разбора документа в большинстве случаев, предоставляется объектная модель, отображающая содержимое документа, и средства, необходимые для работы с ней (прохода по дереву элементов). При этом в некоторых анализаторах способ представления структуры документа основывается на спецификации DOM. Поэтому появляется также возможность использовать строгую иерархическую модель DOM для построения собственных документов.
Если речь идет о способах отображения информации, хранящейся в XML, то необходимо упомянуть разрабатываемый в настоящее время W3C стандарт стилевых таблиц для XML, которые предназначены для описания правил отображения элементов XML.
Отображение XML во Всемирной паутине
XSL является технологией, описывающей как форматировать или трансформировать данные XML документа. Документ трансформируется в формат, подходящий для отображения в браузере. Процесс аналогичен применению CSS к HTML документу для отображения. Браузер это наиболее частое использование XSL, но не стоит забывать, что с помощью XSL можно трансформировать XML в любой формат, например VRML, PDF, текст.
Без использования CSS или XSL, XML-документ отображается как простой текст в большинстве web-браузеров. Некоторые браузеры, такие как Internet Explorer, Mozilla и Mozilla Firefox отображают структуру документа в виде дерева, позволяя сворачивать и разворачивать узлы с помощью нажатий клавиши мыши.
Для применения CSS при отображении в браузере, XML документ должен содержать специальную ссылку на таблицу стилей. Например:
?xml-stylesheet type=text/css href=myStyleSheet.css?
Это отличается от подхода HTML, где используется элемент link.
Для задания XSL трансформации (XSLT) на стороне клиента требуется наличие следующей инструкции в XML:
?xml-stylesheet type=text/xsl href=transform.xsl?
Стилевые таблицы XSL
Для вывода элементов XML- документа на экран браузера предпочтительней использование специально предназначенного для этого средства - стилевых таблиц XSL (Extensible Stylesheet Language).
Стилевыми таблицами (стилевыми листами) принято называть специальные инструкции, управляющие процессом отображения элемента в окне программы-клиента (например, в окне браузера). Предложенные в качестве рекомендация W3C, каскадные стилевые таблицы (CSS- Cascading Style Sheets) используются Web- разработчиками для оформления Web- страниц. Поддержка CSS наиболее известными на сегодняшний день браузерами Netscape Navigator (начиная с версии 4.0) и Microsoft Explorer (начиная с версии 3.0), позволила использовать стилевые таблицы для решения самого широкого спектра задач - от оформления домашней странички до создания крупного корпоративного Web-узла. Слово каскадные в определении CSS означает возможность объединения отдельных элементов форматирования путем вложенных описаний стиля. Например, атрибуты текста, заданные в тэге body, будут распространяться на вложенные тэги до тех пор, пока в них не встретятся стилевые описания, отменяющие или дополняющие текущие параметры. Таким образом, использование таблиц CSS в HTML было весьма эффективно - отпадала необходимость явного задания тэгов форматирования для каждого из элементов документа.
Являясь очень мощным средством оформления HTML- страниц, CSS- таблицы, тем не менее, не могут применяться в XML-документах, т.к. набор тэгов в этом языке не ограничен и использование статических ссылок на форматируемые объекты документа в этом случае невозможно.
Поэтому для форматирования XML- элементов был разработан новый язык разметки, являющийся подмножеством XML, и специально был предназначен для форматирования XML- элементов.
Некоторые его отличия от CSS:
Во-первых, стилевые таблицы XSL позволяют определять оформление элемента в зависимости от его месторасположения внутри документа, т.е. к двум элементам с одинаковым названием могут применяться различные правила форматирования.
Во-вторых, языком, лежащем в основе XSL, является XML, а это означает, что XSL более гибок, универсален и у разработчиков появляется возможность использования средства для контроля за корректностью составления таких стилевых списков (используя DTD или схемы данных)
В-третьих, таблицы XSL не являются каскадными, подобно CSS, т.к. чрезвычайно сложно обеспечить каскадируемость стилевых описаний, или, другими словами, возможность объединения отдельных элементов форматирования путем вложенных описаний стиля, в ситуации, когда структура выходного документа заранее неизвестна и он создается в процессе самого разбора. Однако в XSL существует возможность задавать правила для стилей, при помощи которых можно изменять свойства стилевого оформления, что позволяет использовать довольно сложные приемы форматирования
В настоящий момент язык XSL находится на стадии разработки в W3C и в будущем, видимо, станет частью стандарта XML. Это означает, что использование этого механизма является наиболее перспективным способом оформления XML- документов. В текущем рабочем варианте W3C, XSL рассматривается не только как язык разметки, определяющий стилевые таблицы - в него заложены средства, необходимые для выполнения действий по фильтрации информации, выводимой в окно клиента, поиска элементов, сложного поиска, основанного на зависимостях между элементами и т.д. На сегодняшний день единственным браузером, поддерживающим некоторые из этих возможностей, является бета-версия Internet Explorer 5.0, однако в самом ближайшем будущем, безусловно, XSL будет использоваться также широко, как сегодня стандартные тэги HTML.
Словари XML
Так как XML является достаточно абстрактным языком, были разработаны словари XML. Словарь позволяет разработчикам договориться о некотором конечном наборе имен тегов и атрибутов этих тегов. Одним из первых словарей появился XHTML, который понимают большинство браузеров. XHTML часто используют для хранения и редактирования контента в CMS.
Были созданы более специализированные словари, например протокол передачи данных SOAP, который не является человеко-ориентированным и достаточно трудно читаем. Есть коммерческие словари, такие как xCBL и cXML которые используются для передачи данных, ориентированных на торговую деятельность, эти словари включают в себя описание системы заказов, поставщиков, продуктов и прочее. Обычно, описывая какой-либо документ, человек для себя придумывает некоторый словарь, который потом описывается посредством DTD или просто объясняется «на пальцах» заинтересованным лицам.
Одним из интересных словарей, получивших широкое распространение, является FB2 — словарь, описывающий формат книги, со всевозможными сносками, цитатами и даже картинками.
Приложение
Пример XML-документа
?xml version=1.0?
journal
titleVery Useful Journal/title
contacts
addresssdsds/address
tel8-3232-121212/tel
tel8-3232-121212/tel
emailj@j.ru/email
urlwww.j.ru/url
/contacts
issues-list
issue index=2
titleXML today/title
date12.09.98/date
aboutXML/about
home-urlwww.j.ru/issues//home-url
articles
article ID=3
titleIssue overview/title
url/article1/url
hotkeys
hotkeylanguage/hotkey
hotkeymarckup/hotkey
hotkeyhypertext/hotkey
/hotkeys
article-finished/
/article
article
titleLatest reviews/title
url/article2/url
author ID=3/
hotkeys
hotkey/
/hotkeys
/article
article ID=4
title/
url/
hotkeys/
/article
/articles
/issue
/issues-list
authors-list
author ID=1
firstnameIvan/firstname
lastnamePetrov/lastname
emailvanya@r.ru/email
/author
author ID=3
firstnamePetr/firstname
lastnameIvanov/lastname
emailpetr@r.ru/email
/author
author ID=4
firstnameSidor/firstname
lastnameSidorov/lastname
emailsidor@r.ru/email
/author
/authors-list
/journal
DTD-определение для XML-документа
?xml version=1.0?
!ENTITY idattr id ID #IMPLIED
!ENTITY opt title?,date,about
!ENTITY cont tel*,url*,email*
!ELEMENT title (PCDATA)
!ELEMENT firstname (PCDATA)
!ELEMENT lastname (PCDATA)
!ELEMENT email (PCDATA)
!ELEMENT url (PCDATA)
!ELEMENT tel (PCDATA)
!ELEMENT address (PCDATA)
!ELEMENT fax (PCDATA)
!ELEMENT date (PCDATA)
!ELEMENT home-url (PCDATA)
!ELEMENT article-url (PCDATA)
!ELEMENT hotkey (PCDATA)
!ELEMENT article-finished EMPTY
!ELEMENT contents ANY
!ELEMENT hotkeys (PCDATA| hotkey)
!ELEMENT author (PCDATA| firstname?|lastname?|cont)
!ATTLIST author
id ID #REQUIRED
!ELEMENT authors (PCDATA| author*)
!ELEMENT article (opt,author,article-url,hotkeys*,contents*,article-finished)
!ATTLIST article
id ID #REQUIRED
!ELEMENT articles (article)
!ELEMENT issue (opt,home-url?,articles*)
!ATTLIST issue
id ID #REQUIRED
index CDATA #REQUIRED
!ELEMENT issues-list (PCDATA| issue*)*
!ELEMENT contacts (address, cont)
!ELEMENT journal (title?,contacts?,isues-list,authors-list)
!ATTLIST journal
id ID #REQUIRED
src CDATA #IMPLIED
Заключение
XML-лихорадка затронула многие области современных информационных систем. Наиболее активно развиваются следующие направления XML-эволюции: системы управления контентом; информационные серверы и базы данных; инструментарий для проектирования и создания сайтов; публичные форматы обмена финансовой информацией; системы управления порталами; системы управления торговыми площадками.
XML сегодня перестает быть интересной игрушкой, стремительно превращаясь в мощную систему промышленных стандартов. Всеобщее восхищение новой технологией заменяется сегодня активными действиями по проверке ее жизнеспособности.
Многие специалисты рассматривают XML как новую технологию интеграции программных компонент. Основными преимуществами использования XML являются:
· Интеграция данных из различных источников. XML можно использовать для объединения разнородных структурированных данных на среднем уровне трехуровневых Web-систем, баз данных.
· Локальная обработка данных. Полученные данные в формате XML можно разбирать, обрабатывать и отображать непосредственно на клиенте без дополнительных обращений к серверу.
· Просмотр и манипулирование данными в различных разрезах. Полученные данные могут обрабатываться и просматриваться клиентом различными способами в зависимости от нужд конечного пользователя.
· Возможность частичного обновления данных. С помощью XML можно обновлять только ту часть структурированных данных, которая была изменена, а не всю структуру целиком.
Все эти преимущества делают XML незаменимым инструментом для разработки гибких средств поиска информации в базах данных, мощных трехуровневых Web-приложений, а также приложений, поддерживающих транзакции. Другими словами, с помощью XML можно формировать запросы к базам данных различных структур, что позволяет осуществлять поиск информации в многочисленных несовместимых друг с другом базах данных. Использование XML на среднем уровне трехуровневых Web-приложений позволяет осуществлять эффективный обмен данными между клиентами и серверами систем электронной коммерции.
Кроме того, язык XML может использоваться в качестве средства для описания грамматики других языков и контроля правильности составления документов.
Инструменты обработки данных, полученных в формате XML, могут быть разработаны в среде Visual Basic, Java или C++.
Список литературы
1. Чего мы ждем от XMLШелли Пауэрс(Мир ПК 3/1998 г.) - http://www.osp.ru/pcworld/1998/03/180.htm
2. XML - http://ru.wikipedia.org:80/wiki/XML
3. SGML - http://ru.wikipedia.org/wiki/SGML
4. XPath - http://ru.wikipedia.org/wiki/XPath
5. XQuery - http://ru.wikipedia.org/wiki/XQuery
6. Язык XML (практическое введение), Александр Печерский - www.citforum.ru.
7. Расширяемый язык разметки (XML) 1.0 (вторая редакция) - http://www.rol.ru/news/it/helpdesk/xml01.htm.
8. Создание XML-документов – http://Relib.com
9. Системы управления контентом -http:// www. softerra. ru/ review/ internet
10. Журнал для профессионалов в области информациооных технологий «Открытые системы», №1, январь 2003г.
Предметный указатель
А
анализатор........ 2, 14, 19, 20, 21, 23, 25, 27, 28, 29, 31, 32, 37, 54
атрибут......................... 2, 24, 28, 30, 31, 32, 36, 37, 41, 42, 48, 50
Г
генератор.................................................................................. 2, 13
З
запрос........................................................................... 5, 13, 32, 63
И
интерфейс......................................................................... 15, 16, 17
М
метаязык...................................................................................... 11
П
подмножество................................................................ 4, 8, 11, 56
С
синтаксис.................................................... 8, 11, 20, 27, 33, 45, 46
схема данных................................................... 2, 20, 34, 35, 37, 57
Т
тэг............... 7, 14, 19, 20, 21, 23, 24, 25, 36, 40, 50, 51, 52, 56, 57
Э
элемент 2, 3, 5, 6, 11, 14, 15, 16, 17, 21, 23, 24, 27, 28, 29, 30, 31, 32, 34, 35, 36, 37, 38, 39, 40, 41, 42, 45, 46, 47, 48, 49, 50, 51, 54, 55, 56, 57
Для заметок