Нечіткий метод групового врахування аргументів
СОДЕРЖАНИЕ: Курсова робота Тема: Нечіткий метод групового врахування аргументів Зміст Вступ 1 Стан проблеми математичного моделювання та прогнозування технологічних параметрів
Курсова робота
Тема: Нечіткий метод групового врахування аргументів
Зміст
Вступ
1 Стан проблеми математичного моделювання та прогнозування технологічних параметрів
1.1 Аналіз математичних моделей технологічних параметрів
1.2Аналіз методів математичного моделювання
1.3 Задачі технологічної підготовки виробництва, що розв’язуються за допомогою математичного моделювання
1.4 Аналіз існуючих методів отримання математичних моделей
2 Нечіткий метод групового врахування аргументів
2.1 Метод групового врахування аргументів як основа нечіткого методу
2.2 Суть нечіткого методу групового врахування аргументів
Висновки
Література
Вступ
Приладобудування одна з найбільш перспективних та розвинутих галузей сучасного промислового виробництва України. Приладобудування має широку номенклатуру виробів, що випускаються. Для технологічного проектування виробництва продукції різної складності, що використовується в різних галузях потрібні великі виробничі потужності, матеріальні та фінансові витрати.
Застосування ЕОМ при рішенні задач технологічного проектування виробництва дозволяє оперувати при оцінці досить складними схемами і формулами, але часто із-за недостатньої формалізації завдань ці залежності неадекватні реальним виробничим процесам. У звязку з цим основним методом оцінки рішень і вибору оптимального рішення є моделювання. При моделюванні рішень в даний час широко застосовують методи математичного та імітаційного моделювання. Для цього створюються спеціальні засоби. Методи математичного та імітаційного моделювання реалізуються на ЕОМ.
Таким чином ефективне розв’язання задач технологічного проектування виробництва можливе при наявності адекватних математичних та імітаційних моделей параметрів і показників технологічних процесів виготовлення виробів приладобудування.
Завдання цієї роботи знайти шляхи підвищення продуктивності праці шляхом застосування математичного моделювання, зокрема прогнозування технологічних параметрів, що скорочує час та збільшує продуктивність робити технологів.
1 Стан проблеми математичного моделювання та прогнозування технологічних параметрів і постановка задачі технологічної частини дипломної роботи
1.1 Аналіз математичних моделей технологічних параметрів
З розвитком системних досліджень, з розширенням експериментальних методів вивчення реальних явищ всього більшого значення набувають абстрактні методи, зявляються нові наукові дисципліни, автоматизуються елементи розумової праці. Важливе значення при створенні реальних систем S мають математичні методи аналізу і синтезу, цілий ряд відкриттів базується на чисто теоретичних дослідженнях. Проте було б неправильно забувати про те, що основним критерієм будь-якої теорії є практика, і навіть суто математичні науки базуються в своїй основі на фундаменті практичних знань.
Одночасно з розвитком теоретичних методів аналізу і синтезу удосконалюються і методи експериментального вивчення реальних обєктів, зявляються нові засоби дослідження. Проте експеримент був і залишається одним з основних і істотних інструментів пізнання. Подібність і моделювання дозволяють по-новому описати реальний процес і спростити експериментальне його вивчення. Удосконалюється і саме поняття моделювання. Якщо раніше моделювання означало реальний фізичний експеримент або побудову макету, що імітує реальний процес, то в даний час зявився новий вигляд моделювання, в основі яких лежить постановка не тільки фізичних, але також і математичних експериментів.
Пізнання реальної дійсності є тривалим і складним процесом. Визначення якості функціонування великої системи, вибір оптимальної структури і алгоритмів поведінки, побудова системи S відповідно до поставленої перед нею мети – основна проблема при проектуванні сучасних систем, тому моделювання можна розглядати як один з методів, використовуваних при проектуванні і дослідженні великих систем.
Моделювання базується на деякій аналогії реального і уявного експерименту. Аналогія – основа для пояснення явища, що вивчається, проте критерієм істини може служити тільки практика, тільки досвід. Хоча сучасні наукові гіпотези можуть створитися чисто теоретичним шляхом, але, по суті, базуються на широких практичних знаннях. Для пояснення реальних процесів висуваються гіпотези, для підтвердження яких ставиться експеримент або проводяться такі теоретичні міркування, які логічно підтверджують їх правильність. У широкому сенсі під експериментом можна розуміти деяку процедуру організації і спостереження якихось явищ, які здійснюють в умовах, близьких до природних, або імітують їх.
Розрізняють пасивний експеримент, коли дослідник лише спостерігає процес, і активний, коли спостерігач втручається і організовує процес. Останнім часом поширений активний експеримент, оскільки саме на його основі вдається виявити критичні ситуації, отримати найцікавіші закономірності, забезпечити можливість повторення експерименту в різних точках простору досліджень.
У основі будь-якого виду моделювання лежить модель, що базується на деякій загальній якості, яка характеризує реальний обєкт. Обєктивно реальний обєкт має деяку формальну структуру, тому для будь-якої моделі характерна наявність деякої структури, відповідній формальній структурі реального обєкту, або його частині.
У основі моделювання лежать інформаційні процеси, оскільки саме створення моделі М базується на інформації про реальний обєкт. В процесі реалізації моделі виходить інформація про даний обєкт, одночасно в процесі експерименту з моделлю вводиться інформація, що управляє, істотне місце займає обробка отриманих результатів, тобто інформація лежить в основі всього процесу моделювання.
1.2 Аналіз методів математичного моделювання
Перші дослідження в області різання металів в Росії були проведені проф. И.А. Тімі. Його можна вважати основоположником науки про різання металів. Проф. П.А. Афанась’єв і проф. К.А. Зворикін провели цікаві дослідження і розвинули основи теорії різання металів.
Великий обєм досліджень провів американський інженер, фахівець в області організації і нормування праці Ф.У. Тейлор. Вперше в світі він отримав формули (математичні моделі), що показують вплив різних чинників – умов обробки на швидкість різання. Головна мета досліджень була прикладною: провести в механічній майстерні найбільш дешевим способом якомога більшу кількість роботи кращої якості.
Ф.У. Тейлор багато разів звертає увагу на складності отримання математичних моделей. При аналізі основної роботи Мистецтво різати метали не було виявлено використання статистичних методів. Методика вибору структури формул не приводиться.
Звідси можна зробити висновок – Ф.У. Тейлору необхідно було проявити мистецтво не тільки проведенні досліджень по різанню металів, але і в отриманні формул. Подальші дослідники використовували запропонований Ф.У. Тейлором степеневий вид формул і були вимушені розробляти методологію отримання самих моделей, що описують роботу технологічних систем.
Проф. С.С. Рудник на нараді учених з новаторами виробництва відзначала, що немає достатньо надійних і зручних розрахункових теоретичних формул зусилля і швидкості різання і доводиться користуватися формулами, отриманими експериментальним шляхом.
Раніше в дослідженнях при отриманні математичних моделей шляхом проведення експериментів з обєктами і процесами був широко використаний метод однофакторного експерименту. У роботах Г.С. Ома, Дж. Клейнена, акад. А.Н. Крилова зустрічаємо рекомендації і згадки про використання так званого методу caeteris paribus, тобто змінювати чинники поодинці при інших рівних умовах.
Після публікації роботи Ф.У. Тейлора на зміну методології однофакторного експерименту в технології машинобудування прийшла методологія багатофакторного експерименту.
Обєднання окремо отриманих однофакторних залежностей в багатофакторну модель не дозволяє отримати дійсно багатофакторну математичну модель: це не можна зробити по самій суті зміни тільки одного чинника при всіх постійних решті чинників. Другим недоліком вказаного методу є неможливість встановлення різних взаємодій чинників.
Взаємодії факторів в отримуваних моделях враховував М.М. Зорев.
У роботах Н.С. Равської і П.Р. Родіна з дослідженню процесів обробки металів різанням і різального інструменту для прогнозу і оптимізації критеріїв якості процесів використовується метод групового врахування аргументів (МГВА) і в структуру степеневих залежностей вводяться взаємодії модельованих факторів.
Розробка сучасного інформаційного забезпечення проектування, оптимізації, надійності і інших проблем створення високоякісного ріжучого інструменту в Донбасівській державній машинобудівній академії проводиться під науковим керівництвом Г.Л. Хаєта .
В розробку теоретичних і прикладних проблем математичного моделювання значний внесок внесли: С.А. Айвазян, Б.М. Базров, Н.А. Бородачев, В.П. Бородюк, Н.П. Бусленко, В.А. Вознесенський, В.Н. Вапник, А.Н. Гаврилов, В.М. Глушков, Е.З. Демиденко, А.Г. Івахненко, Н.М. Капустін, П.Г. Кацев, А.И. Кухтенко, Ю.В. Лінник, В.С. Михальович, Н.Н. Моїсеєв, В.В. Налімов, Н.С. Равська, Н.С. Райбман, А.А. Самарський, Л.К. Сизенов, В.И. Скурихін, А.В. Усов, Г.Л. Хаєт, Т. Андерсон, И.Н. Вучков, Н. Дрейпер. М.Дж. Кендалл, Ф. Мостеллер, И.А. Мюллер, С.Р. Рао, Б. Ренц, Дж. Себер, Г. Сміт, А. Стьюарт, Дж. Тьюки, Е. Ферстер, П. Эйкхофф і ін.
1. 3 Задачі технологічної підготовки виробництва, що розв’язуються за допомогою математичного моделювання
Автоматизація виробництва вимагає інтеграції і автоматизації всіх робіт з технологічної підготовці виробництва (ТПВ). Інтеграція конструкторської, технологічної, організаційної і економічної підготовки виробництва полягає в забезпеченні достовірних своєчасних прямих і зворотних звязків між завданнями в цілях вибору оптимальних рішень на всіх етапах підготовки виробництва. Забезпечити безперервний ефективний звязок між завданнями можливо тільки в умовах автоматизації підготовки виробництва на основі єдиної інформаційної бази, яка включає постійну (нормативно-довідкову) і змінну інформацію, яка формується в процесі рішення задачі.
Але, не дивлячись на інтеграцію робіт, в підготовці виробництва можна виділити два самостійні види робіт, що відрізняються за складом і метою:
1. проектування або реорганізація виробництва (пряме завдання) (рис. 1);
2. експлуатація організованого виробництва (обернена задача проектування) (рис. 2).
3. Метою проектування виробництва є побудова виробничої системи і створення таких умов, які забезпечували б на протязі тривалого часу виготовлення запланованих і прогнозованих виробів в заданий термін і з мінімальними затратами. При проектуванні багатономенклатурної виробничої системи формується одна з найважливіших їх властивостей виробництва – його перенастроюваність (гнучкість). Метою сучасного виробництва є максимальне використання технічного рівня виробничої системи при виготовленні запланованих виробів. Це припускає максимізацію термінів проектування і виготовлення виробів при мінімальних витратах на ТПВ.
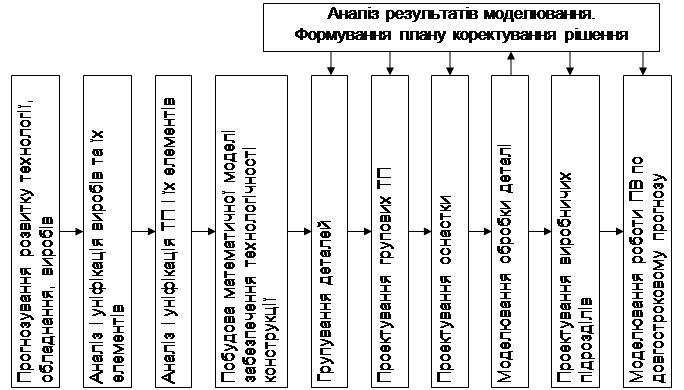
Рис. 1. Прямі завдання проектування
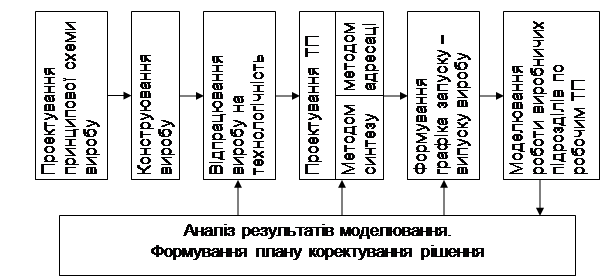
Рис. 2. Обернені завдання проектування
Інтеграція двох видів робіт при сумісному їх розгляді полягає в створенні при проектуванні виробництва технічної, організаційної і інформаційної баз, на основі яких приймаються рішення при експлуатації виробництва і досягається необхідна гнучкість виробничої системи.
В наведених схемах (рис. 1, 2) передбачені оцінки рішень і вибір ефективних рішень, для чого організовуються складні образні звязки (на схемах вказані не всі). У схемі проектування виробничої системи оптимізація проводиться при уніфікації, а також при проектуванні технологічного оснащення і виробничих підрозділів. При рішенні задач уніфікації визначається оптимальний склад уніфікованих виробів. При проектуванні групових операційних технологічних процесів (ТП) оптимізуються план обробки, склад інструментальних переходів, поєднання в обробці, при проектуванні технологічного оснащення – склад комплектів базових поверхонь і маршрутних ТП, при проектуванні виробничих підрозділів – маршрутний ТП, склад допоміжного, транспортно-накопичувального і складського устаткування, розміщення устаткування. У схемі (рис. 2) оптимізація виконується в процесі проектування ТП і формування плану-графіка при оперативному управлінні виробничими підрозділами. Очевидно, для розробки оптимальних варіантів робочих ТП необхідно допустити, щоб деяка сукупність деталей могла бути віднесена не до однієї, а до декількох груп. За рахунок такого «перетину» груп спрощується вибір оптимального варіанту ТП і плану-графіка виконання робіт.
Оцінка і порівняння варіантів рішення в обох схемах може проводитися по логічних і аналітичних залежностях. Застосування ЕОМ при рішенні задач ТПВ дозволяє оперувати при оцінці досить складними схемами і формулами, але часто із-за недостатньої формалізації завдань ці залежності неадекватні реальним виробничим процесам. У звязку з цим основним методом оцінки рішень і вибору оптимального рішення є моделювання. При моделюванні рішень в даний час широко застосовують методи математичного та імітаційного моделювання. Для цього створюються спеціальні засоби. Методи математичного та імітаційного моделювання реалізуються на ЕОМ.
До моделювання рішень вдаються в обох схемах (рис. 1, 2). Але в схемі проектування виробництва моделювання і вибір оптимального рішення проводять на основі довгострокового прогнозу розвитку виробів і технології, а в схемі експлуатації виробництва використовують реальні схеми організації технологічних процесів, устаткування, інструменти, пристосування і т.д. У звязку з цим в схемі проектування особливу увагу слід приділяти роботам по коротко- і довгостроковому прогнозуванню розвитку технології, виробів, устаткування.
Таким чином ефективне розв’язання задач ТПВ можливе при наявності адекватних математичних та імітаційних моделей параметрів і показників технологічних процесів виготовлення виробів приладобудування.
1. 4 Аналіз існуючих методів отримання математичних моделей
Моделювання та прогнозування з використанням методу найменших квадратів.
В основі логіки методу найменших лежить прагнення дослідника підібрати такі оцінки 0 ,1 ,…,p для невідомих значень параметрів функції регресії відповідно 0 ,1 ,…,p, при яких згладжені (регресійні) значення 0+1x1(1)+…+px1(p) результуючого показника якомога менше відрізнялись від відповідних спостережених значень yi. Спробуємо математично сформулювати цей принцип. Введемо у якості міри розходження згладженого та спостережуваного (в і-тому спостереженні) значень результуючого показника різницю
![]() (1)
(1)
(i – називаються невязками). Як бачимо, значення 0 ,1 ,…,p слід підбирати таким чином, щоб мінімізувати деяку інтегральну характеристику невязок. Нехай такою інтегральною характеристикою буде підганяння (вирівнювання) значень уі, за допомогою лінійної функції від xi(1) ,xi(2),…,xi(p) (i=1,2,…,n) величину
![]() (2)
(2)
Безперечно, величина Q буде визначатися конкретним вибором значень оцінок параметрів 0 ,1 ,…,p . Оцінки за методам найменших квадратів (МНК - оцінки) 0 МНК ,1 МНК ,…,p МНК якраз і підбираються таким чином, щоб мінімізувати величину Q, визначену співвідношенням (1), тобто
![]() (3)
(3)
Розглянемо випадок багатьох пояснюючих змінних у матричній формі:
![]()
вектор стовпчик невязок;
![]() -(4)
-(4)
оптимізуючий (по ) критерій методі найменших квадратів.
Перед тим, як виписати необхідні умови екстремуму, перетворимо праву частину (5)
![]() (5)
(5)
В цьому перетворенні ми скористалися правилом транспонування добутку матриць, а також тим, що ![]() - число, яке співпадає зі своїм транспонованим значенням.
- число, яке співпадає зі своїм транспонованим значенням.
Необхідні умови, яким задовольняє розвязок оптимізаційної задачі (1.5), отримуються шляхом диференціювання правої частини (5) по 0 ,1 ,…,p
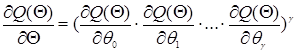 ,
,
![]()
Звідки
![]() (6)
(6)
Основні припущення моделей, побудованих на основі МНК.
Для того, щоб МНК-оцінки були оптимальними, необхідно і достатньо, щоб виконувалися наступні вимоги.
1. Відсутність мультиколінеарності між пояснюючими змінними x1,…,xn, тобто фактори повинні бути незалежними між собою. Іншими словами, не повинно бути точного лінійного звязку між двома або більше факторами. При порушенні цієї вимоги матриця ![]() з рівняння (6) стає виродженою і її не можна обернути.
з рівняння (6) стає виродженою і її не можна обернути.
2. Незміщеність оцінок. Оцінка параметра називається незміщеною, якщо ![]() (для векторного параметра мається на увазі одночасне виконання для всіх компонентів вектора та )
(для векторного параметра мається на увазі одночасне виконання для всіх компонентів вектора та )
3. Коваріаційна матриця дорівнює
![]()
Для досягнення цих вимог повинні виконуватися основні припущення моделі.
1. Випадкова величина і є нормально розподіленою.
2. Математичне сподівання і-го значення (i=1,n) випадкової величини « дорівнює нулеві
![]() .
.
3. Випадкові величини незалежні між собою
![]() .
.
4. Матриця спостережень X нестохастична. тобто вона утворюється з фіксованих елементів.
Оцінювання якості моделей за двома параметрами:
· коефіцієнтом детермінації. В основі оцінювання параметра лежить відношення частини дисперсії, що пояснює регресію та загальною дисперсією
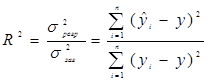 (7)
(7)
Цей коефіцієнт показує ступінь тісноти статистичного звязку між побудованими модельними оцінками та спостережуваними даними.
· t – критерій Стюдента. В основі оцінки лежить припущення про нормальний розподіл випадкової величини з нульовим математичним сподіванням та постійною дисперсією 2
![]() .
.
та, що у випадку 6агатофакторноі регресії кожний параметр також відповідає нормальному законові розподілу
![]() (8)
(8)
з математичним сподіванням яке дорівнює значенню параметра узагальненої регресії та дисперсією, яка дорівнює дисперсії випадкової величини 2, помноженої на відповідний діагональний елемент зворотної матриці. Справжнє значення дисперсії випадком, величини невідоме, тому ми змінюємо його на оцінку дисперсії. Така заміна призволить до того, що кожний елемент вектора (8) відповідатиме вже t-розподілу Стюдента з (n-k) ступенями вільності, що дає змогу обчислити t-статистику для кожного параметра:
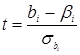
зі ступенями вільності df=(n-k)
Т-розподіл Стюдента дає змогу протестувати гіпотезу щодо значення кожного параметра та побудувати їхні інтервали довіри.
· F-відношення показує ступінь адекватності моделі в цілому
![]()
Обчислений критерій порівнюється з табличним значенням ![]() . При
. При ![]() ., модель вважається адекватною.
., модель вважається адекватною.
Основний і головним недоліком застосування даної методології є порушенім хоча б однієї з умов ефективності МНК-оцінок. Як бачимо, наприклад, при мультиколінеарності неможливо отримати оцінки взагалі. Також немає ніякої гарантії про відсутність автокореляції залишків отриманої моделі.
Другий недоліком даної моделі є обовязкова умова переважання кількості спостережень над кількістю досліджуваних параметрів. При порушенні даної вимоги повністю ламається апарат дослідження якості отриманих моделей, оцінки значимості коефіцієнтів моделі.
Третім вирішальним недоліком є те, що модель не заходиться автоматично, а лише досліджуються висунуті гіпотези про взаємозвязки між змінними. При обмеженому часі на моделювання цей недолік є провідним.
Як побачимо нижче, застосування нечіткого методу групового врахування аргументів уникає дані недоліки.
Моделювання процесів з використанням методів лінійного і нелінійного програмування.
Дану групу методів ще називають методами оптимального планування. 3 цієї назви і випливає їхня суть. Вона полягає в тому, що дослідник (аналітик) намагається досягти максимально корисного за складеним ним критерієм ефективності використання ресурсів при заданих обмеженнях на ці ресурси.
Цільовою функцією, як правило, бувають вимога максимізації або мінімізації. Обмеженнями моделей даного класу є символьне (у вигляді функцій) представлення обмеженості ресурсів.
Критерієм оптимальності розвязку задач даного типу є максимум (мінімум) цільової функції на множині припустимих розв’язків моделі – множині утвореної обмеженнями моделі.
З математичної точки зору, основна ідея, застосування методів даного класу полягає у знаходженні оптимального поєднання ресурсів множинні припустимих планів. В залежності від форми цільової функції та вигляду обмежень методи поділяються на задачі лінійного та нелінійного програмування.
В задачі лінійного програмування цільова функція та обмеження лінійні. Множина допустимих рішень, в такому випадку – це опуклий многогранник. І задача оптимізації зводиться до перебору всіх крайніх точок даного многогранника.
В противному випадку, якщо цільова функція або обмеження набувають нелінійного характеру, для знаходження оптимального розвязку використовується принцип опуклості (увігнутості) задачі нелінійного програмування, яке гарантує досягнення глобального оптимуму на множині припустимих рішень.
Недоліки цього класу моделей очевидні.
1. Необхідність мати достатньо обмежень для утворення множини припустимих рішень. У випадку незадоволення даної вимога множина рішень стає необмеженою і зникає гарантія отримання оптимального рішення. Дуже часто, отримані розвязки не мають економічного обґрунтування.
2. Необхідність мати чітко сформульовану цільову функцію – критерій якості отриманого розвязку. Дуже часто його важко побудувати. До того ж існує небезпека, що побудована функція якості є субєктивною думкою дослідника, що може не відповідати дійсності. Отже, для отримання максимально якісного розвязку необхідно вкласти максимум інформації про досліджуваний обєкт у вигляді обмежень та скласти максимально об’єктивний критерій оцінки ефективності отриманої моделі.
Моделювання процесів і використання методів еволюційного або генетичного пошуку
Еволюційні алгоритми вперше розроблені Джоном Холандом (John Holland) у 1970-х роках, сьогодні частіше називають генетичними алгоритмами, оскільки вони імітують процеси природного відбору.
Генетичні алгоритми набагато рідше, ніж методи, які базуються на обчисленні градієнтів, зупиняється в точці локального оптимуму або осцілюють в околі точок розриву. З іншого боку, вони потребують дуже великої кількості обчислень і не гарантують знаходження глобального оптимуму.
Основні припущення моделей наступні.
Базуючись на біологічних концепціях, генетичний алгоритм помітно відрізняється від інших класів моделей. Наведемо перелік основних властивостей та ідей алгоритму.
1. Алгоритм використовує випадково обрані початкові точки (отже даний метод недетермінований).
2. В той час, коли у більшості методів зберігається лише найкращий розв’язок, знайдений у процесі пошуку, в генетичному алгоритмі зберігається велика кількість проміжних результатів, які називають популяціями можливих розв’язків, не всі з яких є найкращими розв’язками. Дану популяцію використовують для створення нових початкових точок, не обов’язково в околі поточного найкращого розв’язку, що допомагає алгоритму уникати зупинок в локальному оптимумі.
3. По аналогії з генними мутаціями в біології алгоритм час від часу проводить випадкові зміни в одному або декількох членів популяції для створення нових потенційних початкових точок «нащадків», які можуть знаходитись далеко від решти членів даної популяції.
4. Як при статевому способі розмноження, елементи існуючих в популяції розвязків комбінуються одне з одним за допомогою операції, яка нагадує схрещування ланок ДНК, щоб створити новий потенційний розвязок, яке має ознаки кожного з батьківських розвязків.
5. Будь-які порушення обмежень новими рішеннями призводить до віднімання (в моделі максимізації) зі значення цільової функції для даного розвязку, або додавання до нього ( в моделі мінімізації) «штрафу», сума якого відображає ступінь порушення обмеження. Це змінене значення цільової функції стає мірою «придатності» даного рішення.
6. Аналогічно до природного відбору, початкові точки – «нащадки», які не покращують значення цільової функції і не допомагають отримати нові початкові точки, врешті-решт видаляються з популяції як «непридатні».
В генетичному алгоритмі розвязок задачі надано у вигляді геному (або хромосома). Алгоритм працює з популяцією, яка містить десятки. або навіть сотні припустимих розв’язків. З цієї популяції розвязків генетичний алгоритм створює за допомогою мутації та схрещування нові розвязки, щоб отримати набір претендентів на «звання» найкращого розвязку. Спрощено кажучи, в ході схрещування комбінуються дві (батьківські) хромосоми, щоб отримати одну нову хромосому (нащадок). Як і при статевому розмноженні, ідея схрещування полягає втому, що нова хромосома може виявитися краще обох батьківських, якщо взяти кращі характеристики обох кожної з них.
На відміну від схрещування, операція мутації привносить деякий елемент випадковості у нові хромосоми нащадки. Її задача полягає в тому, щоб допомогти програмі знайти такі розв’язки-нащадки, які неможливо отримати шляхом схрещування. Розв’язки-нащадки з низьким значенням виграшу («поганим» значенням цільової функції), зберігаються, оскільки вони можуть породити в наступних поколіннях нащадків з високим виграшем («кращим» значенням цільової функції). Якщо цього не відбувається, ці нащадки врешті-решт видаляються з популяції розв’язків.
Генетичні алгоритми – це алгоритми пошуку. які використовують структурований обмін інформацією (схрещування) і рандомізацію (мутації) для формування процедуру пошуку, які мають властивості природних процесів: в кожному поколінні створюється новий набір розвязків, створений з найбільш придатних екземплярів попереднього покоління. Зазначимо, що генетичний алгоритм не є випадковим переміщенням по простору можливих розвязків Це було б занадто неефективно. Навпаки, даний алгоритм ефективно використовує накопичену інформацію для формування нових розвязків, які як очікуються, покращать виграш. Тому алгоритм іноді називають методом спрямованого випадкового пошуку.
До даного методу відносяться різновиди методів групового врахування аргументів. Як було вже зазначено вище, до основних недоліків даного алгоритму належать.
1. Великий обєм памяті Це повязано з великою кількістю членів популяції на рівні, великою кількістю «епох» – рівнів, а також з потребою зберігати додаткову інформацію про параметри («паспорт») кожного нащадку.
2. Відносно повільна збіжність алгоритму. Хоча даний алгоритм і є спрямованим, часте «вибивання» з наближених до оптимуму точок внаслідок мутацій значно більше займає час пошуку оптимального рішення
3. Алгоритм потребує усталених правил функціонування.
2 Нечіткий метод групового врахування аргументів
2 .1 Метод групового врахування аргументів як основа нечіткого методу
Метод групового врахування аргументів (МГВА) був запропонований наприкінці 60-х —початку 70-х р.р. академіком О.Г. Івахненко (Інститут кібернетики НАН України). Цей метод використовує ідеї самоорганізації і механізми живої природи – схрещування (гібридизацію) і селекцію (добір).
Нехай є вибірка з N спостережень вхідних векторів Х(i) та вихідних Y(і) :
Рис. 3. Задача ідентифікації моделі
За результатами спостережень треба визначити F(х), причому структура моделі F(х) невідома.
Найбільш повна залежність між входами Х(i) і виходами Y(i) може бути представлена за допомогою узагальненого полінома Колмогорова-Габора.
Нехай є вибірка X = {х1,..., хN} , тоді такий поліном має вигляд:
![]() ,
,
де всі коефіцієнти i не відомі.
При побудові моделі (при визначенні значень коефіцієнтів) в якості критерій використовується критерій регулярності (точності):
![]()
Нам треба знайти таку модель, для якої ![]() .
.
Розглянемо основні принципи та ідеї МГВА.
Принцип множинності моделей: існує множина моделей на даній вибірці, що забезпечують нульову помилку (достатньо підвищувати ступінь полінома моделі). Тобто, якщо є N вузлів інтерполяції, то можна побудувати ціле сімейство моделей, кожна з яких при проходженні через експериментальні точки буде давати нульову помилку
Як правило, ступінь нелінійності беруть не вище n–1, якщо n – кількість точок вибірки.
Позначимо S – складність моделі (визначається числом членів полінома Колмогорова-Габора).
Значення помилки ![]() залежить від складності моделі. Причому в міру росту складності спочатку вона буде падати, а потім зростати. Нам же потрібно вибрати таку оптимальну складність, при якій помилка буде мінімальна. Крім того, якщо враховувати дію перешкод, то можна виділити наступні моменти:
залежить від складності моделі. Причому в міру росту складності спочатку вона буде падати, а потім зростати. Нам же потрібно вибрати таку оптимальну складність, при якій помилка буде мінімальна. Крім того, якщо враховувати дію перешкод, то можна виділити наступні моменти:
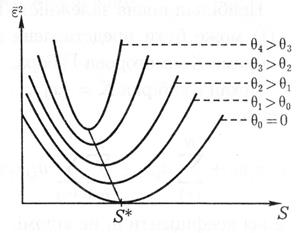
Рис. 4. Залежність помилки від складності моделі
При різному рівні перешкод залежність ![]() від складності S буде змінюватися, зберігаючи при цьому загальну спрямованість (мається на увазі, що з ростом складності вона спочатку буде зменшуватись, а потім – зростати).
від складності S буде змінюватися, зберігаючи при цьому загальну спрямованість (мається на увазі, що з ростом складності вона спочатку буде зменшуватись, а потім – зростати).
При збільшенні рівня перешкод величина ![]() буде зростати.
буде зростати.
З ростом рівня перешкод величина ![]() буде зменшуватись (оптимальне значення складності буде зміщатися вліво). Причому
буде зменшуватись (оптимальне значення складності буде зміщатися вліво). Причому ![]() , якщо рівень перешкод не нульовий (див. рис.4).
, якщо рівень перешкод не нульовий (див. рис.4).
Теорема неповноти Геделя: У будь-якій формальній логічній системі існує ряд тверджень і теорем, які не можна ні спростувати, ні довести, залишаючись у рамках цієї системи аксіом.
У даному випадку ця теорема означає, що вибірка завжди неповна. Один зі способів подолання цієї неповноти – принцип зовнішнього доповнення. В якості зовнішнього доповнення використовується додаткова вибірка (перевірочна), точки якої не використовувалися при навчанні системи (тобто при пошуку оцінок значень коефіцієнтів полінома Колмогорова-Габора).
Пошук найкращої моделі здійснюється в такий спосіб:
1. Уся вибірка поділяється на навчальну і перевірочну:
![]() ;
;
2. На навчальній вибірці ![]() визначаються значення 0, i ,ij;
визначаються значення 0, i ,ij;
3. На перевірочній вибірці ![]() відбираються кращі моделі.
відбираються кращі моделі.
Вхідний вектор має розмірність N (X ={x1,…,xn}).
Принцип свободи вибору (неостаточності проміжного рішення):
1. Для кожної пари xi та xj будуються часткові описи (усього ![]() ) виду:
) виду:
— або ![]() (лінійні);
(лінійні);
— або ![]() (квадратичні).
(квадратичні).
2. Визначаємо коефіцієнти цих моделей по МНК, використовуючи навчальну вибірку. Тобто знаходимо 0, i,…, j ,…, N, 11,…, ij ,…, NN
3. Далі на перевірочній вибірці для кожної з цих моделей знаходимо оцінку
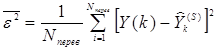
(де ![]() – дійсне вихідне значення в k-тій точці перевірочної вибірки;
– дійсне вихідне значення в k-тій точці перевірочної вибірки; ![]() – вихідне значення в k-тій точці перевірочної вибірки відповідно до S-тієї моделі) і визначаємо F кращих моделей.
– вихідне значення в k-тій точці перевірочної вибірки відповідно до S-тієї моделі) і визначаємо F кращих моделей.
Обрані yi подаються на другий ряд (рис.3).
Шукаємо
![]()
Оцінка тут така ж, як на першому ряді. Добір кращих. здійснюється знову так само, але F2 F1.
Процес конструювання рядів повторюється доти, поки середній квадрат помилки буде падати. Коли на шарі m одержимо збільшення помилки ![]() , то припиняємо.
, то припиняємо.
Якщо часткові описи квадратичні і число рядів полінома S, то одержуємо, що максимальний ступінь полінома k = 2S. На відміну від звичайних методів статистичного аналізу, при такому підході можна одержати досить складну залежність, навіть маючи коротку вибірку.
Існує проблема: на першому ряді можуть відсіятися деякі змінні xi і xj, котрі впливають на вихідні дані.


Рис.5. Структура багаторядного алгоритму МГВА
У звязку з цим запропонована така модифікація: на другому шарі подавати yi і xi,-, тобто:
![]()
Це важливо при високому рівні перешкод, щоб забезпечити незміщеність моделей.
Виникає два критерії добору кращих кандидатів часткових описів, які передаються на певному шарі на наступний ряд (шар).
1. Критерій регулярності (точності) ![]()
а) ;
;
б)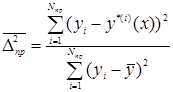 .
.
Критерій незміщеності. Беремо усю вибірку, поділяємо на дві частини R1, R2, де R = R1 + R2:
Перший експеримент:
R1 — навчальна вибірка, R2 — перевірочна;
визначаємо виходи моделі ![]() ;
;
Другий експеримент:
R2 — навчальна вибірка, R1 — перевірочна;
визначаємо виходи моделі ![]() ; і порівнюємо.
; і порівнюємо.
Критерій незміщеності:
![]()
Чим менше nзм, тим більше незміщеною є модель.
Такий критерій визначається для кожного часткового опису першого рівня і потім знаходиться nзм для рівня в цілому для F кращих моделей
![]() .
.
У ряді варіантів F = 1. Аналогічно на другому шарі обчислюємо ![]() .
.
І процес селекції здійснюється доти, поки цей критерій не перестане зменшуватися, тобто до досягнення умови
![]() .
.
До переваг методу МГВА можна віднести наступі властивості.
1. Можна відновити невідому довільно складну залежність по обмеженій вибірці. Число невідомих параметрів моделі може бути більше, ніж число точок навчальної послідовності.
2. Можливість адаптації параметрів моделі при одержанні нових даних експериментів (зокрема використовуючи РМНК).
2 .2 Суть нечіткого методу групового врахування аргументів
Побудова систем самоорганізації по методу групового обліку аргументів (МГВА) базується на наступних принципах.
1. Принцип самоорганізації моделі. При послідовному збільшенні складності структури моделі значення зовнішніх критеріїв спочатку зменшуються, досягають мінімуму, а потім залишаються незмінними чи починають збільшуватися. Перше найменше значення комбінації критеріїв визначає єдину модель оптимальної складності.
2. Принцип зовнішнього доповнення. Задачі інтерполяції відносяться до некоректно поставлених задач, що мають багатозначне рішення. Для однозначного їхнього рішення необхідне завдання адекватного зовнішнього доповнення – зовнішнього критерію оптимальності. Під зовнішнім критерієм будемо розуміти критерій, що обчислюється з використанням інформації, не використаної при оцінці параметрів. Внутрішні доповнення, тобто критерії, що не використовують ніякої додаткової інформації, при дії перешкод не можуть вирішити задачу вибору моделі оптимальної складності.
3. Гьоделівський підхід при самоорганізації моделей. Теорема стверджує, що для будь-якої системи вихідних аксіом (зовнішніх доповнень першого рівня) завжди можна задати таку теорему, для доказу якої недостатньо даної системи аксіом і необхідні нові аксіоми – зовнішні доповнення. Стосовно до моделей самоорганізації ідеї Гьоделя можна інтерпретувати в такий спосіб: по мінімуму заданого зовнішнього критерію можна вирішити всі питання про вибір опорних функцій, структури і параметрів моделі, крім питань, звязаних з алгоритмом обчислення і способами використання самих критеріїв.
4. Зовнішні критерії селекції моделей. Рівняння регресії вибирається за критерієм мінімуму незміщеності – несуперечності, відповідно до якого потрібно, щоб моделі, побудовані по частині таблиці A, якнайменше відхилялися від моделей, побудованих по частині B. Критерій мінімуму незміщеності є базовим, тому що несуперечність моделей є обовязковою властивістю оптимальної моделі.
5. Розбивка таблиці даних на частини. Основний критерій мінімуму незміщеності вимагає розбивки таблиці даних на дві рівні частини A та B. Звичайно таблиця вихідних даних поділяється на три частини: навчальна A, перевірочна B і екзаменаційна вибірка C. Навчальна вибірка використовується для одержання оцінок параметрів моделі (наприклад, коефіцієнтів регресії), а перевірочна – для вибору структури моделі.
6. Гіпотеза селекції. При використанні принципу селекції в кібернетиці необхідно дотримуватися наступних правил:
· для кожного покоління (чи ряду селекції моделі) існує деяка мінімальна кількість комбінацій, які відбираються. Вони називаються свободою вибору і забезпечують збіжність багаторядних селекцій моделі оптимальної складності;
· занадто велика кількість поколінь приводить до індуциту (інформаційна матриця стає погано обумовленою);
· чим складніше задача селекції, тим більше потрібно поколінь для одержання моделі оптимальної складності.
7. Принцип збереження свободи вибору. Свобода вибору забезпечується тим, що на кожний наступний ряд селекції передається не одне рішення, а декілька кращих, відібраних на останньому ряді. Д. Габор сформулював цей принцип таким чином: приймати рішення в даний момент часу необхідно таким чином, щоб у наступний момент часу, коли виникне необхідність у черговому рішенні, зберігалася б свобода вибору рішень.
8. Застосування евристичних методів. Евристичний характер самоорганізації моделей особливо виявляється при виборі опорної функції окремих моделей, критеріїв селекції моделей, способу регуляризації, способу нормування перемінних, конкретній реалізації послідовного збільшення складності моделей-претендентів.
9. Одночасне моделювання на різних рівнях спільності мови математичного опису обєктів. Основним моментом у цьому принципі є використання багаторівневого моделювання для рішення задачі прогнозування.
Самоорганізація відноситься до емпіричних методів моделювання. Ці методи у своїй області застосування мають деякі переваги в порівнянні з теоретичними і напівемпіричними методами побудови моделей. У тих випадках, коли ми спостерігаємо параметри досліджуваного обєкта, але не знаємо структури і механізму взаємодії між елементами складної системи, поводження якого визначає значення параметрів, підхід самоорганізації виявляється єдиним надійним засобом побудови моделей прогнозу. За допомогою самоорганізації рішення можна визначити, навіть якщо іншими способами одержати результати неможливо. Моделі, отримані за допомогою самоорганізації, мають специфічну область застосування й особливо ефективні для короткострокового прогнозу. Фізичні моделі, отримані на основі математичної теорії обєктів, які спостерігаються, можуть мати тільки цілком визначені пізнавальні цілі (ідентифікація і довгостроковий прогноз). Тому побудова моделей відповідно до нових обєктивних методів самоорганізації уможливлює замість допущень і грубих помилок запропонувати моделі, що ґрунтуються на надійній інформації й отримані за допомогою самоорганізації.
Висновки
Узагальнюючи, можна сформулювати наступні роботи, які було проведено:
· розглянуто проблему моделювання технологічного процесу і прогнозування його параметрів;
· проаналізовано сучасні методи отримання математичних моделей та вибрати ефективні для розв’язання задач прогнозування;
· обґрунтовано доцільність використання нечіткого методу групового врахування аргументів для моделювання та прогнозування технологічних параметрів;
· розроблено алгоритм моделювання за допомогою нечіткого методу групового врахування аргументів;
· виконано програмну реалізацію алгоритму нечіткого методу групового врахування аргументів;
· здійснено порівняльний аналіз чіткого і нечіткого методу групового врахування аргументів;
· виконано апробацію розроблених алгоритмів і програм нечіткого методу групового врахування аргументів при моделюванні і прогнозуванні технологічних параметрів процесу обробки деталей різанням;
· проведено аналіз отриманих результатів і надати відповідні рішення щодо використання нечіткого методу групового врахування аргументів.
Література
1. Советов Б.Я. Яковлев С.А. Моделирование систем: Учеб. для вузов – 3-е изд., перераб. и доп. – М.: Высш. шк., 2001. – 343 с.: ил.
2. Габисония В.Е, Харчев В.Н. Математические аспекты автоматизированного проектирования АН ГССР. Ин-т систем управления. – Тбилиси: Мецниереба, 1988. -110 с.
3. Гроп Д. Методы идентификации систем /Пер. с пнгл. –М.: Мир,1979. – 302 с.
4. Єлейко В.І. Економіко-статистичні методи моделювання і прогнозування: Посібник для студ. екон. спец. – К.:, 1988. – 88 с.
5. Ермаков С.М., Михайлов Г.А. Курс статистического моделирования. Уч. пособие для студ. – М.: Наука, 1976. – 319 с.
6. Лопушенко В.В., Юревич Р.В. Типові математичні моделі в САПР ТП. Навчальний посібник/Львівський політехнічний інститут. – К.:, 1993, -52 с.
7. Математические методы и модели в САПР. Межвуз. сб. научн. тр. -Самара: Самар. авиац. ин-т, 1991. -145 с.
8. Малышев Н.Г. и др. Нечеткие модели для экспертных систем в САПР. – М.: Энергоиздат, 1991. –134 с.
9. Пухов Г.Е., Хатиашвили Ц.С. Модели технологических процессов. – К.: Техніка, 1974. –224 с.
10.Пухов Г.Е., Хатиашвили Ц.С. Критерии и методы идентификации объектов. –К.: Наукова думка, 1979. – 190 с.
11.Рыжов Э.В., Горленко О.А. Математические методы в технологических исследованиях. – К.: Наукова думка, 1990. –183 с.
12.САПР. Общие принципы разработки математических моделей объектов проектирования: Методические рекомендации. – М.: ВНИИИНМАШ, 1980. -190 с.
13.САПР. Общие принципы разработки математических моделей объектов проектирования: Методические рекомендации. – М.: ВНИИИНМАШ, 1980. -120 с.
14.Статистические методы для ЭВМ Под ред. К. Энслейна, Э. Рэлстона, Г.С. Уилфа. – М.: Наука, 1986.
15.САПР. Общие принципы разработки математических моделей объектов проектирования в машиностроении. Нормативный материал МПК по ВТ: НМ МПК по ВТ 102-86. – М.: Изд-во стандартов, 1986. -20 с.
16.САПР. Типовые математические модели объектов проектирования в машиностроении: Метод. указания. РД 50-464-84. – М.: Изд-во стандартов, 1985. -202 с.
17.Смит Джон М. Математическое и цифровое моделирование для инженеров и исследователей. – М.: Машиностроение, 1980. –271 с.
18.Скурихин В.И. и др. Математическое моделирование. – К.: Техніка, 1983. -270 с.
19.Старостин В.Г., Лелюхин В.Е. Формализация проектирования процессов обработки резанием. – М.: Машиностроение, 1986. – 133 с.
20.Цыпкин Я.З. Основы информационной теории идентификации. – М.: Наука, 1984. – 320 с.
21.Зайченко Ю.П. Основи проектування інтелектуальних систем. Навчальний посібник . – К.: Видавничий дім «Слово», 2004. – 352 с.
22.Митрофанов С.П., Куликов Д.Д., Миляев О.Н., Падун Б.С. Технологическая подготовка гибких производственных систем. /Под общ. ред. С.П. Митрофанова. – Л.: Машиностроение. Ленингр. отделение, 1987. – 352 с.
23.Душинський В.В., С.Г. Кравченко. Моделювання й оптимізація в машинобудуванні.: Навч. Посібник – К.: НМК ВО, – 304 с. – Рос. мовою.
24.Радченко С.Г. Математичне моделювання та оптимізація технологічних систем: Навч.-метод. посіб. – К.: ІВЦ «Політехніка», 2001. – 88с. : іл..
25.Ивахненко А.Г. Моделирование сложных систем: (информационный подход). – К.: Вища шк. Головне изд-во, 1987. 63 с.
26.Справочник по типовым программам моделирования. /Ивахненко А.Г., Копа Ю.В., Степашко В.С. и др.; Под ред. А.Г. Ивахненко. – К.: Техника, 1980. – 184 с., ил. – Библиогр.: с 179 – 180.
27.Ивахненко А.Г. Долгосрочное прогнозирование и управление сложными системами. – К.: Техника, 1975. – 312 с.
28. Зайченко Ю.П. Нечеткий метод индуктивного моделирования в задачах прогнозирования макроэкономических показателей. – Системні дослідження та інформаційні технології. 2003. №3.