Организация прерываний и прямого доступа к памяти в вычислительных системах, распределение ресурсов, технология Plug and Play
СОДЕРЖАНИЕ: Принципы организации и особенности обработки прерываний на основе контроллера 8259A. Общая характеристика аппаратных средств системы прерываний PIC (Programmable Interrupt Controller). История разработки и порядок работы с технологией Plag and Play.Министерство образования и науки РФ
Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования
Иркутский государственный технический университет
Курсовая работа
по Организации ЭВМ
«Организация прерываний и прямого доступа к памяти в вычислительных системах, распределение ресурсов, технология Plug and Play»
Выполнил: студент группы
Проверил: преподаватель
Иркутск 2010г.
Содержание
1. Прерывания и исключения
2. Основные принципы организации системы прерываний
3. Аппаратные средства системы прерываний Системный контроллер PIC (Programmable Interrupt Controller)
4. Обработка прерываний на основе контроллера 8259A
5. Контроллер прерываний APIC (Advanced Programmable Interrupt Controller)
6. Режим прямого доступа к памяти
7. Распределение ресурсов, технология Plug and Play
Список литературы
1. Прерывания и исключения
Чтобы обработать запросы от внешних устройств, сообщить об ошибках или исключительных обстоятельствах необходимо прервать выполнение текущей программы и осуществить некоторые необходимые в данной ситуации действия.. Чем отличаются прерывания и исключения. Различия между прерываниями и исключениями состоят в том, что прерывания предназначены для обработки запросов от внешних устройств, а исключения для обработки ошибок, возникающих при выполнении команд. Программные прерывания также относятся к исключениям. С помощью команды INT n ( где n - номер прерывания) можно выполнить прерывание с любым номером в диапазоне от 0 до 255. Номера 0...31 зарезервированы фирмой Intel для исключений. Прерывания, произведенные оборудованием, выполняются после выполнения текущей команды и происходят в результате каких-то внешних асинхронных (не связанных с текущим процессом) событий, нажатие клавиши, например. После того, как программа обработки прерываний заканчивает обслуживание прерывания, выполнение прерванной программы продолжается с команды, которая следует сразу за командой, после которой произошло прерывание. Исключения классифицируются как ошибки, ловушки или прекращения (преждевременное прекращение выполнения программы).
Источниками исключений являются три типа событий:
генерируемые программой исключения, позволяющие программе контролировать определенные условия в заданных точках программы (INT0 - проверка на переполнение, INT3 - контрольная точка, BOUND - проверка границ массива);
исключения машинного контроля, возникающие в процессе контроля операций внутри чипа и транзакций на шине процессора (справедливо для процессора Pentium 4);
обнаруженные процессором ошибки в программе (деление на ноль, нарушение правил защиты, отсутствие страницы и т.п.)
Ошибки - это исключения, которые обнаруживаются и выполняются до выполнения команды содержащей ошибку. Например, ошибка возникает в системе виртуальной памяти, когда процессор ссылается на страницу или сегмент, которые отсутствуют в оперативной памяти. Операционная система выберет страницу или сегмент с диска и разместит его в оперативной памяти, после чего процессор выполнит команду. Ловушки- это исключения, о которых сообщается немедленно после выполнения той команды, которая вызывает исключение (произведенное действие уже не исправить). Прекращения - это исключения, которые не позволяют определить точно команду, вызвавшую исключение. Прекращения используются для сообщения о грубых ошибках, таких как аппаратная ошибка, неправильные значения в системных таблицах. В остальных случаях адрес возврата в текущую программу из программы, обрабатывающей исключение всегда укажет на команду, которая вызвала исключение. Все возможные прерывания сводятся в специальную таблицу ( до 256 различных прерываний и исключений). В таблице каждому прерыванию или исключению сопоставляется вектор прерывания- это указатель на соответствующую программу обслуживания (вектор позволяет найти адрес программы, обрабатывающей прерывание).
Программные прерывания
Команда INT n в выполняемой программе заставляет процессор выполнять программу обслуживания, на которую указывает вектор n в таблице прерываний. Современные программы оперируют с преобразованными адресами памяти и программы прерывания служат обычно единственным средством для выхода из программы в операционную систему. Программные прерывания могут использоваться для доступа к сервисам операционной системы (например, INT $21 - сервисы DOS, INT $80 - сервисы Linux), функциям драйверов устройств (например, INT $33 - драйвер мыши) или специальным сервисам (INT $10 - видео-сервис BIOS, INT $31 - DPMI-сервис), INT $67 - сервис EMS). Особым случаем программного прерывания INT с номером n является прерывание INT 3, или прерывание останова. Путем ввода данной команды в программу, пользователь имеет возможность устанавливать точки останова, как инструмент отладки программы. Еще один тип программного прерывания, применяемого при отладке, - прерывание пошагового режима.
Маскируемые прерывания
Маскируемые прерывания - наиболее общий способ ответа на асинхронные внешние сигналы от аппаратуры. Такое прерывание может быть разрешено или запрещено. Аппаратное прерывание разрешено тогда, когда бит флага прерываний разблокирован (установлен в 1). Процессор обслуживает разрешенное маскируемое прерывание только после выполнения текущей команды. Он читает вектор прерывания, аппаратно установленный на шине данных, и определяет адрес программы обработки прерывания. Бит флага прерывания в регистре флагов (регистре состояния) может сбрасываться, когда обслуживается прерывание. Это позволяет предотвратить дополнительное прерывание во время обслуживания первого прерывания. Если флаг прерывания установлен, возможно прерывание программы обработки текущего прерывания и обработка другого прерывания, т.е. разрешается обработка вложенных прерываний.
Приоритетность прерываний
Поскольку прерывания распознаются только после выполнения текущей команды, запросить прерывание может более чем один источник прерывания. В этом случае прерывания будут обслуживаться согласно (уровню) приоритету. Например, пусть заданная команда вызывает системное прерывание отладки и исключение сегмент отсутствует. Процессор сначала отреагирует на исключение сегмент отсутствует (11), при этом активизируется программа обработки исключения 11. Затем программа обработки исключения 11 будет прервана программой обработки прерывания отладки, после отладки управление снова будет передано обработчику исключения 11. Использование приоритетов прерываний позволяет системотехнику отлаживать свои собственные обработчики исключений.
Немаскируемые прерывания (NMI — Non-Maskable Interrrupt)
Немаскируемые прерывания обеспечивают обслуживание прерываний очень высокого уровня. Одним из распространенных примеров немаскируемых (NMI ) прерываний может служить прерывание по сбою питания. Во время процедуры обслуживания немаскируемых прерываний процессор не будет обслуживать другие прерывания ( запрос NMI или INT), до тех пор, пока не будет выполнена команда возврата из прерывания (IRET). Флаг блокировки прерываний устанавливается в начале выполнения немаскируемого прерывания. Если другое немаскируемое прерывание (NMI) произойдет во время обслуживания немаскируемого прерывания, запрос будет сохранен для его обработки после первой команды возврата из программы обработки текущего немаскируемого прерывания.
Обработка прерываний
Когда происходит прерывание, происходят следующие действия. Во-первых, адрес текущей команды и регистр флагов сохраняются в стеке, что позволяет возобновить прерванную программу. Затем, по вектору, который определяет соответствующий элемент в таблице прерываний определяется начальный адрес программы обработки прерывания. Выполняется программа обработки. И наконец, после команды возврата из программы обработки прерывания (IRET) восстанавливается прежнее состояние процессора и по адресу возврата (по адресу сохраненному в стеке) возобновляется выполнение программы.
2. Основные принципы организации системы прерываний
Можно выделить следующие классы прерываний:
Внутрипроцессорные прерывания, вызванные событиями, происходящими в самом процессоре.
Внутрисистемные прерывания, определяемые событиями в системных устройствах компьютера.
Прерывания в выполняемой программе, возникающие при обращении к системе BIOS.
Межпроцессорные прерывания в мультипроцессорных системах, когда один процессор прерывает работу другого, организуя обработку программы прерывания.
Реализация режима прерывания включает следующие шаги:
Идентификация источника прерывания;
Сохранение текущего состояния прерываемой программы;
Запрещение повторных прерываний от установленного источника прерывания;
Выполнение программы обработки прерывания;
Восстановление состояния прерванной программы и продолжение вычислений.
Для взаимодействия программ с устройствами предусматривается несколько способов:
при помощи вызовов функций операционной системы (прерывания DOS, API Windows и т. п.);
при помощи вызовов функций базовой системы ввода-вывода (BIOS);
непосредственно взаимодействуя с портами и памятью внешних устройств или контроллеров интерфейсов этих устройств.
Обычный одноядерный процессор может выполнять только один процесс, передавая управление от инструкции к инструкции согласно исполняемой программе. При этом могут исполняться переходы, ветвления и вызовы процедур, но вся последовательность действий запрограммирована разработчиком программы.
Теперь рассмотрим случай, когда во время этого процесса случается асинхронное (не связанное с выполняемым процессом)событие, требующее реакции компьютера. Рассмотрим нажатие клавиши на клавиатуре. Клавиатура по нажатию (и по отпусканию) любой клавиши генерирует специальную посылку, содержащую код этого события (скан-код клавиши). Контроллер клавиатуры, находящийся на системной плате, принимает этот код в свой внутренний регистр и сигнализирует об этом двумя способами: устанавливает флаг готовности (бит в регистре состояния, который может быть прочитан процессором по адресу определенного порта ввода) и генерирует сигнал запроса прерывания (сигнал IRQ1). Этот сигнал поступает на вход контроллера прерываний. Контроллер прерываний формирует сигнал запроса, поступающий на вход маскируемого прерывания процессора. Если у процессора маскируемые прерывания разрешены, то он запросит у контроллера номер вектора прерывания, соответствующего данному источнику прерывания. Сигнал от клавиатуры соответствует вектору 9. Получив значение вектора, процессор сохранит в стеке адрес следующей инструкции исполняемого процесса и выполнит вызов процедуры обработки прерывания, адрес которой задан в 9-м элементе таблицы векторов прерываний. Вызванная процедура считает скан-код из контроллера клавиатуры (в ответ он сбросит бит готовности в своем регистре состояния), выполнит необходимые действия, связанные с получением этого кода. Процедура обработки прерывания завершается специальной инструкцией возврата, по которой управление вернется прерванному процессу.
Прерывания используют и для переключения задач в многозадачных системах. Пусть, например, имеются два процесса ( две прикладные программы), которые должны выполняться как бы одновременно (по-настоящему одновременно один фон-неймановский процессор их выполнить не может). Можно запустить один процесс, а через некоторое время его работы по аппаратному прерыванию (от таймера) сохранить в памяти текущее состояние процесса (все регистры, программно-доступные этому процессу) и запустить другой процесс. Через некоторое время по следующему прерыванию выполнить обратное переключение: сохранить состояние второго процесса (в другом месте памяти), загрузить в регистры процессора состояние первого процесса и продолжить его выполнение. Эти переключения задач следует выполнять в течение исполнения обоих программ с частотой, создающей у пользователя иллюзию одновременности. Понятно, что ресурсы процессора (производительность) в этом случае делятся между задачами, пропорционально выделяемым им квантам времени. Чтобы пользователя такая производительность процессов удовлетворяла (а еще учтем расходы времени на сохранение и восстановление процессов при переключениях), у процессора должна быть достаточная мощность.
Для того, чтобы процессы не мешали друг другу (по недосмотру или умышленно), требуются меры принудительной защиты критических ресурсов. Современные операционные системы используют защищенный режим процессора, в котором эти меры реализуются на аппаратном уровне. Поскольку программа может взаимодействовать с подсистемами компьютера только через пространства памяти и портов ввода-вывода, а также аппаратные прерывания, то защищать нужно эти три типа ресурсов. Самую сложную защиту имеет память. Операционная система выделяет каждому процессу области памяти — сегменты — различного назначения и с разными правами доступа. Из одних сегментов можно только читать данные, в другие возможна и запись. Для программного кода выделяются специальные сегменты, инструкции могут выбираться и исполняться только из них.
Переключение задач производится по сигналу прерывания от таймера для процессов, работающих псевдопараллельно. Поэтому программисту, разрабатывающему прикладную программу, в большинстве случаев не надо заботиться о многозадачной работе. В распоряжение его программы предоставляется виртуальная машина (тоже фон-неймановская), которая выполняет единственный процесс. Конечно, поддержка виртуальных машин требует определенных усилий со стороны многозадачной операционной системы, которой приходится распределять не только процессорное время, но и память, устройства хранения, ввода-вывода и коммуникационные — то есть все ресурсы реального компьютера. В этом ей помогают специальные средства, введенные в процессоры x86 2–3-го поколений и постоянно развиваемые в старших поколениях. Кроме того современные процессоры имеют специальные интерфейсные средства для построения многопроцессорных систем. Интерфейс позволяет объединять в систему до 4-х процессоров, при этом почти все их одноименные выводы объединяются. Целью объединения является либо использование симметричной мультипроцессорной обработки SMP (Symmetric Multi-Processing), либо построение функционально-избыточных систем FRC (Functional Redundancy Checking).
3. Аппаратные средства системы прерываний Системный контроллер PIC (Programmable Interrupt Controller)
Рассмотрим, как организована система прерываний в IBM-совместимых персональных компьютерах. Современный процессор предназначен для работы в многопроцессорных системах и организация прерываний претерпела некоторые изменения. Если ранее для организации прерываний применялся только системный контроллер PIC (Programmable Interrupt Controller), то начиная с процессора Pentium каждый современный процессор имеет встроенный контроллер APIC (Advanced Programmable Interrupt Controller) для выполнения ряда новых функций и поддержки ранее введенной системы прерываний. Часть контроллера APIC - I/O APIC встраивается в чипсет, обеспечивающий работу процессора в вычислительной системе и, кроме дополнительных функций, выполняющий функции контроллера PIC, поддерживая аппаратную совместимость с прежними вычислительными системами. Чтобы понять, как работает современная система прерываний, познакомимся с обработкой прерываний на основе контроллера 8259А.
4. Обработка прерываний на основе контроллера 8259A
Программируемый контроллер прерываний PIC 8259A представляет собой устройство, реализующее до восьми уровней запросов на прерывания с возможностью программного маскирования и изменения порядка обслуживания прерываний. За счет каскадного включения число уровней прерывания может быть расширено до 64. Установка контроллера в исходное состояние и настройка его на определенный режим обслуживания прерываний происходит с помощью двух типов команд: команд инициализации (ICW) и команд управления операциями (OCW). На рисунке 1 показана структурная схема контроллера прерываний. Контроллер прерываний включает следующие блоки:
RGI - регистр запросов прерываний IRQx.
PRB - схема принятия решений по приоритетам; схема идентифицирует приоритет запросов и выбирает запрос с наивысшим приоритетом.
ISR - регистр обслуживаемых прерываний; сохраняет запросы прерываний, находящиеся на обслуживании контроллера прерываний.
RGM - регистр маскирования прерываний; обеспечивает запрещение одной или нескольких линий запросов прерывания.
BD - буфер данных; предназначен для сопряжения с системной шиной данных.
RWCU - блок управления записью/чтением; принимает управляющие сигналы от микропроцессора и задает режим функционирования контроллера прерываний.
CMP - схема каскадного буфера-компаратора; используется для включения в систему нескольких контроллеров.
CU - схема управления; вырабатывает сигналы прерывания и формирует трехбайтовую команду CALL для выдачи на шину данных.
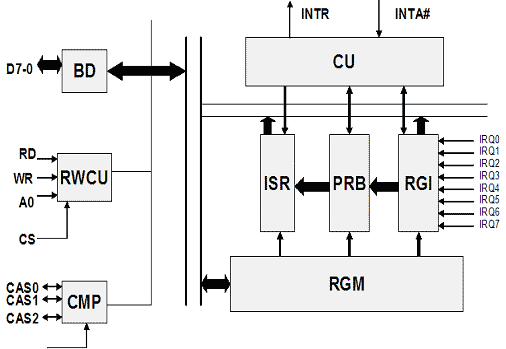
Рис.1. Структура контроллера прерываний 8259А
И так, один контроллер 8259A способен обслуживать прерывания от 8 источников и этого было достаточно для компьютеров IBM PC ХT. В системах IBM PC AT применяется каскадное соединение двух контроллеров (рис.2), один из которых является ведущим, другой — ведомым. Ведущий контроллер 8259A#1( master) обслуживает запросы 0, 1, 3–7; его выход подключается к входу запроса прерываний процессора. К входу 2 контроллера 8259A#1 подключен ведомый контроллер 8259A#2 (slave), который обслуживает запросы 8–15. При этом поддерживается вложенность приоритетов — запросы 8–15 со своим рядом убывающих приоритетов вклиниваются между запросами 1 и 3 ведущего контроллера, приоритеты запросов которого также убывают с ростом номера. В качестве примера отметим, что к линии IRQ 0 подключен системный таймер, к линии IRQ 1 - клавиатура, к линии IRQ 8 - часы реального времени и т.д. Такое каскадное подключение позволяет 15-ти устройствам посылать запрос на обслуживание (прерывание текущей программы).
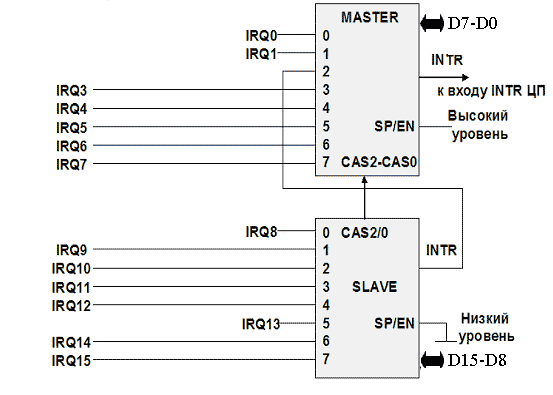
Рис. 2. Каскадное включение контроллеров прерываний
На современных системных платах функции контроллеров прерываний возлагаются на чипсет, который может иметь и более гибкие возможности управления, чем пара контроллеров 8259A. Процедура инициализации контроллеров может отличаться от традиционной, ею занимается тест POST, который учитывает особенности системной платы. Однако при выполнении операций, связанных с реализацией режима прерывания всегда сохраняется программная совместимость с 8259A. Поскольку в каждый момент времени может поступить более чем один запрос на прерывание, контроллер прерываний имеет схему приоритетов. В основном режиме - режиме полного вложения, - до тех пор, пока установлен разряд в регистре ISR, соответствующий запрашиваемому прерыванию, все последующие запросы с таким же или более низким приоритетом игнорируются, подтверждаются лишь запросы с более высоким приоритетом.
В циклическом режиме используется круговой порядок использования приоритетов. Последнему обслуженному запросу присваивается низший приоритет, следующему по кругу - наивысший, что гарантирует обслуживание остальных устройств до очередного обслуживания данного устройства.
Контроллер допускает маскирование отдельных запросов прерываний, что позволяет устройствам с более низким приоритетом получить возможность генерировать прерывания. Режим специального маскирования разрешает прерывания всех уровней, кроме уровней, обслуживаемых в данный момент.
Кроме того, для каскадного включения возможен специальный режим полного вложения. Этот режим программируется при инициализации контроллера. В данном режиме игнорируются запросы с приоритетом более низким, чем приоритет обрабатываемого в данный момент запроса, и обслуживаются все запросы с равным или более высоким приоритетом.
Взаимодействие контроллера прерываний с внешним устройством осуществляется по следующей схеме. Пусть в некоторый момент времени контроллер клавиатуры с помощью единичного сигнала по линии IRQ 1 известил контроллер прерываний о своей готовности к обмену. В ответ на запрос контроллер прерываний генерирует сигнал INTR (запрос на прерывание) и посылает его на соответствующий вход процессора. Процессор, если маскируемые прерывания разрешены (т.е. установлен флаг прерываний IF в регистре флагов процессора), посылает на контроллер шины сигналы R# - чтение, C# - управление и IO# - ввод/вывод, определяющие тип цикла шины. Контроллер шины, в свою очередь, генерирует два сигнала подтверждения прерывания INTA# и направляет их на контроллер прерываний. По второму импульсу контроллер прерываний выставляет на шину данных восьмибитный номер вектора прерывания, соответствующий данной линии IRQ.
В режиме реального адреса (реальном режиме) векторы прерываний хранятся в таблице векторов прерываний, которая находится в первом килобайте оперативной памяти. Под каждый вектор отведено 4 байта (2 байта под адрес сегмента и 2 байта под смещение), т.е. в таблице может содержаться 256 векторов.
Далее процессор считывает номер вектора прерывания. Сохраняет в стеке содержимое регистра флагов, сбрасывает флаг прерываний IF и помещает в стек адрес возврата в прерванную программу (регистры CS и IP). После этого процессор извлекает из таблицы векторов прерываний адрес подпрограммы обработки прерываний для данного устройства и приступает к ее выполнению.
Процедура обработки аппаратного прерывания должна завершаться командой конца прерывания EOI (End of Interruption), посылаемой контроллеру прерываний. Для этого необходимо записать байт 20h в порт 20h (для первого контроллера) и в порт A0h (для второго).
В IBM PC/AT используется режим прерываний с фиксированными приоритетами. Как мы уже отмечали, высшим приоритетом обладает запрос по линии IRQ0, низшим - IRQ7. Так как второй контроллер подключен к линии IRQ2 первого контроллера, то приоритеты линий IRQ в порядке убывания приоритета располагаются следующим образом: IRQ0, IRQ1, IRQ8 - IRQ15, IRQ3 - IRQ7. Если запрос на обслуживание посылают одновременно два устройства с разными приоритетами, то контроллер обслуживает запрос с большим приоритетом, а запрос с меньшим приоритетом блокирует. Блокировка сохраняется до получения команды EOI. В таблице 1. приведены источники прерываний, соответствующие им линии запроса, расположенные по убыванию приоритета - P, вектор1 - значение вектора в таблице векторов реального режима (реального адреса), вектор2 - значение вектора, который использует операционная система (в защищенном режиме).
Таблица прерываний защищённого режима называется дескрипторной таблицей прерываний IDT (Interrupt Descriptor Table).
Таблица 1. Источники аппаратных прерываний в IBM PC AT
| Запрос | Источник | P | вектор1 | вектор2 |
| NMI | Ошибка памяти или другая неисправимая ошибка в системе | 02h | ||
| IRQ0 | Системный таймер | 1 | 08h | 50h |
| IRQ1 | Клавиатура | 2 | 09h | 51h |
| IRQ8 | Часы реального времени | 3 | 70h | 58h |
| IRQ9 | Устройство на системной шине | 4 | 71h | 59h |
| IRQ10 | Устройство на системной шине | 5 | 72h | 5Ah |
| IRQ11 | Устройство на системной шине | 6 | 73h | 5Bh |
| IRQ12 | Устройство на системной шине | 7 | 74h | 5Ch |
| IRQ13 | Ошибка сопроцессора | 9 | 75h | 5Dh |
| IRQ14 | IDE контроллер | 9 | 76h | 5Eh |
| IRQ15 | Устройство на системной шине | 10 | 77h | 5Fh |
| IRQ3 | Последовательный порт (COM2 или COM4) | 11 | 0Bh | 52h |
| IRQ4 | Последовательный порт (COM1 или COM3) | 12 | 0Ch | 53h |
| IRQ5 | Параллельный порт (LPT2) или IDE контроллер (вторичный) | 13 | 0Dh | 54h |
| IRQ6 | Контроллер дисковода | 14 | 0Eh | 55h |
| IRQ7 | Параллельный порт (LPT1) | 15 | 0Fh | 56h |
Дескрипторная таблица прерываний IDT (Interrupt Descriptor Table) располагается по адресу, который заносится в 5-байтовый внутренний регистр процессора IDTR. Регистр IDTR содержит 24-битовый физический адрес дескрипторной таблицы прерываний IDT и её предел.
Для обработки особых ситуаций - исключений был зарезервирован 31 номер прерывания. В таблице 2 приведён полный список зарезервированных прерываний защищённого режима.
Таблица 2. Зарезервированные прерывания защищённого режима.
| 00h | Ошибка при выполнении команды деления. |
| 01h | Прерывание для пошаговой работы, используется отладчиками. |
| 02h | Немаскируемое прерывание. |
| 03h | Прерывание по точке останова для отладчиков. |
| 04h | Переполнение, генерируется командой INTO, если установлен флаг переполнения OF. |
| 05h | Генерируется при выполнении машинной команды BOUND, если проверяемое значение вышло за пределы заданного диапазона. |
| 06h | Недействительный код операции, или длина команды больше 10 байт. |
| 07h | Отсутствие арифметического сопроцессора. |
| 08h | Двойная ошибка, вырабатывается в том случае, если при обработке исключения возникло ещё одно исключение. Если во время обработки этого прерывания возникает третье исключение, процессор переходит в состояние отключения, что приводит к перезапуску процессора. |
| 09h | Превышение сегмента арифметическим сопроцессором. |
| 0Ah | Недействительный сегмент состояния задачи TSS. |
| 0Bh | Отсутствие сегмента. Вырабатывается при попытке использовать для адресации дескриптор, у которого бит присутствия сегмента в памяти P сброшен в 0. Это прерывание используется для реализации механизма виртуальной памяти. В этом случае по прерыванию 0Bh операционная система может выполнить подкачку отсутствующего сегмента в память. |
| 0Ch | Исключение при работе со стеком. Может возникать в случае отсутствия сегмента стека в памяти или в случае переполнения (антипереполнения) стека. |
| 0Dh | Исключение по защите памяти. Возникает при любых попытках получения доступа к сегментам памяти, если программа обладает недостаточным уровнем привилегий. |
| 0Eh | Отказ страницы для процессоров i80386 или i80486, зарезервировано для i80286. |
| 0Fh | Зарезервировано. |
| 10h | Исключение сопроцессора. |
| 11h - 1Ah | Зарезервированы. |
Перед тем, как передать управление обработчику исключения, процессор для некоторых исключений помещает в стек 16-битовый код ошибки. Код ошибки программа анализирует и получает дополнительную информацию об ошибке. Коды ошибок включаются в стек не только для следующих исключений:
08h - двойная ошибка;
0Ah - недействительный сегмент состояния задачи TSS;
0Bh - отсутствие сегмента в памяти;
0Ch - исключение при работе со стеком;
0Dh - исключение по защите памяти.
Заметим, что аналога коду ошибки для зарезервированных прерываний в реальном режиме нет. Рассмотрим следующий пример: Пусть в нашей системе реализована виртуальная память. Программа в некоторый момент времени обратилась к отсутствующему в оперативной памяти сегменту, выполняя какую-либо команду, например MOV или ADD. Возникло исключение 0Bh - отсутствие сегмента в памяти. Обработчик этого исключения, входящий в состав операционной системы поместил соответствующий сегмент в оперативную память. Затем выполнение прерванной команды повторяется. Это можно сделать, так как для всех повторно запускаемых исключений (кроме 03h - прерывание по точке останова и 04h - переполнение) в стек включается адрес не следующей за прерванной командой, а адрес первого байта команды, которая вызвала исключение. Выполнив команду IRET, программа обработки исключения вновь передаст управление прерванной команде. Свойством повторной запускаемости обладает большинство зарезервированных прерываний, кроме следующих:
01h - прерывание для пошаговой работы;
08h - двойная ошибка;
09h - превышение сегмента сопроцессором;
0Dh - исключение по защите памяти;
10h - исключение сопроцессора.
После возврата процессора в реальный режим необходимо восстановить состояния контроллера прерываний. При этом BIOS перепрограммирует контроллер прерываний для работы в реальном режиме При загрузке операционной системы, после инициализации процедурой POST, все неиспользуемые входы контроллеров будут замаскированы (на запросы прерываний реагировать не будут), их векторы прерываний указывают на процедуру с единственной инструкцией IRET (возврат). Для подключения программы обработчика прерывания необходимо загрузить обработчик в память и установить указатель на него в таблице прерываний, размаскировать соответствующий ему вход в контроллере прерываний, для чего выполняется обнуление соответствующего бита регистра маски. Если же обработчик прерывания удаляется из памяти, предварительно должен быть замаскирован соответствующий ему вход контроллера. Все изменения в таблице прерываний должны выполняться при замаскированных прерываниях, чтобы избежать попытки использования вектора в процессе его модификации. Для устройств PCI выделяется четыре проводных линии запросов (IRQX, IRQY, IRQZ, IRQW), соединяемых с контактами INTA#, INTB#, INTC# и INTD# всех слотов PCI с циклическим смещением цепей. Таким образом, на слотах PCI остаются доступными лишь четыре обычные линии запросов. Устройство PCI вводит сигнал прерывания низким уровнем на выбранную линию INTx#. Этот сигнал должен удерживаться до тех пор, пока программный драйвер, вызванный по прерыванию, не сбросит запрос прерывания, обратившись по шине к данному устройству. Если после этого контроллер прерываний снова обнаруживает низкий уровень на линии запроса, это означает, что запрос на ту же линию ввело другое устройство, разделяющее данную линию с первым, и оно тоже требует обслуживания. Линии запросов от слотов PCI и PCI-устройств системной платы коммутируются на входы контроллеров прерываний относительно произвольно. Конфигурационное программное обеспечиние может определить и указать занятые линии запросов и номер входа контроллера прерываний обращением к конфигурационному пространству устройства. Программный драйвер, прочитав конфигурационные регистры, тоже может определить эти параметры для того, чтобы установить обработчик прерываний на нужный вектор и при обслуживании сбрасывать запрос с требуемой линии. Каждая функция устройства PCI может задействовать свою линию запроса прерывания, но его обработчик прерывания должен быть готовым к ее разделению (совместному использованию) с другими устройствами.
5. Контроллер прерываний APIC (AdvancedProgrammableInterruptController)
Система с APIC (рис.3.) состоит из локальных контроллеров, установленных в процессорах, и контроллеров прерываний (одного или нескольких) от устройств ввода/вывода. Задача каждого локального контроллера (Local APIC) — трансляция полученных сообщений в сигналы, вызывающие все аппаратные прерывания своего процессора — маскируемые (INTR), немаскируемые (NMI) и прерывания системного обслуживания (SMI). Кроме того, локальные APIC позволяют каждому процессору генерировать прерывания для других процессоров. Локальный контроллер имеет внутренний интервальный таймер, позволяющий вырабатывать прерывания через программируемый интервал времени.
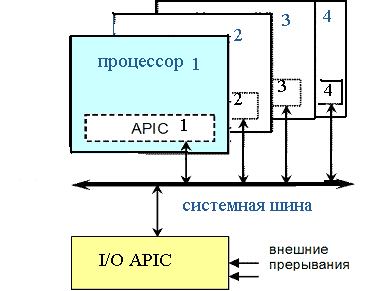
Рис.3. Взаимодействие встроенного APIC и I/O APIC по системной шине
Контроллер прерываний от ввода/вывода (I/O APIC) в мультипроцессорном режиме отвечает за распределение прерываний по процессорам, для чего может использоваться статическое или динамическое распределение. В случае статического распределения для каждого номера прерывания указывается номер процессора, который его обслуживает. В случае динамического распределения каждое прерывание направляется наименее приоритетному в данный момент процессору. Этот же контроллер отвечает за распространение сигналов о системных событиях (NMI, INIT, SMI) и межпроцессорных прерываний.
Встроенный в процессор программируемый контроллер прерываний APIC расширяет количество ранее введенных функций контроллера прерываний. Встроенный APIC предназначен для регистрации прерываний от источников внутри процессора (например, от блока температурного контроля) или от внешнего контроллера прерываний и передачи их ядру процессора на обработку. Особо важная роль возлагается на встроенный APIC в многопроцессорных системах, где APIC принимает и генерирует сообщения о межпроцессорных прерываниях (IPI - InterProcessor Interrupt). Такие сообщения могут использоваться для распределения обработки прерываний между процессорами или для выполнения системных функций (первоначальная загрузка, диспетчеризация задач и т.п.). Все процессоры многопроцессорной системы принимают сигналы, поступающие на вход INTR# ( маскируемые аппаратные прерывания). Бит IF в регистре флагов позволяет заблокировать (замаскировать) обработку таких прерываний. Сигналы прерываний, поступающие на вход NMI#, являются немаскируемыми аппаратными прерываниями Немаскируемые прерывания не блокируются флагом IF. Как мы уже знаем, пока выполняется программа - обработчик немаскируемого прерывания, процессор блокирует получение немаскируемых прерываний до выполнения инструкции IRET, чтобы исключить одновременную обработку нескольких немаскируемых прерываний. Структура встроенного APIC является архитектурным подмножеством микросхемы контроллера прерываний Intel 82489.
Встроенный APIC различает следующие источники прерываний:
1. От локальных внутренних устройств. Сигнал запроса прерывания поступает от устройства, непосредственно подключенного к сигналам LINT0 и LINT1 (например, от контроллера прерыванийтипа 8259A).
2. От внешних устройств. Сигнал запроса прерывания от устройства, подключенного к системному контроллеру прерываний.
3.Межпроцессорные (IPI). В многопроцессорных системах один из процессоров может прервать другой при помощи сообщения IPI.
4. От таймера APIC. Встроенный APIC содержит таймер, который можно запрограммировать на генерацию прерывания по достижении определенного отсчета времени.
5. От таймера монитора производительности. Современные процессоры содержат блок мониторинга производительности. Этот блок можно запрограммировать таким образом, чтобы связанный с ним таймер при достижении определенного отсчета генерировал прерывание.
6. От термодатчика. Современные процессоры содержат встроенный блок температурного контроля, который можно запрограммировать на генерацию прерываний.
7. Внутренние ошибки APIC. Встроенный APIC может генерировать прерывания при возникновении внутренних ошибочных ситуаций (например, при попытке обратиться к несуществующему регистру APIC).
Источники 1, 4, 5, 6, 7 считаются локальными источниками прерываний и обслуживаются специальным набором регистров APIC, называемым таблицей локальных векторов (LVT - local vector table). Два других источника обрабатываются APIC через механизм сообщений. Эти сообщения, начиная с процессора Pentium 4 передаются по системной шине, поэтому контроллер прерываний подключен непосредственно к обычному системному интерфейсу (например, к шине PCI). Наличие встроенного APIC в процессоре обнаруживается при помощи инструкции CPUID(1). После сигнала RESET встроенный APIC включен, однако впоследствии он может быть отключен, тогда процессор будет работать с прерываниями как Intel-386/486 (линии LINT0 и LINT1 будут использоваться как NMI# и INTR#, к которым может быть подключен контроллер прерываний типа 8259A).
Таблица локальных векторов (LVT) состоит из шести 32-битных регистров:
регистр вектора прерывания от таймера;
регистр вектора прерывания от термодатчика
регистр вектора прерывания от монитора производительности
регистр вектора прерывания LINT0;
регистр вектора прерывания LINT1;
регистр вектора прерывания ошибки.
Значения в этих регистрах определяют:
номер вектора прерывания;
тип прерывания ( fixed - прерывание с указанным вектором, SMI - системное прерывание, переход в режим системного управления, NMI - немаскируемое прерывание, INIT - сброс, ExtINT - внешнее прерывание: при получении такого запроса на прерывание процессор генерирует цикл INTA и ожидает номер вектора прерывания от внешнего контроллера;
маску прерывания (прерывание может быть замаскировано).
Эти регистры также отражают состояние прерывания (доставляется ли это прерывание ядру процессора в данный момент).
Кроме того, APIC содержит регистры управления таймером APIC, регистр версии, регистр ошибки, регистры, связанные с обслуживанием прерываний (регистр приоритета, регистр запроса IRR, регистр обслуживания ISR), и регистры, связанные с передачей и приемом IPI.
Контроллер APIC в первую очередь предназначен для симметричных мультипроцесорных систем (SMP), описанных в документе Intel «MultiProcessor Specification» (MPS). Здесь симметрия рассматривается в двух аспектах:
симметрия памяти — все процессоры пользуются общей памятью, работают с одной копией ОС;
симметрия ввода/вывода — все процессоры разделяют общие устройства ввода/вывода и общие контроллеры прерываний.
Система может быть симметричной по памяти, но асимметричной по прерываниям от ввода/вывода, если для них используется выделенный процессор. Симметрию по прерываниям обеспечивает APIC. Прерывания в мультипроцессорных системах подробно рассмотрены в документе «Intel Architecture Software Developer’s Manual Volume 3: System Programming Guide», доступном на сайте http://www.intel.com. Здесь же ограничимся описаниями возможностей, предоставляемыми для сигнализации прерываний ввода/вывода контроллерами APIC.
Контроллер I/O APIC является частью чипсета системной платы, например, он входит в хабы ICH2 и ICH3 чипсетов Intel. В специфкации MPS определено три режима обработки прерываний:
Режим PIC (PIC Mode) — эмуляция пары PIC 8259A с традиционной передачей сигналов прерывания одному процессору (загрузочному, BSP Bootstrap Pro cessor) по линиям INTR и NMI;
Ррежим работы с подачей сигналов прерывания по локальной шине APIC. При этом I/O APIC может работать совместно с PIC 8259A, обеспечивая дополнительные возможности (в частности, дополнительные входы запросов прерываний);
Режим, когда прерывания от устройств генерирует I/O APIC; прерывания могут доставляться любому процессору; каждый вход запроса индивидуально программируется с помощью таблицы перенаправления прерываний (I/O Redirection Table).
Первые два режима обеспечивают полную совместимость с системой прерываний PC/AT, с программной точки зрения они эквивалентны, различия лежат в области схемотехники. По аппаратному сбросу или при включении питания система начинает работать в одном из этих режимов. Когда система подготовится к переходу в многопроцессорный (MP) режим, APIC переводится в симметричный режим и активизирует таблицу перенаправлений прерываний (предварительно программно инициализированную).
В MP-системе присутствует таблица описаний ее компонентов. К системе прерываний в этой таблице относятся описатели всех I/O APIC, а также описатели назначений всех используемых источников прерываний, связанных с I/O APIC и локальными APIC. В описателе назначения для каждого источника прерываний указывается:
тип прерывания: векторное с передачей вектора через APIC, векторное с внешней передачей вектора (от PIC 8259A), NMI или SMI;
полярность сигнала и его тип (уровень или перепад);
идентификатор шины, на которой расположен источник;
идентификатор запроса на этой шине;
идентификатор и номер входа APIC, к которому подключен данный запрос.
Для симметричных многопроцессорных систем допустимы векторы в диапазоне 10h–FEh. Уровень приоритета прерывания определяется номером его вектора, деленным на 16. Самый приоритетный уровень — нулевой.
Контроллер I/O APIC позволяет вырабатывать значительное число запросов прерываний; каждому запросу соответствует свой элемент в таблице перенаправлений, находящейся в APIC. С запросами связаны индивидуальные входы INTINn; определенный уровень или перепад сигнала на этих входах вызывает соответствующие запросы. Вектор (следовательно, и приоритет) для каждого запроса программируется индивидуально. Более совершенные модели I/O APIC позволяют вызывать прерывание с записью номера входа в регистр контроллера, что, например, используются для поддержки прерываний MSI на шине PCI. При этом возможна и экономия сигнальных входов: APIC может иметь входы INTINn не для всех номеров запросов, посылаемых через запись в этот регистр. Однако число запросов всегда ограничивается размером таблицы перенаправлений. Регистры контроллеров APIC отображаются на пространство памяти. Все локальные контроллеры APIC используют один и тот же диапазон адресов (по умолчанию базовый адрес FEE0 0000h) — к их регистрам обращаются только программы, исполняемые на их же процессорах, и эти обращения не выводятся на системную шину. Контроллеры I/O APIC доступны всем процессорам, по умолчанию базовый адрес первого I/O APIC — FEC0 0000h, базовые адреса остальных контроллеров (если таковые имеются) назначаются последовательно с шагом 1000h. Часть регистров адресуется непосредственно, большая часть регистров, включая и таблицу перенаправлений, адресуется косвенно.
Шина PCI имеет прогрессивный механизм оповещения об асинхронных событиях, основанный на передаче сообщений MSI (Message Signaled Interrupts). Здесь для сигнализации запроса прерывания устройство запрашивает управление шиной и, получив его, посылает сообщение. Сообщение выглядит как обычная запись двойного слова в ячейку памяти, адрес (32-битный или 64-битный) ишаблон сообщения на этапе конфигурирования устройств записываются в конфигурационные регистры устройства (точнее, функции). В сообщении старшие 16 бит всегда нулевые, а младшие 16 бит несут информацию об источнике прерывания. Устройство (функция) могут нуждаться в сигнализации нескольких типов запросов; в соответствии с его потребностями и своими возможностями система указывает устройству (функции), сколько различных типов запросов оно может вырабатывать. Прерывания через MSI позволяют избежать разделяемости, обусловленной дефицитом линий запросов прерывания в PC. Кроме того, они решают проблему целостности данных: все данные, записываемые устройством до посылки MSI, дойдут до получателя гарантированно раньше начала обработки MSI. Прерывания через MSI от одних устройств в одной системе могут использоваться наряду с обычными INTx# от других устройств. Но устройство (функция), использующее MSI, не должно использовать прерывания через линии INTx#. Механизм MSI может использоваться на системных платах, имеющих контроллер прерываний APIC. Правда, конкретная реализация поддержки MSI может потенциальные возможности облегчения идентификации большого числа запросов прерывания свести лишь к увеличению числа доступных запросов прерываний (и используемых ими векторов). Всем устройствам PCI назначается один и тот же адрес сообщений (Message Address = FEC00020h), по которому в APIC находится регистр IRQ Pin assertion. В сообщении используются лишь младшие 5 бит, в которых указывается номер взводимого запроса прерывания в диапазоне 1–23 (исключая 2, 8 и 13). Прерывания с номерами, используемыми в MSI, не могут использоваться совместно (разделяемо) с прерываниями, полученными другими способами (по линиям запросов от устройств PCI и от других устройств системной платы).
6. Режим прямого доступа к памяти
Мы уже знаем, что в вычислительных системах используется два способа организации обмена данными между внешним устройством и памятью.
Первый способ - программируемый ввод-вывод (PIO). В этом режиме ввод и вывод данных осуществляет процессор, используя для пересылки свои внутренние регистры. Процессор читает данные из порта (регистра) внешнего устройства и записывает его в нужную область памяти, или наоборот, читает данные из памяти и передает их внешнему устройству (дисковый накопитель, например). Режим PIO определяет, с какой скоростью данные передаются от диска к памяти и от памяти к диску. В самом медленном режиме - PIO mode 0 - время цикла передачи данных не превышает 600 наносекунд. За один цикл к диску и от диска передаются 16 бит (2 байта). Отсюда следует, что теоретическая скорость передачи данных в режиме PIO Mode 0 - 3.3 мегабайта в секунду.
Обмен между двумя устройствами может производиться по разным протоколам и с разными задержками на выдачу тех или иных сигналов. Существует 5 режимов PIO, управляемых процессором. Старший режим PIO4 позволяет работать со скоростью 16.6 Мбайт/c. Второй способ обмена - прямой доступ памяти (DMA -Direct Memory Access). Прямой доступ к памяти в современных вычислительных системах претерпел значительные изменения. Познакомимся с основными принципами организации прямого доступа к памяти. Для реализации режима прямого доступа к памяти, внешнее устройство должно отправить процессору запрос (поэтому такому устройству должна быть выделена специальная линия запроса прерывания).
Процессор программирует специальный контроллер (контроллер DMA) на обслуживание работы внешнего устройства в режиме прямого доступа к памяти. Он задает адрес памяти, размер передаваемого блока данных, направление передачи (чтение или запись), после чего дает команду на выполнение.

Рис.4. Взаимодействие памяти и внешнего устройства в режиме DMA
Пересылкой данных управляет контроллер DMA. Процессор, в это время, может продолжить выполнение прерванной программы, но доступа к памяти он не имеет и не может вмешаться в процесс обмена, пока контроллер не закончит передачу данных и не выдаст соответствующего сообщения. Режимы контроллера DMA позволяют передавать данные как по одному слову (Single Word), так и по несколько сразу (Multi Word). Передача данных со скоростью до 16.6 Мбайт/c - обычный протокол, со скоростью 66 Мбайт/c (или 100) - протокол UltraDMA. Упрощенная схема обмена внешнего устройства с памятью в режиме прямого доступа к памяти показана на рис.4.
Контроллер DMA имеет несколько каналов. Каждому периферийному устройству, работающему в режиме прямого доступа к памяти выделяется канал с определенным номером. Устройство может послать контроллеру запрос обмена — DRQx и получить разрешение обмена — DACKx#. На шине управления устанавливается сигнал записи или чтения данных при работе внешнего устройства с памятью. Для передачи данных используется шина данных (рис.5.). При операциях с прямым доступом к памяти по каналу DMA адрес порта указывать не требуется, посылаемые сигналы идентифицируются по номеру канала. Временная диаграмма цикла передачи данных из внешнего устройства в память будет выглядеть следующим образом:
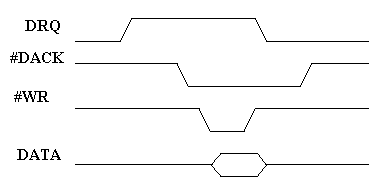
Рис.5. Схема обмена сигналами управления для передачи данных в режиме DMA
Получив запрос DRQx ( х - номер канала DMA, выделенного устройству), контроллер DMA запрашивает управление шиной и ждет разрешения от процессора. Процессор прерывает выполнение текущей программы, программирует контроллер прямого доступа на определенный режим передачи данных и посылает сигнал разрешения прямого доступа к памяти. Контроллер выставляет адрес ячейки памяти и формирует сигналы DACKx# и WR#. Сигнал DACKx# указывает на то, что операция выполняется для канала х, WR# определяет режим записи данных, при чтении устанавливается сигнал чтения RD). Контроллер передавая данные модифицирует счетчик адреса и осуществляет передачу одного слова за другим. Контроллер повторяет эти шаги для каждого следующего сигнала DRQx, пока не будет исчерпан счетчик циклов. В последнем цикле обмена контроллер формирует общий сигнал окончания ТС (TerminateCount), который может быть использован для формирования сигнала аппаратного прерывания. При работе в режиме прямого доступа к памяти контроллер DMA выполняет следующие функции:
принимает запрос на прямой доступ к памяти от внешнего устройства;
формирует запрос процессору на захват системной шины;
принимает сигнал, подтверждающий переход процессора в состояние захвата шины внешним устройством (перехода в состояние, при котором процессор отключается от системной шины);
формирует сигнал, сообщающий внешнему устройству о начале выполнения циклов прямого доступа к памяти;
выдает на шину адреса системной шины адрес ячейки оперативной памяти, предназначенной для обмена;
вырабатывает сигналы, обеспечивающие управление обменом данными;
по окончании цикла прямого доступа к памяти контроллер снимает сигнал запроса, процессор снова становится хозяином системной шины.
Каждый канал контроллера прямого доступа к памяти состоит из 5-ти регистров, четырех 16-разрядных регистров (рис.6) и одного 6-ти разрядного:
регистра текущего адреса (CAR);
регистра циклов прямого доступа к памяти (CWR);
регистра хранения базового адреса блока памяти (BAR);
регистра хранения базового числа циклов прямого доступа к памяти (WCR);
6-разрядного регистра режима (MR).
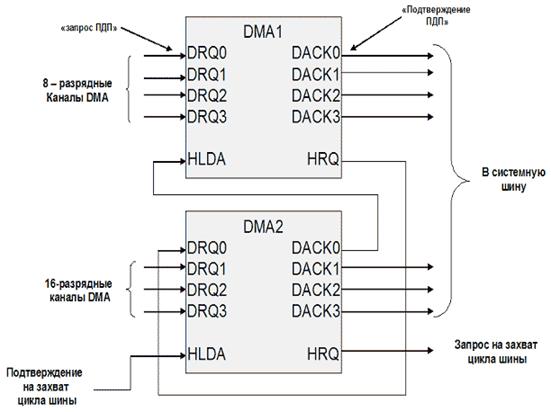
Рис.6. Каскадное включение контроллеров DMA
Регистр текущего адреса хранит текущий адрес ячейки памяти при выполнении цикла прямого доступа к памяти. После выполнения каждого цикла передачи данных содержимое этого регистра уменьшается на единицу. То есть при выполнении циклов регистр работает в режиме вычитающего счетчика. В режиме инициализации содержимое регистра текущего адреса принимает базовый адрес из регистра хранения базового адреса, а в счетчик циклов загружается базовое число циклов передачи данных. Для организации прямого доступа в память в компьютерах IBM PC/XT использовалась одна 4-канальная микросхема DMA 18237, канал 0 которой был предназначен для регенерации динамической памяти (сейчас регенерацию осуществляет внутреннее устройство управления микросхемы памяти). Каналы 2 и 3 служат для управления передачей данных между дисководами гибких дисков, а также винчестером и оперативной памятью соответственно. Свободным оставался только канал DMA 1. Канал DMA 1 обычно используется звуковыми картами. Один канал DMA может использоваться различными устройствами, но не одновременно. IBM PC/AT -совместимые компьютеры имеют уже 7 каналов прямого доступа к памяти. Как и для контроллеров прерываний, увеличение числа каналов было достигнуто путем каскадного включения двух микросхем i8237, интегрированных в микросхему контроллера периферии (южный мост); канал 0 DMA2 используется для подключения каналов контроллера DMA1 (рис. 6) .
Каналы первого контроллера по-прежнему используются как 8-ми разрядные, каналы второго контроллера используются для передачи 16-ти разрядных данных в одном цикле обмена данными. Рассмотрим устройство контроллера DMA (рис. 7)
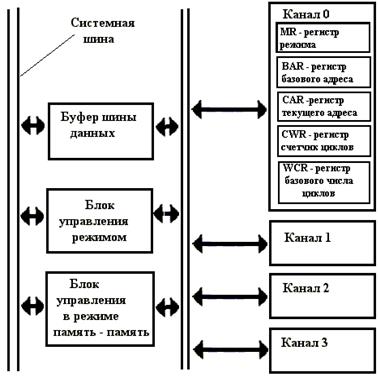
Рис.7. Структурная схема контроллера DMA
Структура одного канала показана на примере канала 0. В каждом канале регистры BAR и WCR предназначены для хранения констант - базового адреса и базового числа циклов. Они загружаются в режиме программирования контроллера одновременно с регистрами CAR (базовый адрес памяти) и CWR ( текущий адрес памяти). Регистр режима MR определяет режим работы канала. Он содержит информацию о типе цикла прямого доступа (чтение (ОП - ВУ), запись (ОП - ВУ), проверка), режиме изменения регистра текущего адреса (CAR) - увеличение или уменьшение и режиме работы канала - передача по запросу, одиночная передача, блочная передача, каскадирование (работа каскадной схемы контроллера DMA). Блок управления режимом содержит регистр команд и регистр условий. Регистр команд блока управления режимом определяет основные параметры работы канала. Загружается при программировании контроллера микропроцессором. Регистр условий хранит разрешение на прямой доступ каждому каналу (устанавливается программно) и запоминает факт перехода через 0 в регистре хранения базового числа циклов каждого канала. Контроллер DMA может работать в двух основных режимах: в режиме программирования и режиме выполнения циклов прямого доступа к памяти. В режиме программирования процессор работает с контроллером прямого доступа к памяти, как с внешним устройством. После загрузки в контроллер DMA управляющих слов контроллер переходит в пассивное состояние. В этом состоянии контроллер находится до тех пор, пока не поступит запрос на прямой доступ к памяти от внешнего устройства или от процессора. Обнаружив запрос на прямой доступ к памяти, контроллер выставляет процессору запрос на захват системной магистрали и ожидает от него подтверждения захвата шины, т.е. отключения процессора от системной шины и перехода его выходов в состояние высокого сопротивления ( Z-состояние). При получении сигнала подтверждения захвата (HLDA) контроллер начинает выполнять циклы передачи данных в режиме прямого доступа к памяти. Необходимые для управления шиной сигналы вырабатываются самим контроллером DMA. Контроллер DMA можно рассматривать как устройство, являющееся главным абонентом системной шины. С введением шины PCI изменился принцип организации работы внешних устройств с памятью в режиме DMA. На шине PCI отсутствуют сигналы DREQx и DACKx, здесь применяется технология захвата управления шиной внешним устройством (Bus Mastering - BM). Технология захвата управления шиной (busmastering) совместима с протоколом режима UDMA и реализует работу в режиме DMA ( передачу данных из памяти в устройство напрямую или наоборот, минуя процессор) для каждого устройства, которое может быть главным абонентом системной шины. Концепция главного абонента шины делает прямой доступ к памяти излишним. Дополнительно установленная схема главного абонента шины на адаптере внешнего устройства позволяет осуществлять прямой доступ к памяти каждому такому устройству. Адаптер главного абонента шины может вырабатывать все сигналы управления шиной сам и, следовательно, имеет возможность обращаться к области адресов памяти и ввода-вывода любым необходимым способом. Использование внешнего главного абонента шины обеспечивает большую гибкость и эффективность, чем работа с контроллером DMA, но требует более сложных арбитражных операций. Это ведет к существенному увеличению сложности и стоимости устройства, работающего в режиме управления шиной. Можно, конечно, рассматривать устройство управления шиной, расположенное на адаптере внешнего устройства, как форму контроллера DMA, который организует быстрый обмен данными между основной памятью и адаптером. Однако прямой доступ к памяти - это только часть концепции главного абонента шины.
7. Распределение ресурсов, технология Plug and Play
Технология Plug and Play (включай и работай) была разработана известнейшими компаниями Intel, Compag Computer, Microsoft и Phoenix Technologies в 1993 году для решения проблем изменения конфигурации IBM PC-совместимых компьютеров. Наращивание возможностей персонального компьютера осуществляется при помощи плат расширения. Платы расширения используют такие ресурсы ЭВМ как порты ввода-вывода, линии запросов прерывания IRQ, каналы прямого доступа к памяти DMA. Примерное распределение аппаратных ресурсов для некоторых устройств приведено в таблице 1.
Таблица 1
| Устройство | UMB | Порты | IRQ | DMA |
| Контроллер VGA (графический) | A000-BFFF | |||
| C000-C7FF | 3B0-3DF | 2 | - | |
| Контроллер флоппи | - | 3F0-3F7 | 2 | - |
| LPT1 | - | 370-37F | 7 | - |
| COM1 | - | 3F8-3FF | 4 | - |
| COM2 | - | 2F8-2FF | 3 | - |
| Адаптер SCSI | D800-DBFF | - | 14 | - |
| Сетевой адаптер | DC00-DFFF | 300-30F | 10 | - |
| Sound Blaster(звуковая карта) | - | 220 | 5 | 1 |
Обращение к одним и тем же ресурсам различных устройств приводит к конфликтам. Обнаружить конфликтные ситуации позволяют программы, предназначенные для диагностики и тестирования компьютера, например, такие как Norton Diagnostic, Checkit, Microsoft Diagnostic, а также специальные программы для профессионалов. Технология Plag and Play позволяет устранить возможность конфликтов. Для этого необходимо, чтобы эту технологию поддерживали все дополнительные платы, расширяющие возможности компьютера, все основные ресурсы компьютера, включая программное обеспечение, системные шины, интерфейсы. Первой системной шиной, поддерживающей технологию Plag and Play, была шина EISA , в настоящее время ее поддерживают практически все современные шины ( PCI, WireFire и т.д.).
Как работает Plag and Play
После включения компьютера BIOS- система Plug and Play определяет наличие устройств, необходимых для первоначальной загрузки. Затем читает идентификатор, который записан в специальном запоминающем устройстве каждого устройства, поддерживающего функции Plug and Play. Идентификатор используется в дальнейшем как адрес устройства при обращении к нему. BIOS производит загрузку операционной системы. Специальный драйвер-менеджер конфигурации запрашивает подчиненные драйверы - инумераторы шин (bus enumerators) о наличии устройств,требующих системных ресурсов. Если устройство не использует технологию Plag and Play, информация о нем считывается из специальной базы данных, например, в Windows 9Х имеется база данных, в которой хранится информация о нескольких тысячах устройств. В оперативной памяти компьютера создается специальная запись в виде дерева аппаратной конфигурации (hardware tree),содержащая данные об устройствах, полученные менеджером конфигурации. Арбитр ресурсов (resourse arbitrator), используя дерево конфигурации, распределяет системные ресурсы в порядке установленных приоритетов. Менеджер конфигурации оповещает инумераторы, что ресурсы распределены. Инумераторы заносят в регистры контроллеров информацию о том, какие ресурсы и в каком объеме могут использоваться устройствами Plag and Play. При этом не исключается возможность конфликта между динамическим распределением ресурсов и программным обеспечением,работающим с аппаратурой, минуя BIOS. Первую Plag and Play BIOS выпустила в начале 1994 года фирма Phoenix Technologies. В микросхему BIOS была включена обычная системная BIOS (64Кб),расширение для шины PCI ( 2-10 Кб ) и сама поддержка Plag and Play (12-16 Кб). Все платы расширения в системе Plag and Play имеют специальную микросхему - PLD ( Programmable Logic Device ),которая позволяет плате сообщать свой идентификатор и список требуемых и поддерживаемых ресурсов.
Список литературы
1. Гук. М.Ю. Аппаратные средства IBM PC: Энциклопедия, 3-е изд.-СПб: Питер, 2006 - 1072с.
2. Цилькер Б.Я., Орлов С.А. Организация ЭВМ и систем: Учебник для вузов.- СПб.: Питер 2006. - 672с.
3. Мелехин В.Ф. Павловский Е.Г. Вычислительные машины, системы и сети: Учебник.- М.: Издательский центр Академия, 2006. - 560с
4.Леонтьев В.П. Новейшая энциклопедия персонального компьютера:Энциклопедия. - М.: ОЛМА-ПРЕСС, 2006. - 869с
5.Таненбаум Э.С. Архитектура компьютера. Классика computer science. 4-е изд.- СПб.: Питер, 2006. - 704с.