Синтаксический разбор строк и конечные автоматы
СОДЕРЖАНИЕ: Синтаксический разбор строк и конечные автоматы Андрей Боровский В этой статье речь пойдет о том, как анализировать информацию, переданную в виде последовательности символов (строку) и выделять из нее значимые элементы. Мы рассмотрим сравнительно простые ситуации, с которыми программистам приходится сталкиваться при решении самых разных задач: разбор выражений с простой синтаксической структурой, но с довольно свободными правилами записи.Синтаксический разбор строк и конечные автоматы
Андрей Боровский
В этой статье речь пойдет о том, как анализировать информацию, переданную в виде последовательности символов (строку) и выделять из нее значимые элементы. Мы рассмотрим сравнительно простые ситуации, с которыми программистам приходится сталкиваться при решении самых разных задач: разбор выражений с простой синтаксической структурой, но с довольно свободными правилами записи.
Допустим, в программе, которую вы пишете, нужен модуль, анализирующий текст HTML-страницы. Мы напишем функцию, которая, получив строку, содержащую тэг, извлекала бы из этой строки все атрибуты тэга и их значения. Структуру тэга можно схематично представить следующим образом: ТЭГ атрибут1 = значение атрибут2 = значение ... На первый взгляд задача кажется очень простой, однако ситуация осложняется из-за достаточно мягких правил языка HTML. Между именем атрибута, знаком равенства и значением может стоять любое число разделительных символов (пробелов, символов табуляции и даже символов перехода на новую строку), или же разделительные символы могут вообще отсутствовать. Значения атрибутов могут быть либо заключены в кавычки, либо нет, при этом значение, заключенное в двойные кавычки, может содержать символы одинарных кавычек, и наоборот. Кроме того, не всем атрибутам тэгов присваиваются значения.
Для решения указанной проблемы мы напишем функцию ParseTag, анализирующую переданный ей тэг и создающую списки атрибутов тэга и их значений. Функция ParseTag действует по принципу конечного автомата. Конечные автоматы и подобные им структуры широко применяются при обработке строк. Сферы наиболее частого применения конечных автоматов включают поиск подстрок по заданному образцу, обработку регулярных выражений (regular expressions), лексический и синтаксический анализ. Конечные автоматы широко применяются в трансляторах и интерпретаторах (не говоря уже о таких задачах, как проектирование логических устройств).
Строгое определение конечных автоматов можно найти в любом учебнике по теории алгоритмов, мы же здесь ограничимся интуитивным определением. В каждый данный момент времени конечный автомат может находиться в одном из возможных состояний (число состояний, в которых может находиться конечный автомат – конечно). Автомат последовательно считывает символы входного текста (строки). Каждый считанный символ либо переводит автомат в новое состояние, либо оставляет его в прежнем состоянии. Формально автомат можно описать при помощи функции переходов. Аргументами этой функции являются предыдущее состояние автомата и очередной считанный символ, а значением – новое состояние автомата.
Множество состояний для нашего автомата включает:
ReadTag – читает имя тэга;
WaitAttr – ожидает имя атрибута;
WaitAttrOrEq – ожидает имя атрибута или символ =;
ReadAttr – читает имя атрибута;
WaitValue – ожидает значение атрибута;
ReadValue – читает значение атрибута без кавычек;
ReadValueSQ – читает значение атрибута в одинарных кавычках;
ReadValueDQ – читает значение атрибута в двойных кавычках.
Следуя терминологии конечных автоматов, мы можем назвать состояния WaitAttr, WaitAttrOrEq, ReadAttr и ReadValue допускающими. Это означает, что если после обработки переданной строки автомат находится в каком-либо другом состоянии, значит, тэг содержит ошибку (автомат не проверяет, завершается ли строка символом , это – задача блока, вызывающего функцию ParseTag).
Процесс программной реализации автомата можно упростить, построив для него диаграмму переходов. Далее приводится диаграмма переходов для нашего автомата. Цифры на диаграмме соответствуют номерам состояний, перечисленных выше.
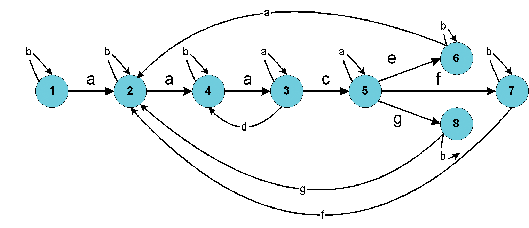
Рисунок 1
Пояснения к диаграмме:
a - символ-разделитель
b - любой символ кроме разделителя
c - символ =
d - любой символ кроме разделителя и символа =
e - любой символ кроме разделителя и кавычек
f - символ одинарных кавычек
g - символ двойных кавычек
Ниже приводится текст функции ParseTag и вспомогательной функции GetSubString. У функции ParseTag есть четыре параметра: строка, содержащая тэг, заключенный в и , строка, в которой возвращается имя тэга, и объекты типа TStringList, содержащие имена и значения атрибутов соответственно. Если данному атрибуту не сопоставлено никакое значение, в списке значений имени атрибута соответствует пустая строка. В случае успешного выполнения функция возвращает значение 0, в противном случае – 1.
Автомат реализован в теле цикла функции ParseTag. Добавление нового элемента в список осуществляется в момент перехода из состояния ReadXXX в какое-либо другое состояние. Кроме этого в цикл добавлена проверка ошибок синтаксиса, например, двух символов =, следующих подряд. После завершения цикла мы анализируем состояния автомата. Если автомат находится в одном из состояний ReadXXX, происходит добавление последнего элемента в соответствующий список. Если автомат не находится ни в одном из допускающих состояний, функция возвращает сообщение о синтаксической ошибке.
function GetSubString(const S : String; Start, Stop : Integer): String; begin SetLength(Result, Stop-Start); Move(S[Start], Result[1], Stop-Start); end; function ParseTag(const Tag : String; var TagName : String; Attrs, Values : TStringList): Integer; type // Возможныесостояния TState = (ReadTag, WaitAttr, WaitAttrOrEq, ReadAttr, WaitValue, ReadValue, ReadValueSQ, ReadValueDQ); const // Значения, возвращаемыефункцией GetLink resOK = 0; // разбор прошел успешно resBadSyntax = -1; // синтаксическая ошибка // Набор возможных разделительных символов Delimeters = [ , #9, #13, #10]; var State : TState; StartPos, i : Integer; begin Result := resOK; // очищаемсписокэлементов Attrs.Clear; Values.Clear; State := ReadTag; // входноесостояниеавтомата i := 2; // пропускаемсимвол while (Tag[i]) and (iLength(Tag)) do begin case State of ReadTag: if Tag[i] in Delimeters then begin // чтениеименитэгазакончено TagName := GetSubString(Tag, StartPos, i); State := WaitAttr; end; WaitAttr: if (Tag[i] in Delimeters) = False then begin if Tag[i] = = then begin Result := resBadSyntax; Exit; end; StartPos := i; State := ReadAttr; end; ReadAttr: if (Tag[i] in Delimeters) or (Tag[i] = =) then begin // чтение имени атрибута закончено, добавляем имя атрибута в список Attrs.Add(GetSubString(Tag, StartPos, i)); if Tag[i] = = then State := WaitValue else State := WaitAttrOrEq; end; WaitAttrOrEq: if (Tag[i] in Delimeters) = False then begin if Tag[i] = = then State := WaitValue else begin // начинается чтение имени атрибута // предыдущему атрибуту не присвоено никаких значений, // добавляем пустую строку в список Values Values.Add(); State := ReadAttr; StartPos := i; end; end; WaitValue: if (Tag[i] in Delimeters) = False then begin if Tag[i] = = then begin // два символа = подряд Result := resBadSyntax; Exit; end; if Tag[i] = then begin // чтение значения начнется со следующего символа после кавычек: StartPos := i + 1; State := ReadValueDQ; end else if Tag[i] = then begin // чтение значения начнется со следующего символа после кавычек: StartPos := i + 1; State := ReadValueSQ; end else begin // чтение значения без кавычек StartPos := i; State := ReadValue; end; end; ReadValue: if Tag[i] in Delimeters then begin // чтениезначениязакончено Values.Add(GetSubString(Tag, StartPos, i)); State := WaitAttr; end; ReadValueDQ: if Tag[i] = then begin // чтение значения в двойных кавычках закончено Values.Add(GetSubString(Tag, StartPos, i)); State := WaitAttr; end; ReadValueSQ: if Tag[i] = then begin // чтение значения в одинарных кавычках закончено Values.Add(GetSubString(Tag, StartPos, i)); State := WaitAttr; end; end; // case State of Inc(i); end; // while (Body[i]) and (iLength(Tag)) do // проверяем состояние автомата после обработки строки // последним символом строки должен быть case State of ReadValue : Values.Add(GetSubString(Tag, StartPos, i)); ReadAttr : Attrs.Add(GetSubString(Tag, StartPos, i)); ReadTag : TagName := GetSubString(Tag, StartPos, i); WaitAttr, WaitAttrOrEq: ; // ничегонеделаем else Result := resBadSyntax; // другиесостояниянедопустимы end; end; |
Одной из важных особенностей такого подхода к разбору строк является то, что анализ выполняется по мере считывания символов, с использованием информации о текущем символе и символах, прочитанных ранее. Это позволяет вести обработку данных, передающихся по некоторому последовательному каналу, непосредственно в процессе их поступления.
Фактически представленная функция выполняет две операции: выделяет в переданной строке синтаксические элементы (tokens) и определяет, что представляет собой данный элемент (имя тэга, имя атрибута, значение атрибута). Решение о том, чем является следующий элемент, принимается заранее, на основании данных о предыдущем элементе и простых правил: за именем тэга следует имя атрибута; за именем атрибута следует либо имя атрибута, либо символ =; за символом = следует значение атрибута.
Процедуры, основанные на конечных автоматах, широко применяются для проверки синтаксиса. В качестве примера рассмотрим функцию CheckMath, выполняющую синтаксический анализ математического выражения:
function CheckMath(const S : String) : Integer; type TState = (Start, InDigit, AfterDigit, InOp, InLPrnt, InRPrnt); const resLPrntMissing = -1; resRPrntMissing = -2; var State : TState; i, ParCount : Integer; begin Result := 0; ParCount := 0; // счетчикскобок State := Start; for i := 1 to Length(S) do case State of Start: // входноесостояние case S[i] of : ; // состояние не меняется 0..9 : State := InDigit; - : State := InOp; // символ - перед числом или скобкой ( : begin Inc(ParCount); State := InLPrnt; end; else begin // Синтаксическаяошибка Result := i; Exit; end; end; InDigit: case S[i] of 0..9 : ; // состояниенеменяется +, -, *, / : State := InOp; ) : begin Dec(ParCount); State := InRPrnt; end; : State := AfterDigit; else begin Result := i; Exit; end; end; AfterDigit: case S[i] of : ; +, -, *, / : State := InOp; ) : begin Dec(ParCount); State := InRPrnt; end; else begin Result := i; Exit; end; end; InOp : case S[i] of : ; 0..9 : State := InDigit; ( : begin Inc(ParCount); State := InLPrnt; end; else begin Result := i; Exit; end; end; InLPrnt: case S[i] of 0..9 : State := InDigit; - : State := InOp; ( : Inc(ParCount); : ; else begin Result := i; Exit; end; end; InRPrnt: case S[i] of +, -, *, / : State := InOp; ) : Dec(ParCount); : ; else begin Result := i; Exit; end; end; end; // case State of if State in [InLPrnt, InOp] then //Недопустимыесостояния Result := Length(S); if ParCount 0 then Result := resRPrntMissing else if ParCount 0 then Result := resLPrntMissing; end; |
Входное математическое выражение может содержать целочисленные константы, символы арифметических операций и скобки. Между символами операций, скобками и числами допустимо любое количество пробелов. Функция CheckMath возвращает значение 0, если переданное ей выражение не содержит ошибок. Если выражение содержит ошибку, функция возвращает положительное число, соответствующее позиции символа, в которой была обнаружена ошибка. Если число открытых скобок не равно числу закрытых, функция возвращает либо -1, либо -2, в зависимости от того, каких скобок не хватает.
В данной функции задействованы следующие состояния:
Start – начальное состояние;
InDigit – прочитана цифра;
AfterDigit – прочитан разделитель после цифры;
InOp – прочитан символ арифметической операции;
InLPrnt – прочитана открывающая скобка;
InRPrnt – прочитана закрывающая скобка.
Символы пробела не изменяют предыдущего состояния, за исключением состояния InDigit. Последнее сделано для того, чтобы не допустить появления пробелов между символами, составляющими численную константу.