Статистичні методи оцінки вимірів в експериментальних дослідженнях
СОДЕРЖАНИЕ: Статистичні методи оцінки вимірів в експериментальних дослідженнях Статистичні методи оцінки вимірів в експериментальних дослідженнях. Класифікація помилок вимірюванняСтатистичні методи оцінки вимірів в експериментальних дослідженнях
Статистичні методи оцінки вимірів в експериментальних дослідженнях. Класифікація помилок вимірювання
Вимірювання – це процес знаходження якої-небудь фізичної величини дослідним шляхом за допомогою спеціальних технічних засобів; це пізнавальний процес порівняння величини чого-небудь з відомою величиною, прийнятою за одиницю (еталон).
Вимірювання бувають статичні , коли вимірювальна величина не змінюється і динамічні , коли вимірювальна величина міняється.
Вимірювання поділяються на прямі і посередні .
При прямих вимірюваннях шукана величина визначається безпосередньо з досліду, при посередніх – функціонально із других величин, які визначені прямими вимірами.
Розрізняють три класи вимірювань.
Особливо точні – еталонні вимірювання з максимально можливою точністю. (Він не застосовується в експериментальних дослідженнях будівельної галузі).
Високоточні – вимірювання, похибка яких не повинна перевищувати заданих значень.
Технічні вимірювання у яких похибка визначається особливостями засобів вимірювання.
Розрізняють абсолютні вимірювання і відносні .
Абсолютні – це прямі вимірювання в одиницях вимірювальної величини (в процентах).
Відносні – вимірювання, які представлені відношенням величини, що вимірюється до однойменної величини, яка є порівняльною. Наприклад відносна вологість грунту W/Wт , де Wт – абсолютна вологість грунту.
Результати вимірювань оцінюються різними показниками:
Похибка вимірювання – це алгебраїчна різниця між дійсним значенням вимірювальної величини (хд ) і отриманим при вимірюванні (хі ).
![]() (6.1)
(6.1)
Е - абсолютна похибка вимірювання;
– відносна похибка вимірюється в процентах;
![]()
=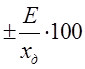 (6.2)
(6.2)
Точність вимірювань – це степінь наближення вимірювання до дійсного значення величини.
Вірогідність вимірювань показує степінь довіри до результатів вимірювання, тобто ймовірність відхилень вимірювання від дійсних значень.
Похибки класифікують на систематичні і випадкові.
Систематичні – це такі похибки вимірювання, які при повторних експериментах залишаються постійними.
Випадкові – похибки, які виникають випадково при повторному вимірюванні, вони можуть бути виключені як систематичні. Різновидністю випадкових похибок є грубі похибки або промахи, які в розрахунок не приймаються, і при обчисленні хд їх виключають. Таким чином:
Е=Е1 +Е2 (6.3)
де Е1 , Е2 – систематичні і випадкові похибки.
Аналіз випадкових похибок основується на теорії випадкових величин.
Числові значення випадкової величини ще не дають повної уяви про цю випадкову величину.
Систематична похибка спостерігається у тих випадках, коли середнє значення послідовних вимірів постійно відхиляється від відомого точного значення в одну сторону – незалежно від числа вимірів. Одним із ефективних способів виявлення і оцінки систематичних похибок є різні рівняння, які описують ті або інші закономірності. При цьому використовується поняття абсолютної і відносної похибки.
Під абсолютною похибкою X розуміють різницю між результатом виміру X і правдивим значенням вимірювальної величини X0.
X=X-X0 (6.4)
Під відносною похибкою x розуміють відношення абсолютної похибки до правдивого значення вимірювальної величини:
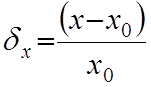 (6.5)
(6.5)
В основі теорії похибок лежать дві такі думки, які підтверджені досвідом:
- остаточна похибка любого вимірювання є результатом великого числа малих похибок, розпреділених випадково;
- додатні і відємні відхилення відносно правдивого значення вимірювальної величини рівноймовірні, причому великі похибки зустрічаються рідко чим малі. Це дає можливість рахувати, що похибки роз приділяються у відповідності з нормальним законом розподілу Гаусса . Щільність нормального розподілу рівна:
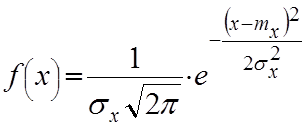 (6.6)
(6.6)
де x-- вимірювальна величина;
f(x)--щільність розподілу, що характеризує ймовірність деякого відхилення X від його математичного сподівання mx (тобто від правдивого значення);
x --середнє квадратичне відхилення.
З даного виразу витікає, що для характеристики розподілу величини достатньо знати величини Х і x , якщо рахувати, що всі можливі значення Х виміряні, тобто є безмежна кількість вимірювань, яка називається генеральною сукупністю . Кожний конкретний результат експерименту являє собою скінчене число вимірів, сукупність яких можна розглядати як випадкову вибірку із генеральної сукупності.
Математичне сподівання випадкової величини
Число, навколо якого групуються значення випадкової величини, є характеристикою положення ; число, що характеризує ступінь розкиданості значень випадкової величини навколо характеристики положення, є характеристикою розсіяння .
Однією з основних характеристик положення випадкових величин є математичне сподівання.
Математичним сподівання випадкової дискретної величини називається сума добутків окремих значень, що їх набуває на їх, відповідні ймовірності.
Нехай дано ряд розподілу дискретної випадкової величини:
Таблиця 6.1.
| Х |
Х1 |
Х2 |
..... |
Хп |
| Р |
Р1 |
Р2 |
..... |
Рп |
Позначивши математичне сподівання через Е(х) за означенням, дістанемо:
![]() (6.7)
(6.7)
Математичне сподівання часто називають центром розподілу або центром розсіяння . Математичне сподівання випадкової величини дорівнює середній їй, значень зваженій за ймовірностями:
![]()
ПРИКЛАД.
Дано розподіл кількості написаних знаків за 5 хв. певною групою студентів (табл.6.2).Визначити математичне сподівання (середню кількість знаків, що їх може написати студент за 5 хв.) кількості написаних знаків:
Таблиця 6.2
| Кількість написаних знаків за 5 хв. |
230 |
254 |
262 |
274 |
281 |
282 |
285 |
302 |
307 |
308 |
| Імовірність Рі |
0,075 |
0,125 |
0,025 |
0,075 |
0,175 |
0,25 |
0,025 |
0,10 |
0,10 |
0,05 |
| Хі * Рі |
17,25 |
31,75 |
6,55 |
20,55 |
49,175 |
70,50 |
7,125 |
30,2 |
30,7 |
15,40 |
РОЗВ’ЯЗАННЯ
Математичне сподівання визначається за формулою 6.7.
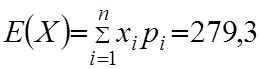
Отже, в середньому один студент за 5 хв. напише 279 знаків.
Математичне сподівання неперервної випадкової величини визначається за формулою:
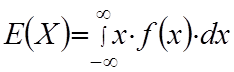 (6.8)
(6.8)
де f(x)--функція щільності розподілу iмовірностей.
Властивості математичного сподівання :
- Математичне сподівання сталої величини дорівнює цій самій сталій :
E(a) = a (6.9)
- Сталий множник можна виносити за знак математичного сподівання:
E(cX) = cE(X) (6.10)
- Математичне сподівання алгебраїчної суми випадкових величин дорівнює алгебраїчній сумі їх математичних сподівань:
E(X±Y±Z±…±W)=E(X)±E(Y)±E(Z)±…±E(W) (6.11)
- Математичне сподівання добутку незалежних випадкових величин дорівнює добутку їх математичних сподівань:
E(XY)=E(X)*E(Y) (6.12)
- Математичне сподівання випадкової величини завжди обмежене найбільшим і найменшим її значеннями :
xmin E(X) xmax (6.13)
6.3 Дисперсія
Другою важливою характеристикою випадкової величини є дисперсія , яка характеризує ступінь розсіяння значень випадкової величини навколо її середньої. Математичне сподівання квадрата відхилення випадкової величини від її математичного сподівання називається дисперсією і позначається через D(x) або 2 .
Для дисперсії випадкової величини дисперсія обчислюється за формулою:
![]()
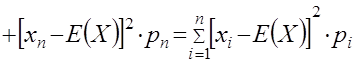 (6.14)
(6.14)
Дисперсія має такі основні властивості :
- Дисперсія сталої величини дорівнює нулю. Справді, нехай X=c. Тоді:
D(X)=D(c)=E(c-c)2 =E(c-c)2 =0 (6.15)
через те що середнє значення сталої величини дорівнює самій сталій.
- Сталий множник можна винести за знак дисперсії. При цьому його треба піднести до квадрата:
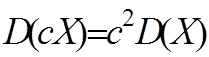 (6.16)
(6.16)
- Дисперсія суми кількох незалежних випадкових величин дорівнює сумі їх, дисперсій:
![]() (6.17)
(6.17)
- Дисперсія випадкової величини дорівнює середньому значенню її квадрата мінус квадрат її середнього значення:
![]() (6.18)
(6.18)
Величина
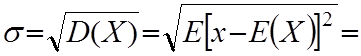
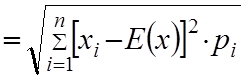 (6.19)
(6.19)
називається середнім квадратичним відхиленням і є мірою для характеристики ступеня розсіяння випадкової величини.
ПРИКЛАД
За даними прикладу попереднього параграфа ( табл.6.2) обчислити дисперсію та середнє квадратичне відхилення.
РОЗВ’ЯЗАННЯ
Дисперсію обчислюємо за формулою ( 6.14 ) :
2 =(230-279)2 0,075+ (254-279)2 0,125+ (262-279)2 0,25+ (274- -279)2 0,075+ (281-279)2 0,175+ (282-279)2 0,25+ (285-279)2 0,025+ +(302-279)2 0,1+ (307-279)2 0,1+ (308-279)2 0,05=444
Середнє квадратичне відхилення обчислюємо за формулою ( 6.19 ) :
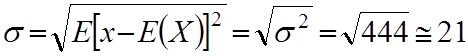
За міру розсіяння можна взяти модуль імовірностей , який визначається за формулою:
![]() (6.20)
(6.20)
Інколи розсіяння нормальної кривої характеризують мірою точності , яка є оберненою величиною до модуля ймовірностей:
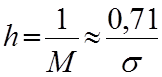 (6.21)
(6.21)
Для великої вибірки і нормального закону розподілу загальною оціночною характеристикою вимірювання є дисперсія й коефіцієнт варіації .
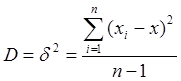 ,
, 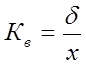 (6.22)
(6.22)
Дисперсія характеризує однорідність вимірювання. Чим вище Д, тим більший розкид вимірів. Коефіцієнт варіації характеризує мінливість. Чим вище Кв, тим більша мінливість вимірювань відносно середніх значень. Кв оцінює також розкид при оцінюванні декількох вибірок.
В цій задачі можливий другий варіант. На основі визначених даних встановлена певна (надійна) ймовірність Рд . Дуже часто її приймають рівною 0,9; 0,95; 0,9973. Необхідно встановити точність вимірювання, тобто надійний інтервал 2µ.
Так як 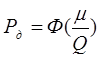 , то по таблиці можна визначити половину надійного інтервалу:
, то по таблиці можна визначити половину надійного інтервалу:
![]() (6.23),
(6.23),
де Ф(Рд ) – аргумент функції Лапласа, або при n10 Стьюдента (табл. 6.2). Надійний інтервал характеризує точність вимірювання даної вибірки, а надійна ймовірність – вірогідність вимірювання.
Приклад.
Виконано 30 вимірювань міцності одежи ділянки автомобільної дороги. При цьому середній модуль пружності одежи Еэ
=170 МПа. Визначене значення середньоквадратичного відхилення є ![]() =3.1 МПа. Визначити точність і вірогідність експерименту.
=3.1 МПа. Визначити точність і вірогідність експерименту.
Точність вимірювання визначаємо для різних рівнів вірогідної ймовірності, прийнявши, відповідно значення argФ(t) із таблиці 6.1: Рд
=0,9; 0,95; 0,9973; µ=![]() ;
;
µ=![]() ;
;
µ=![]() МПа.
МПа.
Отже для даного засобу і методу надійний інтеграл зростає приблизно в два рази, якщо Рд
збільшити тільки на 10%. Необхідно визначити вірогідність вимірів для встановленого надійного інтервалу, наприклад ![]() за формулою (6.5)
за формулою (6.5) ![]() .
.
За табл. 6.1 для 2.26 визначаємо ![]() . Це означає, що в заданий надійний інтервал із 100 вимірювань не попадає тільки три.
. Це означає, що в заданий надійний інтервал із 100 вимірювань не попадає тільки три.
Значення 1 - Ф(t) називають рівнем значності . Із нього виходить, що при нормальному законі розподілу похибка, яка перевищує надійний інтервал, буде зустрічатися один раз із nи вимірів:
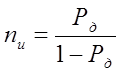 (6.24)
(6.24)
або вибірковувати одне із nи вимірів.
Встановлення мінімальної кількості вимірів.
Всі експериментальні дослідження в техніці базуються на вимірах. Задача зводиться до встановлення мінімального, але достатнього об’єму вибірки (числа вимірювань) Nmin
при заданих значеннях надійного інтервалу ![]() і надійної ймовірності. При виконанні вимірювання необхідно знати їх точність , яку характеризують 0
– середньоарифметичне значення середньоквадратичного відхилення
і надійної ймовірності. При виконанні вимірювання необхідно знати їх точність , яку характеризують 0
– середньоарифметичне значення середньоквадратичного відхилення ![]() :
:
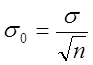 ;
; 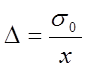 (6.25)
(6.25)
![]() - середня помилка.
- середня помилка.
Надійний інтервал помилки вимірювання визначається аналогічно, як і для вимірювань ![]() . За допомогою t легко визначити надійну ймовірність помилки вимірювання з таблиці 6.1.
. За допомогою t легко визначити надійну ймовірність помилки вимірювання з таблиці 6.1.
В дослідженнях за заданою точністю і надійною ймовірністю визначають мінімальну кількість вимірювань, яка гарантує потрібні значення і Ф(t).
Аналогічно рівнянню (6.23) з урахуванням (6.25) запишемо
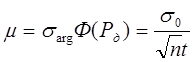 (6.26)
(6.26)
звідси, приймаючи ![]() Nmin
=n, будемо мати
Nmin
=n, будемо мати
![]()
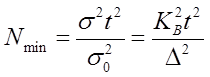 (6.27)
(6.27)
![]() - коефіцієнт варіації (мінливості), %;
- коефіцієнт варіації (мінливості), %;
D - точність вимірювання, %.
Для визначення ![]() можна прийняти таку послідовність:
можна прийняти таку послідовність:
1. Нехай n – кількість вимірів від 20 до 50, в залежності від складності дослідів.
2. Визначають середнє квадратичне відхилення m (6.21).
3. Встановлюють необхідну точність вимірювань m, D, яка повинна бути не менше точності приладу.
4. Установлюють нормативне відхилення t, значення якого задають, наприклад при великій точності вимірювань t=3.0, при малій – t=2.0, можна прийняти t=2.5.
5. Із (6.26) визначають ![]() . В процесі експерименту число вимірів не повинно бути менше
. В процесі експерименту число вимірів не повинно бути менше ![]() .
.
Приклад
при прийманні споруди, комісія в якості одного із параметрів, вимірює її ширину. Необхідно виконати 25 вимірів, допустиме відхилення параметра ![]() м. Необхідно визначити, з якою вірогідністю комісія оцінює даний параметр. Попереднє обчислення значення
м. Необхідно визначити, з якою вірогідністю комісія оцінює даний параметр. Попереднє обчислення значення ![]() м.
м.
Допустиме відхилення параметра ![]() м. з рівняння (6.27) запишемо
м. з рівняння (6.27) запишемо ![]() .
. ![]() ;
; ![]() . У відповідності з таблицею (6.). Надійна ймовірність для
. У відповідності з таблицею (6.). Надійна ймовірність для ![]()
![]() це низька ймовірність. Похибка перевищує надійний інтервал
це низька ймовірність. Похибка перевищує надійний інтервал ![]() м, згідно формули (6.) ,буде зустрічатися один раз із
м, згідно формули (6.) ,буде зустрічатися один раз із ![]() , тобто із чотирьох вимірювань. Це не допустимо. Вирахуємо мінімальну кількість вимірів, з надійною ймовірністю РД
, рівною 0,9 і 0,95. За формулою (6.27) маємо
, тобто із чотирьох вимірювань. Це не допустимо. Вирахуємо мінімальну кількість вимірів, з надійною ймовірністю РД
, рівною 0,9 і 0,95. За формулою (6.27) маємо ![]() виміри при РД
=0,90 і 64 виміри при РД
=0,95. Результати вимірювань за допомогою
виміри при РД
=0,90 і 64 виміри при РД
=0,95. Результати вимірювань за допомогою ![]() і
і ![]() справедливі при
справедливі при ![]() . Для знаходження границь надійного інтервалу при малих значеннях застосовують метод запропонований в 1908 році англійським математиком
. Для знаходження границь надійного інтервалу при малих значеннях застосовують метод запропонований в 1908 році англійським математиком
В.С. Гессетом (псевдонім Стьюдент). Криві розподілення Стьюдента у разі ![]() переходять в криві нормального розпреділення (рис. 6.1).
переходять в криві нормального розпреділення (рис. 6.1).
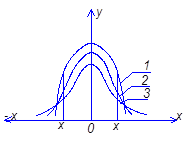
Для малої вибірки надійний інтервал
![]() (6.28)
(6.28)
де ![]() - коефіцієнт Стьюдента, який приймається з табл. 6.2 в залежності від значення надійної ймовірності Фст
знаючи mст
, можна визначити дійсне значення величини, що вивчається для малої вибірки:
- коефіцієнт Стьюдента, який приймається з табл. 6.2 в залежності від значення надійної ймовірності Фст
знаючи mст
, можна визначити дійсне значення величини, що вивчається для малої вибірки:
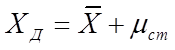 (6.29).
(6.29).
Можлива інша постановка задачі. Маючи n відомих вимірів малої вибірки необхідно визначити необхідну ймовірність РД
за умовою, що похибка середнього значення не вийде за межі ![]() .
.
Задачу розв’язують у такій послідовності:
1. Визначають середнє значення ![]() ,
, ![]() і
і ![]() .
.
2. За допомогою величини ![]() , відомого n і таблиці 6.2 визначають надійну ймовірність.
, відомого n і таблиці 6.2 визначають надійну ймовірність.
Інтегральна формула Лапласа
Надійним називається інтервал значень хі у який попадає правдиве значення хд величини, що вимірюється, попадає в даний інтервал.
Надійною ймовірністю ( вірогідністю) вимірювання називається імовірністю Рд того, що правдиве значення хд величини, що вимірюється попадає в даний надійний інтервал.
Ця величина визначається в долях одиниці або в процентах. Необхідно встановити ймовірність того, що хд попаде в зону аxд в. Надійна імовірність Рд описується виразом:
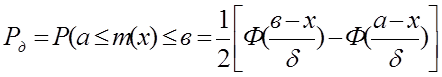 (6.30)
(6.30)
де Ф(t) – функція Лапласса, аргументом якої є відношення µ до середньоквадратичного , тобто
t=µ/ (6.31)
µ=b-x; µ= - (a-x), t – гарантований коефіцієнт.
Функція Ф(t) – це інтегральна функція Лапласа:
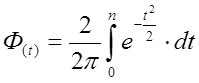 (6.32)
(6.32)
Її можна записати так:
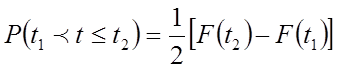 (6.33)
(6.33)
Числові значення Ф(t), приведені в додатку табл. I.
Коли задані межі появи події А(m1 i m2 ), які відрізняються від np на [x], то інтегральна формула Лапласа набуде такого вигляду:
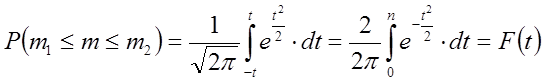 (6.34)
(6.34)
У цьому випадку:
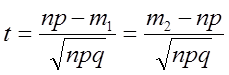 (6.35)
(6.35)
Застосовуючи інтегральну формулу Лапласа, слід врахувати, що функція Лапласа – непарна функція тобто, що:
F(-a)= -F(a)
Виходячи з того і взявши до уваги, що:
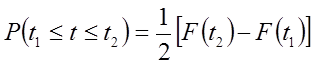 (6.36)
(6.36)
можна записати:
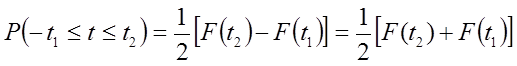 (6.37)
(6.37)
Отже функція Лапласа 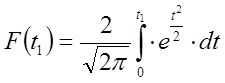 виражає ймовірність того, що випадкове відхилення t буде в межах –t1
t t1
. Величина цієї імовірності чисельно дорівнює площі між кривою Лапласа
виражає ймовірність того, що випадкове відхилення t буде в межах –t1
t t1
. Величина цієї імовірності чисельно дорівнює площі між кривою Лапласа 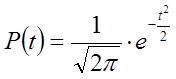 віссю ot і ординатою t=-t1; t=t1( 6.2 ).
віссю ot і ординатою t=-t1; t=t1( 6.2 ).
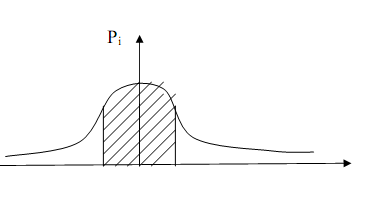
-t 0 t t
Щоб знайти ймовірність P(m1 m m2 ), треба:
1) визначити відхилення:
x1 =m1 -np i x2 =m2 -np;
2) знайти одиницю стандартного відхилення:
![]()
3) знайти величини:
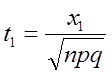
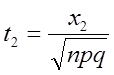
4) за таблицею (додаток 1) знайти:
F(t1 ) i F(t2 )
Після цього імовірність визначаємо за формулою ( 6.36 )
Інтервал ймовірностей широко використовується в розрахунках, що пов’язані із застосуванням методів вибірок, зокрема, коли треба:
1) оцінити результати вибірки з певною імовірністю;
2) визначити найменшу чисельність вибірки, яка забезпечує потрібну точність;
3) визначити границі відхилень генеральної середньої від вибіркової.
Метод виключення грубих помилок
При вимірюванні один із результатів різко відрізняється від інших, виникає підозра, що допущена груба помилка.
Позначимо значення, яке відрізняється від ряду інших вимірів – статистичного ряду –Х*
, а всі останні результати Х1
, Х2...
, Хn
, підрахуємо середнє арифметичне: 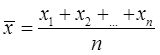 і порівняємо абсолютну величину різниці
і порівняємо абсолютну величину різниці
![]() х*
-
х*
- ![]() звеличиною
звеличиною 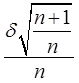 . Для отриманого відношення
. Для отриманого відношення
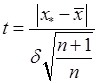
підрахуємо ймовірність 1-2Ф(t) за допомогою таблиці I (додаток I ). Може бути два випадки:
1). Якщо, відношення, що розглядається, буде мати значення не менше ніж t, при умові, що значення х* не має грубої помилки, що помилка результату х* є випадковою.
2).Якщо підрахована таким чином ймовірність буде дуже малою, то значення, яке “вискакує” має грубу помилку і його необхідно виключити з ряду. Яку ймовірність рахувати дуже малою, залежить від конкретних умов розв’язку задачі; якщо вибрати (призначити) дуже низький рівень малих ймовірностей, то грубі помилки можуть залишитися, якщо ж взяти цей рівень невизначено великим, то можна виключити результати із випадковими помилками, необхідними для правильної обробки результатів вимірювання. Взагалі приймають один з трьох рівнів малих ймовірностей:
- 5% рівень (виключаються помилки, ймовірність появи яких менше 0,05);
- 1% рівень (виключаються помилки, ймовірність появи яких менше 0,01);
- 0,1% рівень (виключаються помилки, ймовірність появи яких менше 0,001);
При вибраному рівні a малих ймовірностей, значення х*
, яке “вискакує” має грубу помилку, якщо для відповідного відношення t ймовірність ![]() , тоді підкреслюють, що х*
має грубу помилку з надійністю висновку
, тоді підкреслюють, що х*
має грубу помилку з надійністю висновку ![]() , значення
, значення ![]() , для якого
, для якого ![]() , і, значить,
, і, значить, ![]() , називається критичним значенням
відношення t при надійності Р. Так, якщо
, називається критичним значенням
відношення t при надійності Р. Так, якщо ![]() (1% рівень), то Р=0,99, критичне значення
(1% рівень), то Р=0,99, критичне значення ![]() (див. Додаток I), і як тільки відношення t перевищить це критичне значення, ми можемо бракувати (значення х*
, яке “вискакує” з надійністю висновка 0,99). Підкреслимо, що цей спосіб застосовується тоді, коли величина d середньої квадратичної помилки точно відома раніше.
(див. Додаток I), і як тільки відношення t перевищить це критичне значення, ми можемо бракувати (значення х*
, яке “вискакує” з надійністю висновка 0,99). Підкреслимо, що цей спосіб застосовується тоді, коли величина d середньої квадратичної помилки точно відома раніше.
Найбільш простий спосіб вилучення із статистичного ряду х* , яке різко виділяється є правило трьох сігм. Розкид випадкових величин від середнього значення не перевищує
хmax
,min
=![]() (6.38).
(6.38).
Більш вірогідний є метод, який базується на використанні надійного інтервалу. Нехай є статистичний ряд малої вибірки, який підчиняється закону нормального розподілу. При наявності грубих помилок критерій їх появи:
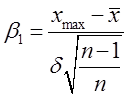 ;
; 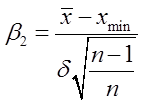 ; (6.39)
; (6.39)
де хmax , xmin найбільше і найменше значення із n вимірів.
В таблиці 6.3 наведенні максимальні значення ![]() , які виникають внаслідок статистичного розкиду. Якщо
, які виникають внаслідок статистичного розкиду. Якщо ![]() , то значення
, то значення ![]() необхідно виключити із статистичного ряду, як грубу помилку. При
необхідно виключити із статистичного ряду, як грубу помилку. При ![]() виключається величина
виключається величина ![]() . Після виключення грубих помилок визначають нові значення
. Після виключення грубих помилок визначають нові значення ![]() і
і ![]() із
із ![]() або
або ![]() вимірів.
вимірів.
Таблиця 6.3
| n |
bmax при Рд |
n |
bmax при Рд |
|||||
| 0.90 |
0.95 |
0.99 |
|
0.95 |
0.99 |
|||
| 3 4 5 6 7 8 9 10 11 12 13 14 |
1.41 1.64 1.79 1.89 1.97 2.04 2.10 2.15 2.19 2.23 2.26 2.30 |
1.41 1.69 1.87 2.00 2.09 2.17 2.24 2.29 2.34 2.39 2.43 2.46 |
1.41 1.72 1.96 2.13 2.26 2.37 2.46 2.54 2.61 2.66 2.71 2.76 |
15 16 17 18 19 20 25 30 35 40 45 50 |
2.33 2.35 2.38 2.40 2.43 2.45 2.54 2.61 2.67 2.72 2.76 2.8 |
2.49 2.52 2.55 2.58 2.60 2.62 2.72 2.79 2.85 2.90 2.95 2.99 |
2.80 2.84 2.87 2.90 2.93 2.96 3.07 3.16 3.22 3.28 3.33 3.37 |
|
Третій спосіб: задається надійна ймовірність РД
із таблиці 6.4 в залежності від ![]() знаходять коефіцієнт q. Визначають гранично допустиму абсолютну похибку окремого виміру
знаходять коефіцієнт q. Визначають гранично допустиму абсолютну похибку окремого виміру
![]() (6.40).
(6.40).
Якщо ![]() , то
, то ![]() виключається. Визначають відносну похибку результатів серії вимірювань при заданій надійній ймовірності РД
;
виключається. Визначають відносну похибку результатів серії вимірювань при заданій надійній ймовірності РД
;
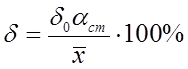 (6.41)
(6.41)
![]() - коефіцієнт Стьюдента.
- коефіцієнт Стьюдента.
Якщо похибка серії вимірювань сумісна з похибкою приладу Впр , то границі надійного інтегралу
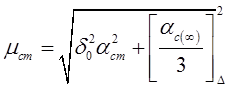 (6.42)
(6.42)
Таблиця 6.4
| Значення q при РД |
||||
| n |
0.95 |
0.98 |
0.99 |
0.995 |
| 2 3 4 5 6 7 8 9 10 12 14 16 18 20 |
4.97 3.56 3.04 2.78 2.62 2.51 2.43 2.37 2.29 2.24 2.20 2.17 2.15 |
38.97 8.04 5.08 4.10 3.64 3.36 3.18 3.05 2.96 2.83 2.14 2.68 2.64 2.60 |
77.96 11.46 6.53 5.04 4.36 3.96 3.71 3.54 3.41 3.23 3.12 3.04 3.00 2.93 |
779.7 36.5 14.46 9.43 7.41 6.37 5.73 5.31 5.01 4.62 4.37 4.20 4.07 3.93 |
Формулою (6.35) слід користуватися при ![]() . Якщо ж
. Якщо ж ![]() , то надійний інтервал визначають за допомогою формул (6.31).
, то надійний інтервал визначають за допомогою формул (6.31).
Приклад
Для визначення якості знань студентів з даної дисципліни, дають контрольні роботи 120 студентам. Імовірність виконання контрольної роботи на “відмінно” становить 0,3. яка імовірність того, що контрольні роботи напишуть на відмінно:
а)Не менше як 25 і не більше як 46 студентів;
б)Не менше як 50?
Розв’язання.
Дано:
а) p=0,3; m1 =25; m2 =46; n=120.
б) p=0,3; m1 =50; m2 =120; n=120.
а) x1 =m1 -np=25-120*0,3=25-36= -9
x2 =m2 -np=46-120*0,3=46-36=10
![]()
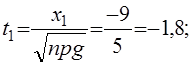
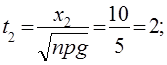
![]()
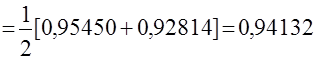
б) x1 =m1 -np=50-120*0,3=50-36= 14
x2 =m2 -np=120-120*0,3=120-36=84
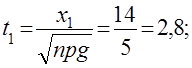
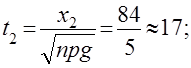
![]()
Тобто, майже неможливо, щоб більше 50 студентів написали контрольну роботу на “відмінно” за даних умов.