Статистика вивчення продуктивності великої рогатої худоби
СОДЕРЖАНИЕ: КУРСОВА РОБОТА на тему «СТАТИСТИКА ВИВЧЕННЯ ПРОДУКТИВНОСТІ ВЕЛИКОЇ РОГАТОЇ ХУДОБИ» Вступ Термін «статистика» походить від латинського «status», що означає положення, стан явищ. Від кореня цього слова виникли слова «stato» (держава), «statista» (статистик, знавець держави), «statistiks» (статистика – певна сума знань, зведень про державу).КУРСОВА РОБОТА
на тему
«СТАТИСТИКА ВИВЧЕННЯ ПРОДУКТИВНОСТІ ВЕЛИКОЇ РОГАТОЇ ХУДОБИ»
Вступ
Термін «статистика» походить від латинського «status», що означає положення, стан явищ. Від кореня цього слова виникли слова «stato» (держава), «statista» (статистик, знавець держави), «statistiks» (статистика – певна сума знань, зведень про державу). Цей термін існує століття, хоч зміст його неодноразово змінювався. У науковій літературі словом «статистика» користуються з XVIII ст. за змістом як державознавство. Проте статистика почала свій розвиток значно раніше – в середині XVII ст.
Нині термін «статистика» використовують у кількох значеннях:
1) це – дані, які характеризують масові суспільні явища;
2) процес збирання, зберігання і оброблення даних про масові суспільні явища, тобто галузь практичної діяльності, спрямованої на одержання, оброблення, аналіз і видання масових даних про явища і процеси суспільного життя;
3) це наука, яка вивчає величину, розміри і кількісну сторону масових суспільних явищ у нерозривному звязку з якісною стороною цих явищ, з їх соціально-економічним змістом.
Наукова система статистики складається із статистичної теорії, статистичної методології та зведених результатів статистичних досліджень.
Статистична теорія являє собою загальне вчення про розміри суспільних явищ і статистичних показників, які їх характеризують. Вона включає також вивчення звязків між статистичними показниками розвитку, змін змісту і форми статистичних показників.
Статистична методологія – це сукупність статистичних методів дослідження. Вона розробляє питання збирання зведень про розміри суспільних явищ, вивчення звязків між величинами та динаміки, принципів і прийомів аналізу статистичних даних. Статистична наука являє собою нерозривну єдність статистичної теорії і статистичної методології.
Зведені результати статистичних досліджень – це сукупність конкретних науково обґрунтованих статистичних даних (наприклад, показники кількості тварин за їх видами на певну дату, показники обсягу продукції тваринництва за певний рік і т. д.).
У процесі розвитку статистики як самостійної науки в її складі виділилися: математична статистика, загальна теорія статистики, соціально-економічна статистика, галузеві статистики.
Математична статистика – це галузь математичних знань. Вона розробляє раціональні прийоми (способи) систематизації, обробки і аналізу даних статистичних спостережень масових явищ з метою встановлення характерних для них статистичних закономірностей, використання для наукових і практичних висновків. У математичній статистиці більшість методів обробки статистичних даних ґрунтується на імовірнісній природі цих даних. Галузь застосування таких статистичних методів обмежується вимогами, щоб явища, які досліджуються, були підпорядковані достатньо визначеним імовірнісним закономірностям. Математична статистика абстрагується від матеріального змісту масових явищ, які вона характеризує, озброює дослідника математичним апаратом. Найважливіші розділи математичної статистики: статистичні ряди розподілу, оцінка параметрів розподілу, закони розподілу вибіркових характеристик, перевірка статистичних гіпотез, дисперсійний, кореляційно-регресійний, коваріаційний аналіз. Математична статистка виконує роль основи для застосування власне математичних методів, які являють собою інструментарій статистичної науки.
Загальна теорія статистики містить принципи статистичної науки стосовно річних сторін суспільного життя, тобто загальні правила і методи статистичного дослідження. Вона розробляє понятійний апарат статистичної науки, систему категорій, розглядає у загальному вигляді методи збирання, зведення, узагальнення і аналізу статистичних даних. Предметом пізнання загальної теорії статистики є найбільш загальні властивості кількісних відносин соціально-економічних явищ. У складі її вивчаються такі найважливіші розділи: статистичне спостереження, статистичне групування, середні величини, вибіркове спостереження, ряди динаміки, індекси статистичні графіки. Показники і методи загальної теорії статистики використовуються всіма іншими галузями статистики.
Соціальна статистика – галузь статистики, яка вивчає кількісну і якісну сторони масових суспільних явищ і процесів, що відбуваються в соціальному житті, і розробляє інтегровану систему показників здійснення соціальних процесів і явищ.
Економічна статистика як галузь єдиної статистичної науки, спираючись на положення загальної теорії статистики, вивчає кількісну сторону масових суспільних явищ і процесів у сфері матеріального виробництва з метою виявлення пропорцій тенденцій і закономірностей їх розвитку. Економічна статистика досліджує всю економіку країни, даючи їй числову характеристику.
Галузеві статистики вивчають показники процесу виробництва в га-лузях матеріального виробництва (сільському господарстві, промисловості), в галузях, де продовжується процес виробництва у сфері обігу (торгівля, звязок, транспорт тощо); показники роботи галузей невиробничої сфери (житлово-комунального господарства, науки, фізичної культури і спорту тощо).
Метою дійсної курсової роботи є проведення статистичного аналізу показників продуктивності ВРХ в сільському господарств.
Об’єктом статистичного аналізу є умовна вибірка показників продуктивності ВРХ по варіанту №72.
Предметом статистичного аналізу дійсної курсової роботи є виявлення статистичних закономірностей між результативною ознакою – надоями молока та факторними ознаками – кількістю затрачених кормів на годування ВРХ та кількістю народжених телят, як умови продовження періодичного процесу лактації молока у ВРХ.
1. Система показників статистики тваринництва
1.1 Методологія розрахунку основних показників статистики тваринництва в сегменті великої рогатої худоби (ВРХ)
Продукція тваринництва поділяється на дві групи:
1) продукція нормальної життєдіяльності тварин, реалізація якої для вживання за межами тваринництва не повязана з забоєм (ліквідуванням) самих тварин (молоко, вовна, яйця, мед і т. п.). У створенні цієї продукції тварини виступають в якості засобів праці;
2) продукція приплоду і приросту, або продукція вирощування тварин. Реалізація цієї продукції за межами тваринництва пропонує забій тварин. Використання цієї продукції вирощування тварин для відтворення стада повязано з подальшим його залишенням в сфері тваринництва. Таким чином, тварини, які ростуть чи відгодовуються, виступають як повязані у виробництві предмети праці, або інакше, незавершене виробництво мясного контингенту, а також тварин основного стада. Вирощена доросла худоба, племінна, представляє собою закінчену готову продукцію, яка використовується в ролі засобів праці.
Загальний обсяг продукції тваринництва визначається кількістю одержаного приплоду і обсягом приросту вирощеного за рік молодняка худоби, приросту дорослої худоби, одержаного в результаті її відгодівлі, а також кількості молока, вовни, яєць та іншої продукції тваринництва, одержаної у процесі господарського використання худоби та птиці, непов’язаної з її забоєм, облікованою у порівнянних цінах.
Виробництво молока характеризується фактично надоєним коров’ячим, овечим, козиним молоком, незалежно від того, чи було воно реалізовано, чи частина його використана у господарстві на випоювання телят і поросят. Молоко, яке висмоктане телятами при їх підсосному утриманні у виробництво молока не включається.
Середньорічний надій молока від однієї корови наводиться у розрахунку на поголів’я корів на початок року, незалежно від того, чи доїлась корова у даному періоді. У сільськогосподарських підприємствах при визначенні надою молока від однієї корови із загального поголів’я корів у господарстві виключаються корови, що перебувають на відгодівлі, корови м’ясного стада, а також корови, призначені для групового та підсосного утримання телят, якщо ці корови не доїлись.
Молочна продуктивність корів характеризується середньою удійністю корів. Обчислюють два показники: середній надій на одну дійну корову і середній надій від однієї корови молочного стада. Якщо середній надій на одну дійну корову характеризує середній рівень молочної продуктивності корів, то середній надій від однієї корови молочного стада визначає одночасно ступінь використання корів для виробництва молока та рівень їх молочної продуктивності.
До дійних корів належать корови, що за звітний період дали приплід та доїлися у звітному періоді. Ялові корови, що доїлися, до дійних не відносяться.
Основним показником продуктивності корів є другий показник – середньорічний надій молока від однієї корови молочного стада, який ї є основним показником вихідних даних у дійсній курсовій роботі.
1.2 Основні статистичні показники продуктивності ВРХ в Україні у 2006–2007 роках
В табл. 1.1 – 1.3 наведені основні показники тваринництва та продуктивності корів по надою молока в Україні за даними Державного комітету статистики України.
Таблиця 1.1. Тваринництво
| Поголів’я худоби та птиці на 1 січня, тис. голів | |||||
| велика рогата худоба | свині | вівці та кози | птиця, млн. голів | ||
| всього | у т. ч. корови | ||||
| 1990 | 25194,8 | 8527,6 | 19946,7 | 9003,1 | 255,1 |
| 1991 | 24623,4 | 8378,2 | 19426,9 | 8418,7 | 246,1 |
| 1992 | 23727,6 | 8262,6 | 17838,7 | 7829,1 | 243,1 |
| 1993 | 22456,8 | 8057,2 | 16174,9 | 7236,6 | 214,6 |
| 1994 | 21607,3 | 8077,7 | 15298,0 | 6862,6 | 190,5 |
| 1995 | 19624,3 | 7818,3 | 13945,5 | 5574,5 | 164,9 |
| 1996 | 17557,3 | 7531,3 | 13144,4 | 4098,6 | 149,7 |
| 1997 | 15313,2 | 6971,9 | 11235,6 | 3047,1 | 129,4 |
| 1998 | 12758,5 | 6264,8 | 9478,7 | 2361,8 | 123,3 |
| 1999 | 11721,6 | 5840,8 | 10083,4 | 2026,0 | 129,5 |
| 2000 | 10626,5 | 5431,0 | 10072,9 | 1884,7 | 126,1 |
| 2001 | 9423,7 | 4958,3 | 7652,3 | 1875,0 | 123,7 |
| 2002 | 9421,1 | 4918,1 | 8369,5 | 1965,0 | 136,8 |
| 2003 | 9108,4 | 4715,6 | 9203,7 | 1984,4 | 147,4 |
| 2004 | 7712,1 | 4283,5 | 7321,5 | 1858,8 | 142,4 |
| 2005 | 6902,9 | 3926,0 | 6466,1 | 1754,5 | 152,8 |
| 2006 | 6514,1 | 3635,1 | 7052,8 | 1629,5 | 162,0 |
| 2007 | 6175,4 | 3346,7 | 8055,0 | 1617,2 | 166,5 |
Таблиця 1.2. Виробництво продукції тваринництва в Україні
| Виробництво продукції тваринництва | ||||
| м’ясо усіх видів (у забійній вазі), тис. т | молоко, млн. т | яйця, млн. шт. | вовна, тис. т | |
| 1990 | 4357,8 | 24,5 | 16286,7 | 29,8 |
| 1991 | 4029,1 | 22,4 | 15187,8 | 26,6 |
| 1992 | 3400,9 | 19,1 | 13496,0 | 23,1 |
| 1993 | 2814,5 | 18,4 | 11793,8 | 21,1 |
| 1994 | 2677,4 | 18,1 | 10153,7 | 19,3 |
| 1995 | 2293,7 | 17,3 | 9403,5 | 13,9 |
| 1996 | 2112,7 | 15,8 | 8763,3 | 9,3 |
| 1997 | 1874,9 | 13,8 | 8242,4 | 6,7 |
| 1998 | 1706,4 | 13,8 | 8301,4 | 4,6 |
| 1999 | 1695,3 | 13,4 | 8739,7 | 3,8 |
| 2000 | 1662,8 | 12,7 | 8808,6 | 3,4 |
| 2001 | 1517,4 | 13,4 | 9668,2 | 3,3 |
| 2002 | 1647,9 | 14,1 | 11309,3 | 3,4 |
| 2003 | 1724,7 | 13,7 | 11477,1 | 3,3 |
| 2004 | 1599,6 | 13,7 | 11955,0 | 3,2 |
| 2005 | 1597,0 | 13,7 | 13045,9 | 3,2 |
| 2006 | 1723,2 | 13,3 | 14234,6 | 3,3 |
Таблиця 1.3. Темпи виробництва валової продукції сільського господарства за 2004–2006 роки
| 2004 рік | 2005 рік | 2006 рік | |
| Валова продукція сільського господарства | |||
| (у порівняних цінах 2000 року) | |||
| всі категорії господарств | 119,7 | 99,9 | 100,4 |
| в т.ч.: рослинництво | 133,6 | 97,3 | 98,7 |
| тваринництво | 100,9 | 104,5 | 103,5 |
Таблиця 1.4. Виробництво основних продуктів тваринництваза січень-вересень 2007 року
| Реалізовано на забій худоби та птиці (у живій вазі) | Молоко | Яйця всіх видів | ||||
| тис. т | у% до січня-вересня 2006 р. | тис. т | у% до січня-вересня 2006 р. | млн. шт. | у% до січня-вересня 2006 р. | |
| Україна | 1871,6 | 109,8 | 9719,4 | 92,8 | 10972,3 | 98,1 |
| Автономна Республіка Крим | 134,5 | 111,6 | 267,8 | 103,4 | 463,5 | 98,0 |
| Вінницька | 70,2 | 117,2 | 632,6 | 97,8 | 526,3 | 101,7 |
| Волинська | 70,4 | 112,5 | 405,2 | 94,0 | 166,4 | 87,9 |
| Дніпропетровська | 144,1 | 116,0 | 325,2 | 87,6 | 687,5 | 94,2 |
| Донецька | 95,7 | 111,4 | 331,5 | 85,0 | 990,8 | 90,7 |
| Житомирська | 50,6 | 89,4 | 521,2 | 87,1 | 382,1 | 91,1 |
| Закарпатська | 44,8 | 99,6 | 321,4 | 100,5 | 244,6 | 99,8 |
| Запорізька | 66,3 | 117,1 | 249,1 | 87,2 | 465,6 | 92,8 |
| Івано-Франківська | 63,8 | 106,7 | 416,8 | 95,0 | 438,0 | 113,6 |
| Київська | 212,7 | 112,5 | 418,7 | 88,5 | 1320,2 | 104,1 |
| Кіровоградська | 47,0 | 106,6 | 295,5 | 95,5 | 271,9 | 107,0 |
| Луганська | 46,5 | 103,6 | 279,5 | 92,6 | 469,3 | 92,4 |
| Львівська | 101,6 | 110,7 | 668,0 | 91,1 | 455,8 | 98,4 |
| Миколаївська | 32,8 | 114,3 | 301,3 | 90,6 | 257,9 | 101,9 |
| Одеська | 69,1 | 120,4 | 374,8 | 87,8 | 437,8 | 85,0 |
| Полтавська | 54,7 | 122,6 | 529,7 | 90,7 | 419,0 | 94,6 |
| Рівненська | 56,0 | 109,4 | 377,7 | 95,7 | 284,6 | 106,7 |
| Сумська | 42,5 | 77,6 | 367,9 | 92,6 | 270,1 | 80,8 |
| Тернопільська | 40,3 | 106,1 | 362,9 | 97,3 | 314,8 | 94,7 |
| Харківська | 87,0 | 97,2 | 378,8 | 90,7 | 623,1 | 95,1 |
| Херсонська | 52,3 | 112,2 | 254,4 | 93,0 | 204,3 | 100,0 |
| Хмельницька | 49,8 | 106,4 | 508,2 | 93,1 | 281,3 | 170,3 |
| Черкаська | 143,5 | 122,6 | 406,4 | 98,4 | 492,4 | 103,5 |
| Чернівецька | 38,4 | 110,0 | 262,3 | 95,1 | 256,1 | 117,2 |
| Чернігівська | 57,0 | 104,0 | 462,5 | 95,8 | 248,9 | 89,9 |
Таблиця 1.5. Виробництво основних продуктів тваринництва за січень-грудень 2006 року
| Реалізовано на забій худоби та птиці (у живій вазі) | Молоко | Яйця всіх видів | ||||
| тис. т | у% до січня–грудня 2005 р. | тис. т | у% до січня–грудня 2005 р. | млн. шт. | у% до січня–грудня 2005 р. | |
| Україна | 2547,0 | 106,6 | 13269,8 | 96,8 | 14228,0 | 109,1 |
| Автономна Республіка Крим | 164,5 | 104,7 | 322,6 | 93,0 | 602,4 | 103,5 |
| Вінницька | 95,0 | 123,2 | 851,6 | 100,3 | 639,5 | 112,2 |
| Волинська | 97,0 | 108,9 | 544,3 | 98,9 | 213,1 | 97,0 |
| Дніпропетровська | 183,9 | 114,3 | 474,4 | 96,0 | 974,7 | 110,6 |
| Донецька | 144,4 | 109,6 | 476,3 | 92,6 | 1442,0 | 103,8 |
| Житомирська | 76,0 | 108,9 | 727,9 | 99,5 | 502,0 | 113,9 |
| Закарпатська | 74,1 | 100,7 | 395,0 | 99,8 | 289,0 | 96,8 |
| Запорізька | 81,5 | 106,1 | 375,9 | 97,9 | 659,1 | 118,3 |
| Івано-Франківська | 92,6 | 105,8 | 570,1 | 98,9 | 505,2 | 145,5 |
| Київська | 272,8 | 118,2 | 612,0 | 88,3 | 1705,3 | 116,6 |
| Кіровоградська | 62,5 | 95,4 | 389,9 | 98,7 | 297,9 | 105,2 |
| Луганська | 65,5 | 94,2 | 371,4 | 90,8 | 656,9 | 107,9 |
| Львівська | 137,1 | 110,6 | 893,2 | 96,0 | 563,7 | 102,8 |
| Миколаївська | 43,5 | 97,1 | 413,1 | 95,6 | 327,0 | 104,2 |
| Одеська | 74,4 | 91,5 | 535,0 | 88,2 | 616,4 | 90,1 |
| Полтавська | 68,2 | 113,3 | 799,8 | 106,1 | 573,5 | 106,6 |
| Рівненська | 70,8 | 104,3 | 499,4 | 99,5 | 331,0 | 100,9 |
| Сумська | 94,2 | 99,9 | 487,0 | 97,8 | 385,1 | 103,6 |
| Тернопільська | 62,2 | 97,8 | 469,7 | 96,8 | 384,6 | 132,6 |
| Харківська | 138,8 | 99,8 | 531,9 | 93,9 | 883,2 | 117,4 |
| Херсонська | 66,8 | 104,7 | 354,0 | 99,0 | 260,3 | 104,2 |
| Хмельницька | 75,1 | 98,4 | 689,0 | 95,4 | 219,2 | 113,3 |
| Черкаська | 162,3 | 110,6 | 515,2 | 99,3 | 614,2 | 114,9 |
| Чернівецька | 56,3 | 109,3 | 360,8 | 98,1 | 257,5 | 105,6 |
| Чернігівська | 87,5 | 101,3 | 610,3 | 96,3 | 325,2 | 90,7 |
2. Статистичні угрупування результатів спостережень за продуктивністю ВРХ
2.1 Результативна та факторні ознаки досліджуємої статистичної вибірки
Другою стадією статистичного дослідження є статистичне зведення і групування, оскільки після збору даних, ми повинні їх звести, згрупувати для обробки.
Зведення – це комплекс послідовних операцій по узагальненню конкретних поодиноких факторів, які утворюють сукупність, для виявлення типових рис і закономірностей, що належать досліджуваному явищу в цілому. Зведення може бути просте і складне .
Просте зведення – це простий підрахунок підсумків первинних статистичних даних.
Складне зведення передбачає групування, види групувальної ознаки, встановлення меж групування, підрахунок групових і узагальнюючих підсумків, а також викладення результатів зведення у вигляді таблиць чи графіків.
Одним із найважливіших методів статистики є групування. Під групуванням в статистиці розуміють розподіл одиниць статистичної сукупності на групи, однорідні в якому-небудь суттєвому відношенні.
Тому в статистиці групування використовується для вирішення різних завдань, таких як, наприклад:
- визначення і вивчення структури і структурних зрушень сукупності;
- виявлення соціально-економічних типів явищ і процесів;
- виявлення і характеризування звязків і залежностей між явищами та їх ознаками (таке дослідження має назву аналітичної функції групування).
Відповідно до цих трьох функцій розрізняють різні види групування: структурні, типологічні і аналітичні.
Групування, в результаті якого виділяють однорідні групи або типи явищ, як вираз конкретного суспільного процесу називаються типологічними.
Структурними групуваннями називаються групування, які характеризують розподіл одиниць однотипної сукупності за будь-якою ознакою. Типологічні і структурні групування дуже близькі один до одного: типологічні групування виділяють самі типи, а структурні – вказують питому вагу окремих типів у загальній масі.
Аналітичні групування – це групування, які визначають взаємозвязок між різними ознаками одиниць статистичної сукупності. За допомогою такого групування можна виявити певні взаємозвязки між факторними і результативними ознаками. Аналітичні групування є дуже складними і для того, щоб зрозуміти, як вони будуються, необхідно чітко виділити факторні і результативні ознаки в досліджуваному явищі.
Групування можуть бути прості і комбіновані . Прості групування – це такі групування, які здійснені на підставі однієї ознаки. Комбіновані групування – це групування, які здійснені за двома і більше ознаками.
Комбінаційні групування дають можливість комплексного характеризування досліджуваного явища чи процесу.
Для того, щоб зробити групування за кількісною ознакою, необхідно визначитися з кількістю груп та з інтервалом групування.
Величина інтервалу
![]() ,
,
де xmax максимальне значення, xmin – мінімальне значення, n – кількість груп сукупності.
Таблиця 2.1. Ранжування вибірки за першою факторною ознакою Xi
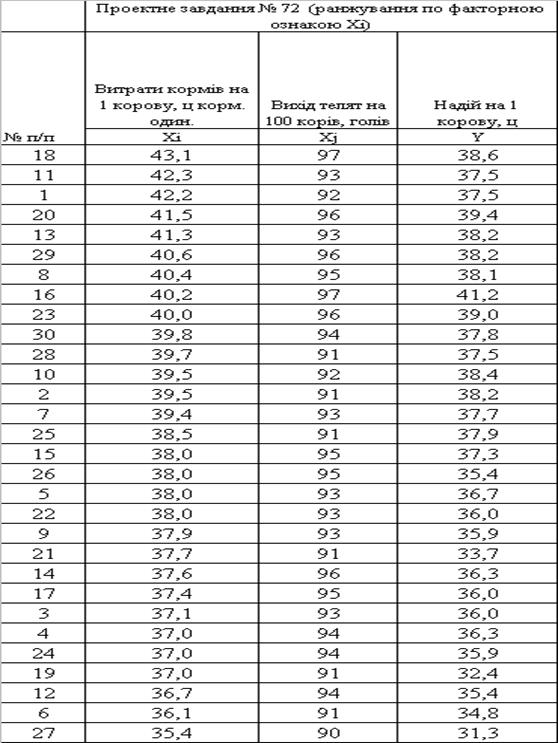
Таблиця 2.2. Ранжування вибірки за другою факторною ознакою Xj
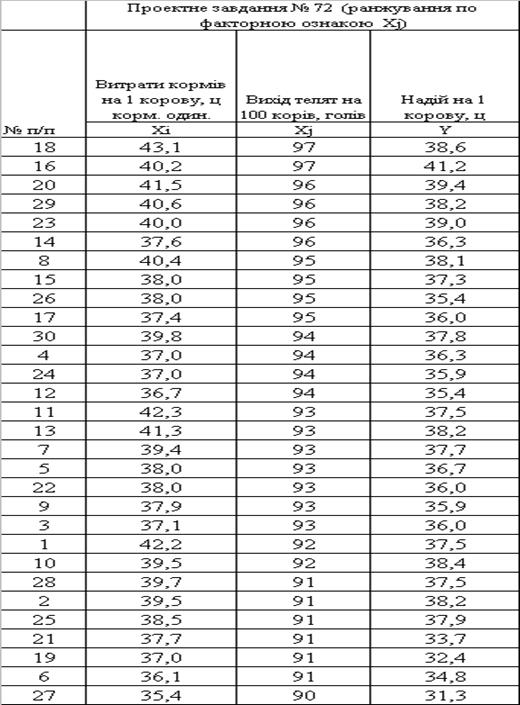
Таблиця 2.3. Ранжування вибірки за результативною ознакою Y
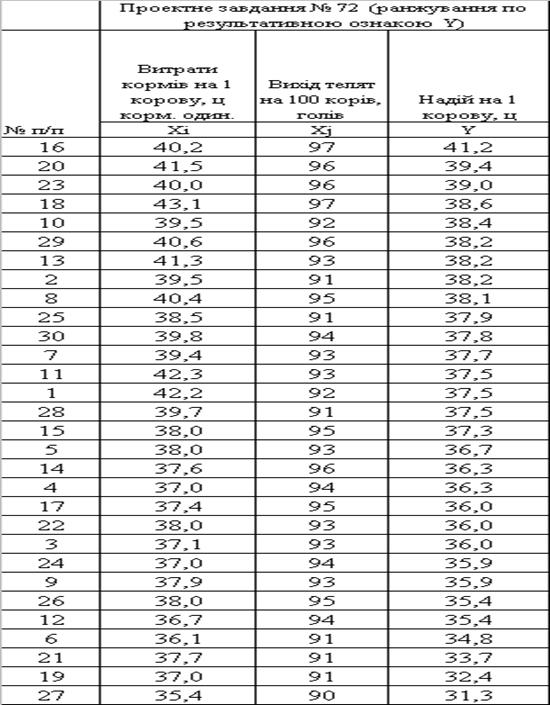
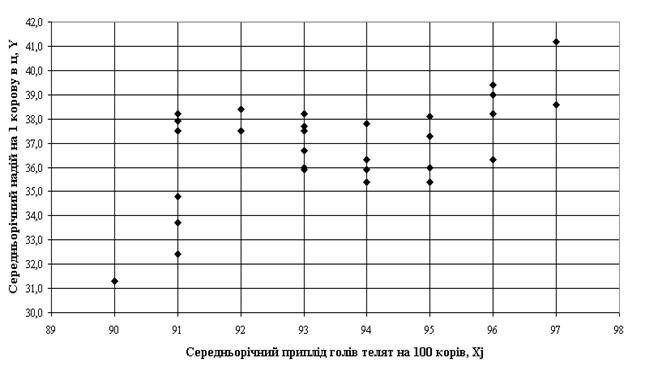
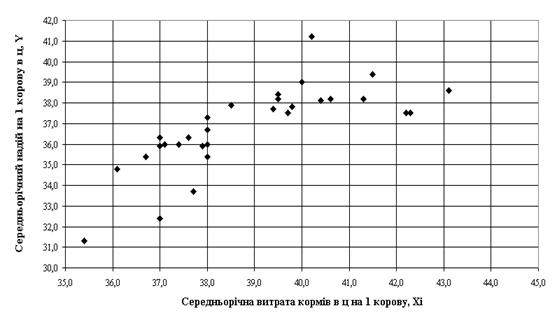
Рис. 2.1. – Попередній графічний аналіз функціональних зв’язків в ранжованих вибірках
2.2 Группування результативної та факторних ознак
Таблиця 2.4. Інтервальний варіаційний ряд розподілу результативної ознаки
| № групи | Групи за рівнем надою на 1 корову в ц | Частоти | Накопичувальні частоти |
| 1 | 31,3–33,8 | 3 | 3 |
| 2 | 33,8–36,3 | 8 | 11 |
| 3 | 36,3–38,7 | 16 | 27 |
| 4 | 38,7–41,2 | 3 | 30 |
| 30 |
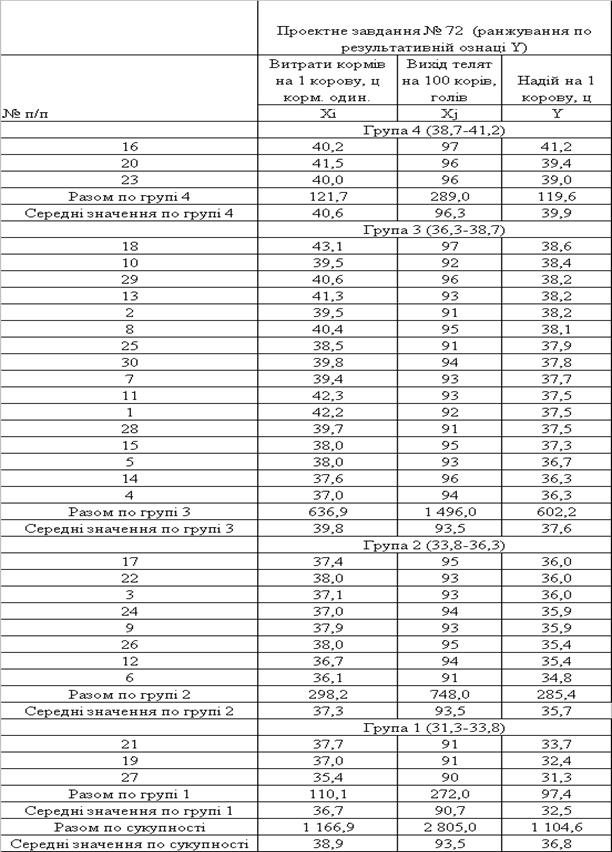
Таблиця 2.6. Показники середніх величин інтервалів группування
| Проектне завдання №72 (ранжування по результативній ознаці Y) | |||
| № п/п | Витрати кормів на 1 корову, ц корм. один. | Вихід телят на 100 корів, голів | Надій на 1 корову, ц |
| Xi | Xj | Y | |
| Група 4 (38,7–41,2) | |||
| Середні значення по групі 4 | 40,6 | 96,3 | 39,9 |
| Група 3 (36,3–38,7) | |||
| Середні значення по групі 3 | 39,8 | 93,5 | 37,6 |
| Група 2 (33,8–36,3) | |||
| Середні значення по групі 2 | 37,3 | 93,5 | 35,7 |
| Група 1 (31,3–33,8) | |||
| Середні значення по групі 1 | 36,7 | 90,7 | 32,5 |
| Середні значення по сукупності | 38,9 | 93,5 | 36,8 |
Таблиця 2.5. Розподіл вибірки на групи за інтервалами результативної ознаки
3 . Статистична оцінка продуктивності ВРХ та факторів, що на неї впливають
3.1 Ряди розподілу та їх графічне зображення (огіва, кумулята, гістограма, полігон)
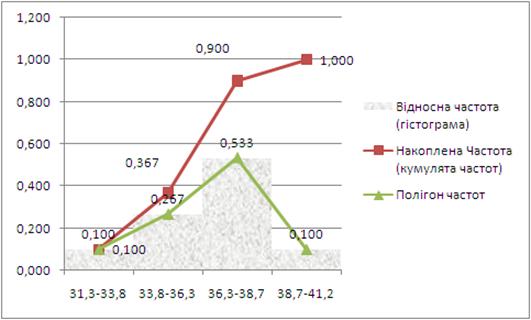
Рис. 3.1. – Графічне зображення статистичних показників розподілу в групах ряду результативної ознаки Y
3.2 Узагальнюючі показники рядів розподілу, прості та зважені середні величини
Середня величина – це узагальнюючі показник, які характеризують рівень варіруючої ознаки в якісно однорідній сукупності.
Сукупність, яку ми збираємося характеризувати середньою величиною повинна бути:
1) якісно однорідною, однотипною;
2) складатися з багатьох одиниць.
Середні величини можуть бути абсолютними або відносними залежно від вихідної бази. Середні можуть бути прості і зважені.
Найбільш простим видом середніх величин є середньоарифметична проста:
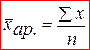 , (3.1)
, (3.1)
де n – кількість одиниць сукупності,
x – варіруюча ознака.
Вона застосовується в тому випадку, коли у нас варіруюча арифметична ознака має різні значення, і є незгруповані дані.
Якщо ж ми маємо згруповані дані, або варіруюча ознака зустрічається декілька раз, то застосовується середня арифметична зважена.
 , (3.2)
, (3.2)
де x – варіруюча ознака,
f – абсолютна кількість повторення варіруючої ознаки.
В табл. 3.1, використовуючи дані розрахунків табл. 2.4–2.5, наведені результати розрахунку середньозваженої середньої величини результативної ознаки Y – середньорічних надоїв молока на 1 корову.
Таблиця 3.1. Розрахунок зважених середніх, моди та медіани методом моментів
| № групи | Групи за рівнем надоїв на 1 корову, ц | Частоти f | Центр інтервалу групи Yk | Yk-Y4 | (Yk-Y4)/4 | (Yk-Y4)/4*f | Yk*f | |Y-Yср| | |Y-Yср|*f | |Y-Yср|^2 | |Y-Yср|^2*f |
| 1 | 31,3–33,8 | 3 | 32,47 | -7,40 | -1,85 | -5,55 | 97,40 | 4,35 | 13,06 | 18,95 | 56,85 |
| 2 | 33,8–36,3 | 8 | 35,68 | -4,19 | -1,05 | -8,38 | 285,40 | 1,15 | 9,16 | 1,31 | 10,49 |
| 3 | 36,3–38,7 | 16 | 37,64 | -2,23 | -0,56 | -8,92 | 602,20 | 0,82 | 13,08 | 0,67 | 10,69 |
| 4 | 38,7–41,2 | 3 | 39,87 | 0,00 | 0,00 | 0,00 | 119,60 | 3,05 | 9,14 | 9,28 | 27,85 |
| Разом | 30 | -22,85 | 1 104,60 | 44,44 | 105,88 | ||||||
| Момент першого порядку | -0,76 | ||||||||||
| Середня способом моментів | 36,82 | ||||||||||
| Середня арифметична зважена | 36,82 | ||||||||||
| Мода в 3 групі | 36,89 | ||||||||||
| Медіана в 3 інтервалі | 36,92 | ||||||||||
| Середнє лінійне відхилення | 1,48 | ||||||||||
| Дисперсія | 3,53 | ||||||||||
| Середнє квадратичне відхилення | 1,88 | ||||||||||
| Коефіцієнт варіації | 5,10 |
3.3 Мажорантність середніх показників та обчислення моди і медіани способом моментів
До середніх структурних відносяться дві величини, які називаються «мода» і «медіана».
Мода (модальна величина) ряду – це така величина, яка найбільш часто зустрічається в даному розподілі.
![]() (3.3)
(3.3)
x0 – це нижня межа модального інтервалу.
i – величина інтервалу.
f2 – частота модального інтервалу,
f1 – частота передмодального інтервалу (того, що передує
модальному)
f3 – частота позамодального інтервалу (того, що йде після модального
інтервалу)
Медіаною називається така величина, що займає серединне положення у варіаційному ряду, в якому варіанти розташовані в зростаючому або спадаючому порядку.
Для дискретного ряду
: ![]() (3.4)
(3.4)
Для варіаційного ряду:
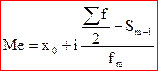 (3.5)
(3.5)
x0 – це нижня межа медіального інтервалу.
i – величина інтервалу.
Sm-1 – сума накопичених частот до медіанного інтервалу.
fm – частота медіанного інтервалу.
Структурні величини мода і медіана застосовуються для вивчення внутрішньої будови рядів розподілу, тобто їх структури.
В табл. 3.1 наведені результати розрахунків моди та медіани для вибірки результативної ознаки Y.
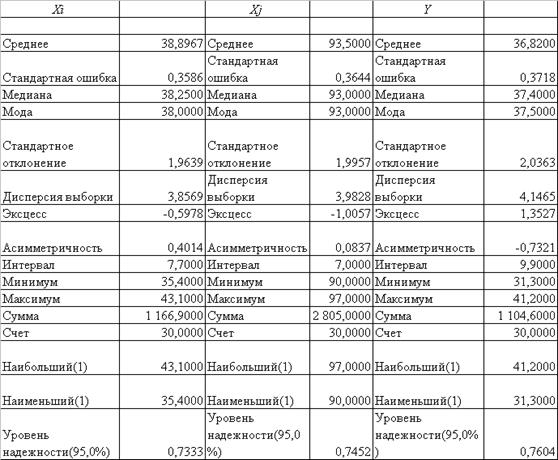
В табл. 3.2 наведені результати розрахунку показників рядів факторних та результативної ознаки за допомогою «електронних таблиць» Excel –2000 (вбудовані статистичні розрахунки).
Таблиця 3.2. Розрахунок показників рядів факторних та результативної ознаки за допомогою «електронних таблиць» Excel –2000 (вбудовані статистичні розрахунки)
3.4 Зважені показники варіації рядів розподілу (![]() )
)
Для вимірювання та оцінки варіації використовують абсолютні та відносні характеристики. До абсолютних відносяться: варіаційний розмах, середнє лінійне та середнє квадратичне відхилення, дисперсія; відносні характеристики представлені низкою коефіцієнтів варіації.
Варіаційний розмах характеризує діапазон варіації, це різниця між максимальним і мінімальним значеннями ознаки:
![]() (3.6)
(3.6)
Узагальнюючою мірою варіації є середнє відхилення індивідуальних значень ознаки від центру розподілу.
Середня арифметична величина виборки розраховуэться як:
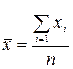 (3.7)
(3.7)
Середньозважене лінійне відхилення: 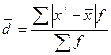 (3.8)
(3.8)
Середнє квадратичне відхилення: 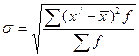 (3.9)
(3.9)
Середній квадрат відхилень – дисперсія: 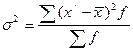 , (3.10)
, (3.10)
де ![]() - середнє арифметичне інтервального ряду розподілу, f – частота.
- середнє арифметичне інтервального ряду розподілу, f – частота.
Середнє лінійне та середнє квадратичне відхилення – іменовані числа (в одиницях вимірювання ознаки).
Порівнюючи варіації різних ознак або однієї ознаки у різних сукупнос-тях, використовують відносні характеристики варіації. Коефіцієнти варіації розраховуються як відношення абсолютних, іменованих характеристик до центру розподілу і часто виражаються процентами:
Лінійний коефіцієнт варіації: ![]() (3.11)
(3.11)
Квадратичний коефіцієнт варіації: ![]() (3.12)
(3.12)
В табл. 3.1 – 3.2 наведені результати розрахунків показників варіації, виконані методом моментів та автоматизованим розрахунком вбудованими алгоритмами статистичної обробки.
Середньозважена величина вибірки методом моментів розраховується на основі таблиць групування 2.4 -2.5, 3.1 по формулі:
![]() (3.13)
(3.13)
де mi - момент першого порядку для групування i – груп вибірки
а – один із показників середніх величин інтервалів в вибірці, для
спрощення вибираємо показник на одному з кінцевих інтервалів
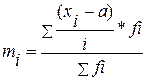 (3.14)
(3.14)
4. Кореляційний аналіз продуктивності та факторів, що на неї впливають
4.1 Рангова кореляція – розрахунок коефіцієнта Спірмена (коефіцієнт кореляційних рангів)
Нехай ![]() і
і ![]() вибірки з безперервних розподілів (розподіл відмінний від нормального). Кожному значенню
вибірки з безперервних розподілів (розподіл відмінний від нормального). Кожному значенню ![]() поставимо у відповідність його ранг
поставимо у відповідність його ранг ![]() у варіаційному рядові
у варіаційному рядові ![]() . Аналогічно, кожному значенню
. Аналогічно, кожному значенню ![]() поставимо у відповідність його ранг
поставимо у відповідність його ранг ![]() у варіаційному рядові
у варіаційному рядові ![]() .
.
Ранговий коефіцієнт кореляції Спирмена ![]() , як і звичайний коефіцієнт кореляції, характеризує залежність між вибірками випадкових величин. Вибірковим значенням рангового коефіцієнта кореляції Спирмена
, як і звичайний коефіцієнт кореляції, характеризує залежність між вибірками випадкових величин. Вибірковим значенням рангового коефіцієнта кореляції Спирмена ![]() називають величину
називають величину
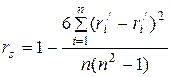 (4.1)
(4.1)
Коефіцієнт ![]() – непараметрична міра залежності між
– непараметрична міра залежності між ![]() і
і ![]() .
.
Гіпотеза ![]() при альтернативній гіпотезі
при альтернативній гіпотезі ![]() перевіряється за допомогою статистики
перевіряється за допомогою статистики
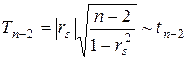 (4.2)
(4.2)
Якщо ![]() , то гіпотеза
, то гіпотеза ![]() відхиляється (тобто між
відхиляється (тобто між ![]() і
і ![]() існує рангова кореляційна залежність), і не відхиляється в противному випадку. Рівень значимості критерію
існує рангова кореляційна залежність), і не відхиляється в противному випадку. Рівень значимості критерію ![]() .
.
Порахуємо коефіцієнт Спирмена між Xi і Y в таблиці 2.1 з використанням спеціалізованої програми «Статистика».

N – обсяг вибірок
Spearman R – коефіцієнт рангової кореляції Спирмена ![]()
t (N2) – статистика ![]() для перевірки гіпотези
для перевірки гіпотези ![]()
p-level – р-уровень
Тому що ![]() , то гіпотеза
, то гіпотеза ![]() відхиляється (або, що те ж р-level0,05, тому гіпотеза відхиляється).
відхиляється (або, що те ж р-level0,05, тому гіпотеза відхиляється).
Ранговий кореляційний звязок між Xi і Y є значимим.
Порахуємо коефіцієнт Спирмена між Xj і Y в таблиці 2.1 з використанням спеціалізованої програми «Статистика».

Тому що ![]() , то гіпотеза
, то гіпотеза ![]() відхиляється (або, що те ж р-level0,05, тому гіпотеза відхиляється).
відхиляється (або, що те ж р-level0,05, тому гіпотеза відхиляється).
Ранговий кореляційний звязок між Xj і Y є значимим.
На основі наведених даних спостережень будуються лінійна одновимірні Y=f(Xi) та багатовимірні Y=f (Xi, Xj) регресійні моделі, які встановлюютьє залежність результативної ознаки Y – середньорічного рівня надою молока від факторних ознак – Xi (кількості кормів на одну корову) та Xj (рівня приплоду телят на 100 корів) по 30 хазяйствам.
Одновимірна лінійна регресійна модель представляється як:
![]() , (4.3)
, (4.3)
де ![]() – постійна складова доходу
– постійна складова доходу ![]() (початок відліку);
(початок відліку);
![]() – коефіцієнт регресії;
– коефіцієнт регресії;
![]() – відхилення фактичних значень надою
– відхилення фактичних значень надою ![]() від оцінки (математичного сподівання)
від оцінки (математичного сподівання) ![]() середньої величини надою в і
-тому хазяйстві.
середньої величини надою в і
-тому хазяйстві.
Існують різні способи оцінювання параметрів регресії. Найпростішим, найуніверсальнішим є метод найменших квадратів [48]. За цим методом параметри визначаються виходячи з умови, що найкраще наближення, яке мають забезпечувати параметри регресії, досягається, коли сума квадратів різниць ![]() між фактичними значеннями доходу та його оцінками є мінімальною, що можна записати як
між фактичними значеннями доходу та його оцінками є мінімальною, що можна записати як
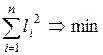 . (4.4)
. (4.4)
Відмітимо, що залишкова варіація (4.4) є функціоналом ![]() від параметрів регресійного рівняння:
від параметрів регресійного рівняння:
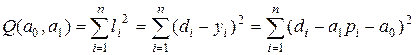 (4.5)
(4.5)
За методом найменших квадратів параметри регресії ![]() і
і ![]() є розв’язком системи двох нормальних рівнянь [48]:
є розв’язком системи двох нормальних рівнянь [48]:
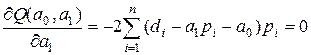 , (4.6)
, (4.6)
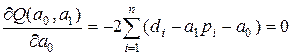 .
.
Розв’язок цієї системи має вигляд:
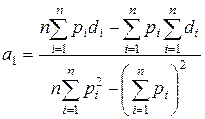 , (4.7)
, (4.7)
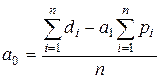 .
.
Середньоквадратична помилка регресії, знаходиться за формулою
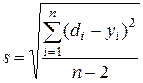 , (4.8)
, (4.8)
Коефіцієнт детермінації для даної моделі
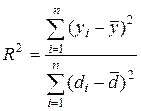 (4.9)
(4.9)
повинен дорівнювати: ![]() 0,75 – сильний кореляційний зв’зок, 0,36
0,75 – сильний кореляційний зв’зок, 0,36![]() 0,75 – кореляційний зв’язок середньої щільності;
0,75 – кореляційний зв’язок середньої щільності; ![]() 0,36 – кореля-ційній зв’язок низької щільності [48].
0,36 – кореля-ційній зв’язок низької щільності [48].
Для характеристики кореляційного зв’язку між факторною і результативною ознаками побудуємо графік кореляційного поля та теоретичну лінію регресії, визначимо параметри лінійного рівняння регресії.
Для перевірки істотності зв’язку потрібно порівняти фактичне значення статистики Фішера (F-критерій) з його критичним (табличним) значенням, яке потрібно визначити з урахуванням умов аналітичного групування і заданого рівня істотності, скориставшись таблицею.
При виконанні процедури перевірки значущості коефіцієнта детермінації висувається нульова гіпотеза H0 проти альтернативи H1 , котрі полягають в наступному:
H0 : істотної різниці між вибірковим коефіцієнтом детермінації та коефіцієнтом детермінації генеральної сукупності не існує. Ця гіпотеза рівносильна гіпотезі H0 : b=0 , тобто змінні X не впливають суттєво на залежну змінну Y. Для оцінки істотності коефіцієнта детермінації використовується статистика:
![]() (4.10)
(4.10)
що має F-розподіл Фішера з f1 =1 та f2 =n2=30–2=28 ступенями вільності.
Значення статистики порівнюється з критичним значенням цієї статистики, знайденим за таблицею при заданому рівні значущості a=0,05 та відповідному числі ступенів вільності. Якщо FF1,n-2, a , то обчислений коефіцієнт детермінації істотно відрізняється від нуля. Цей висновок забезпечується з ймовірністю 1- a . Рівень істотності a =0,05. Кількість ступенів вільності наступна: f1 =1, f2 =28.
Для лінійного зв’язку використовується лінійний коефіцієнт кореляції (Пірсона):
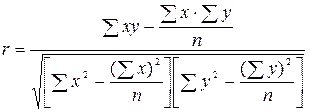 (4.11)
(4.11)
який набуває значень у межах +-1, тому характеризує не лише щільність, а й напрямок зв’язку. Додатне значення свідчить про прямий зв’язок, а від’ємне – про зворотний.
Щільність зв’язку оцінюється індексом детермінації: R=![]() , проте інтерпретується тільки R2
. Якщо коефіцієнт детермінації більше 0,6, то 60% варіації залежної величини пояснюється варіацією незалежного параметра кореляції і зв’язок є щільним.
, проте інтерпретується тільки R2
. Якщо коефіцієнт детермінації більше 0,6, то 60% варіації залежної величини пояснюється варіацією незалежного параметра кореляції і зв’язок є щільним.
На рис. 3.1 – 3.4 наведені лінійні та нелінійні регресійні одномірні моделі кореляційного зв’язку Y=F(Xi) та Y=f(Xj).Як видно з графіків рис. 3.1 – 3.2 коефіцієнт детермінації R2 для лінійної кореляції знаходиться в діапазоні 0,35 – 0,5, тобто лінійний одномірний кореляційний зв’язок є слабої сили. При побудові нелінійних одномірних рівнянь регресії (рис. 3.3 – 3.4) коефіцієнт детермінації R2 для нелінійної кореляції знаходиться в діапазоні 0,5 – 0,7, тобто нелінійний одномірний кореляційний зв’язок є сильним.
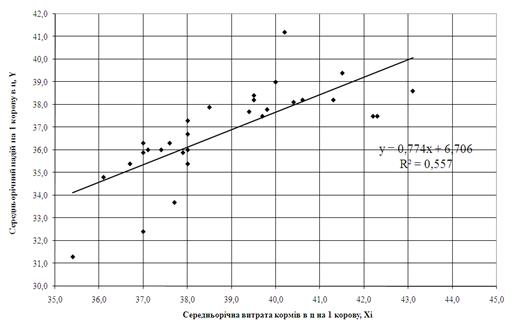
Рис. 3.1. – Побудова лінійної одномірної регресії Y=f(Xi) з використанням «електронних таблиць» Excel-2000
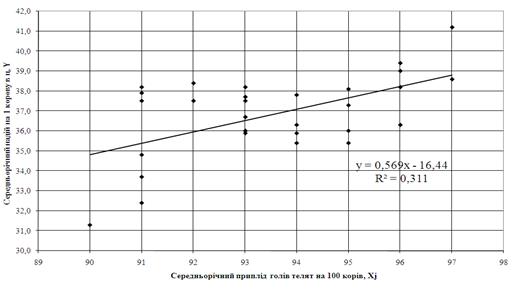
Рис. 3.2. – Побудова лінійної одномірної регресії Y=f(Xj) з використанням «електронних таблиць» Excel-2000
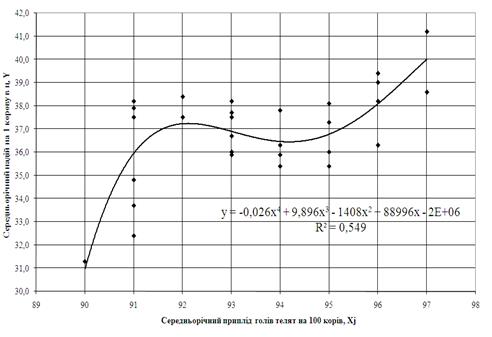
Рис. 3.3. – Побудова нелінійної одномірної регресії Y=f(Xi) з використанням «електронних таблиць» Excel-2000
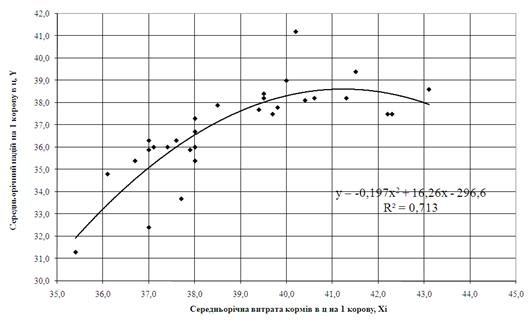
Рис. 3.4. – Побудова нелінійної одномірної регресії Y=f(Xj) з використанням «електронних таблиць» Excel-2000
4.2 Аналіз множинної кореляції
4.2.1 Перевірка передумови проведення кореляційного аналізу
Лінійна багатовимірна модель (ЛБМ) Y=f (X1, X2) має такий вигляд [68]
y=0 + 1 x1 + … + p xp (4.12)
y – залежна змінна – ендогенна змінна
x1 , x2 …xp – залежні змінні – екзогенні змінні.
У зв’язку з тим, що економетрична модель обов’язково має випадкову помилку, модель (3.21) переписується у вигляді (4.13)
y=0 + 1 x1 + … + p xp + (4.13)
де – випадкова помилка або перешкода.
Якщо після необхідних обчислень визначені чисельні значення коефіцієнтів
, то кажуть, що ми отримали оцінку коефіцієнтів моделі:![]() , тобто оцінкою коефіцієнта
є його чисельне значення b=
, тобто оцінкою коефіцієнта
є його чисельне значення b=
![]() .
.
Якщо замінити у виразі (4.13) коефіцієнти моделі оцінками, то ми отримаємо такий вираз
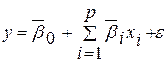 (4.14)
(4.14)
Основними передумовами використання моделі (4.12–4.13), а такі моделі ще називаються регресійними багатовимірними моделями , є наступне:
1) M ( )=0 математичне сподівання відхилення равно 0;
2) відхилення взаємонезалежні із змінними cov (xi
,![]() )=0
)=0
3) для 2х визначень відхилень коефіцієнтів коваріації між ними також дорівнює 0 – cov![]()
4) відхилення нормально розподілена величина з параметрами (0; 1)
=N (, 0; 1)
5) від виміру до виміру дисперсія відхилення не змінюється
![]()
П’ята властивість. носить спеціальну назву: гомоскедастичність (одно-рідність). Якщо умова 5) не виконана, то кажуть, що дисперсія має властивість гетероскедастичності.
Чисельний аналіз регресійної моделі починають з того, що визначають значення регресійних коефіцієнтів 1 … р та коефіцієнтів 0 , який має спеціальну назву – вільний член.
Регресійні коефіцієнти визначають за допомогою методів найменших квадратів.
![]() (4.15)
(4.15)
Візьмемо частичні похідні по кожному з виразів, дорівняти їх і отримаємо систему рівнянь
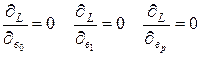
Ця система рівнянь має спеціальну назву – нормальна система.
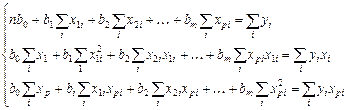 (4.16)
(4.16)
Невідомі у системі (4.16) – це коефіцієнти в0 , в1 …
х1 , y1 – ми маємо внаслідок спостережень
в0 , в1 – це коефіцієнти, які ми повинні визначити
n – кількість спостережень, вони нам завжди відомі.
4.2.2 Побудова множинного лінійного кореляційного рівняння, розрахунок коефіцієнтів регресії, перевірка суттєвості та визначення парних коефіцієнтів кореляції
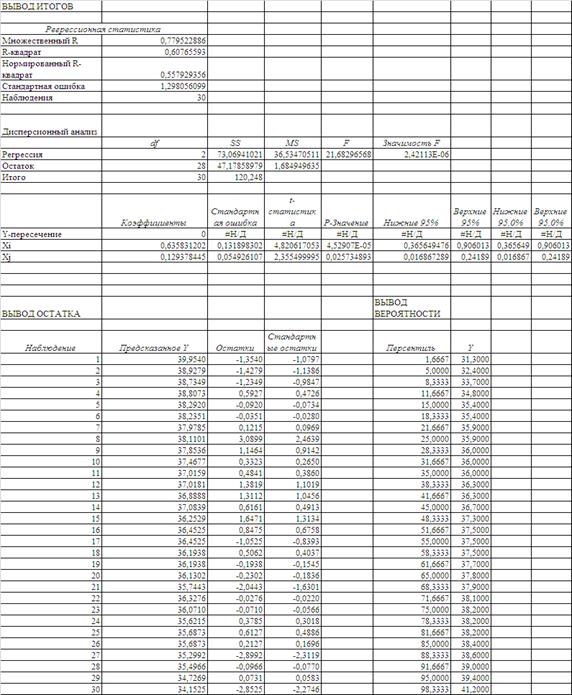
Використовуючи таблицю вихідних даних (Додаток А), розраховуємо багатовимірну лінійну регресійну модель за допомогою «електронних таблиць» EXCEL-2000. Результати розрахунків наведені в табл. 4.1
Як видно з даних розрахунків табл. 4.1 – 4.2, лінійні багатовимірні рівняння регресії описують наступні статистичні процеси:
1. Рівняння багатовимірної лінійної регресії:
а) 2параметрична модель з «нульовим» вільним членом (n=30).
Y=0,6358*Xi+0,1293*Xj
б) 2параметрична модель з значущим вільним членом (n=30).
Y=-19,5974+0,6488*Xi+0,3335*Xj
2. Коефіцієнт детермінації для даних моделей:
а) Коефіцієнт детермінації R2
(2-параметрична модель з «нульовим» вільним членом) = 0,6076 (n=30), сила регресійного зв’язка – середньої щільності (0,36![]() 0,75).
0,75).
б) Коефіцієнт детермінації R2
(2-параметрична модель з значущим вільним членом (n=30).) = 0,6497 (n=30), сила регресійного зв’язка – середньої щільності (0,36![]() 0,75).
0,75).
Згідно з таблицями критичних значень критерія Фішера:
– для багатовимірної (і=2) лінійної вибірки з n1=29 величин табличне значення Fтабл = 1,93 при рівні довірчої ймовірності Р=0,95 [48].
Як видно з даних розрахунків (табл. 4.1 –4.2), проведених за допомогою «електронних таблиць» EXCEL-2000, фактичні значення критерія Фішера для багатовимірних вибірок (і=2) з n1=29 величин становлять:
а) F (2параметрична модель з «нульовим» вільним членом) = 21,6829 (n=30) 3,33 (табл. критерій Фішера);
Таблиця 4.1. Результати розрахунків багатовимірної лінійної регресійної моделі Y=f (Xi, Xj) за допомогою «електронних таблиць» EXCEL-2000 (варіант з «нульовим» вільним членом)
Таблиця 4.2. Результати розрахунків багатовимірної лінійної регресійної моделі Y=f (Xi, Xj) за допомогою «електронних таблиць» EXCEL-2000 (варіант з значущим вільним членом)
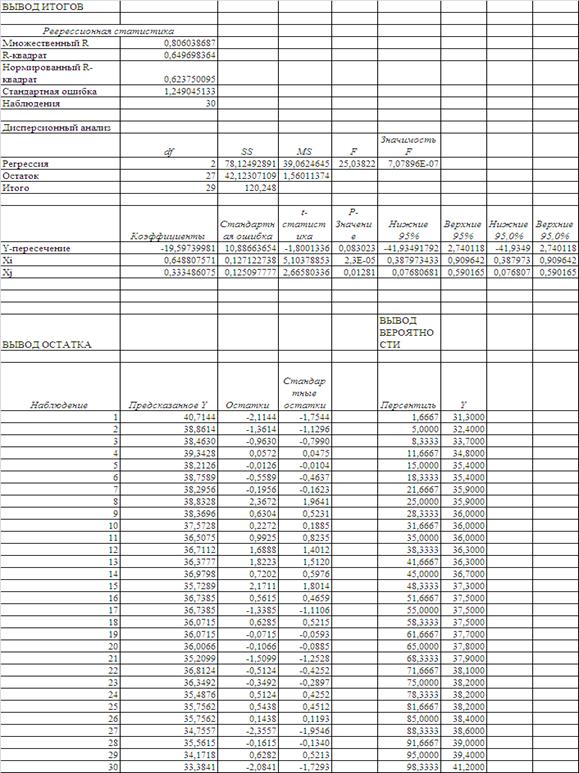
б) F (2параметрична модель з значущим вільним членом) = 25,038 (n=30) 3,33 (табл. критерій Фішера);
Тобто набагато перевищують мінімально-критеріальні значення по Фішеру і отримані регресійні багатовимірні рівняння є значущими.
Парні кореляції кореляції Пирсона обчислюються по формулі (наприклад для ![]() ):
):
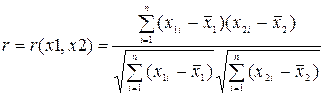 (4.17)
(4.17)
Для перевірки значимості коефіцієнтів кореляції використовують ![]() критерій. Коефіцієнт кореляції характеризує тісноту лінійного звязку між перемінними. Для цього знаходять
критерій. Коефіцієнт кореляції характеризує тісноту лінійного звязку між перемінними. Для цього знаходять ![]() статистику:
статистику:
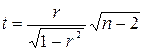 (4.18)
(4.18)
Якщо ![]() , то коефіцієнт кореляції значимий, у противному випадку – немає.
, то коефіцієнт кореляції значимий, у противному випадку – немає.
p – р-рівень, що відповідає ![]() статистиці
статистиці
Якщо р0,05, то гіпотеза ![]() :
: ![]() не значимий не відхиляється.
не значимий не відхиляється.
Якщо р0,05, то гіпотеза ![]() :
: ![]() не значимий відхиляється (коефіцієнт кореляції значимий).
не значимий відхиляється (коефіцієнт кореляції значимий).
Якщо ![]() , то звязок строго функціональний
, то звязок строго функціональний
Якщо ![]() , то звязок сильний (щильний)
, то звязок сильний (щильний)
Якщо ![]() , то звязок середній
, то звязок середній
Якщо ![]() , то звязок помірний
, то звязок помірний
Якщо ![]() , то звязок слабкий
, то звязок слабкий
Якщо ![]() , то звязок відсутній (x, y некорелльовані)
, то звязок відсутній (x, y некорелльовані)
Розрахунки, виконані спеціалізованою програмою «Статистика» дають наступні характеристики парних коефіцієнтів кореляції:

Для пари (Xi, Xj) коефіцієнт кореляції дорівнює r (Xi, Xj)=0,37,
p=0,0440,05, отже, коефіцієнт кореляції значимий.
Для пари (Xi, Y) коефіцієнт кореляції дорівнює r (Xi, Y)=0,7467, p=0,0000,05, отже, коефіцієнт кореляції значимий.
Для пари (Xj, Y) коефіцієнт кореляції дорівнює r (Xj, Y)=0,5583, p=0,0010,05, отже, коефіцієнт кореляції значимий.
Множинний коефіцієнт кореляції розраховується за допомогою парних коефіцієнтів кореляції за формулою:
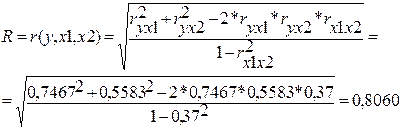 (4.19)
(4.19)
Що відповідає результатам програмних розрахунків, наведених в табл. 4.2.
4.2.3 Визначення множинного індексу кореляції, мажорантності парних та часткових коефіцієнтів, розрахунок коефіцієнта детермінації, часткових коефіцієнтів детермінації
Коефіцієнт детермінації показує частку розсіювання ![]() відносно
відносно ![]() , що порозумівається побудованою регресією. Це коефіцієнт кореляції в квадраті.
, що порозумівається побудованою регресією. Це коефіцієнт кореляції в квадраті.
Часткові коефіцієнти кореляції
Розгляду кореляцій між парами випадкових величин часто недостатньо. Якщо коефіцієнт кореляції між двома величинами великий, це може відбивати той факт, що вони обидві корелюють з деякою третьою величиною або сукупністю величин і між ними не обовязково повинна існувати безпосередня залежність.
Наприклад, у нас
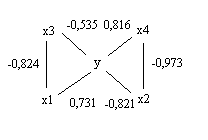
Щоб визначити дійсний звязок між двома перемінними, варто розглянути коефіцієнт часткової кореляції між ними за умови, що всі інші величини приймають фіксовані значення.
Для визначення приватного коефіцієнта кореляції використовується наступна матриця:
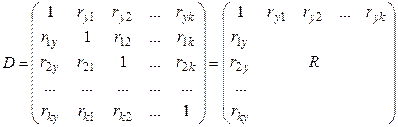 (4.20)
(4.20)
Виділена підматриця ![]() дорівнює кореляційній матриці.
дорівнює кореляційній матриці.
Частrовий коефіцієнт кореляції між перемінною ![]() і перемінною
і перемінною ![]() при фіксуванні всіх інших перемінних визначається по формулі:
при фіксуванні всіх інших перемінних визначається по формулі:
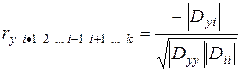 , (4.21)
, (4.21)
де ![]() – алгебраїчне доповнення елемента
– алгебраїчне доповнення елемента ![]() ,
, ![]() , а
, а ![]() виходить з
виходить з ![]() викреслюванням
викреслюванням ![]() й рядка і
й рядка і ![]() го стовпця.
го стовпця.
Часткові коефіцієнти кореляції мають ті ж властивості, що і звичайні. При виборі найкращої моделі з їхньою допомогою визначають яка з перемінних ![]() робить на
робить на ![]() найбільший вплив.
найбільший вплив.
Розрахунки часткових коефіцієнтів кореляції проведемо за допомогою спеціалізованої програми «Статистика».

Одержуємо частковий коефіцієнт кореляції між Y і Xi при фіксованому Xj
![]()
Тому що p-level=0,0000,05, то коефіцієнт значимий.

Одержуємо частковитй коефіцієнт кореляції Y і X при фіксованому Xi
![]()
Тому що p-level=0,0130,05, то коефіцієнт значимий.
4.2.4 Розрахунок коефіцієнта еластичності, бета-коефіцієнтів
Для порівняння впливу різних факторів в формуванні результативної ознаки розраховують коефіцієнт еластичності (Е) та -коефіцієнти:
Частковий коефіцієнт еластичності по кожній з факторних ознак показує на скільки відсотків в середньому змінюється результативна ознака при зміні на 1% факторної ознаки (Bk – коефіцієнт в рівнянні множинної регресії)
![]()
(4.22)
-коефіцієнт показує на яку частину середнього квадратичного відхилення зміниться результативний показник при зміні відповідного факторного показника на величину його середньоквадратичного відхилення
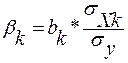 (4.23)
(4.23)
Розраховуємо показники:
![]()
![]()
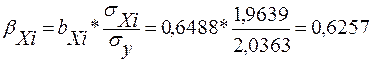
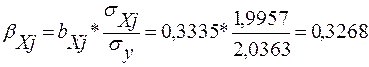
Висновки
В курсовій роботі побудовані лінійні та нелінійні регресійні одномірні моделі кореляційного зв’язку продуктивності корів по середньорічним надоям молока Y=F(Xi) та Y=f(Xj). Як показує проведений аналіз результативна ознака Y щільно пов’язана з двома факторними ознаками – кількістю кормів на одну корову та приплідом на 100 корів, при цьому коефіцієнт детермінації R2 для лінійної кореляції знаходиться в діапазоні 0,35 – 0,5, тобто лінійний одномірний кореляційний зв’язок з кожною з факторних ознак є помірної сили. При побудові нелінійних одномірних рівнянь регресії коефіцієнт детермінації R2 для нелінійної кореляції знаходиться в діапазоні 0,5 – 0,7, тобто нелінійний одномірний кореляційний зв’язок є сильним.
Лінійні багатовимірні рівняння регресії описують наступні статистичні процеси:
1. Рівняння багатовимірної лінійної регресії:
а) 2-параметрична модель з «нульовим» вільним членом (n=30).
Y=0,6358*Xi+0,1293*Xj
б) 2-параметрична модель з значущим вільним членом (n=30).
Y=-19,5974+0,6488*Xi+0,3335*Xj
2. Коефіцієнт детермінації для даних моделей:
а) Коефіцієнт детермінації R2
(2-параметрична модель з «нульовим» вільним членом) = 0,6076 (n=30), сила регресійного зв’язка – середньої щільності (0,36![]() 0,75).
0,75).
б) Коефіцієнт детермінації R2
(2-параметрична модель з значущим вільним членом (n=30).) = 0,6497 (n=30), сила регресійного зв’язка – середньої щільності (0,36![]() 0,75).
0,75).
Згідно з таблицями критичних значень критерія Фішера:
– для багатовимірної (і=2) лінійної вибірки з n1=29 величин табличне значення Fтабл = 1,93 при рівні довірчої ймовірності Р=0,95 [48].
Як видно з даних розрахунків (табл. 4.1 –4.2), проведених за допомогою «електронних таблиць» EXCEL-2000, фактичні значення критерія Фішера для багатовимірних вибірок (і=2) з n1=29 величин становлять:
а) F (2-параметрична модель з «нульовим» вільним членом) = 21,6829 (n=30) 3,33 (табл. критерій Фішера);
б) F (2-параметрична модель з значущим вільним членом) = 25,038 (n=30) 3,33 (табл. критерій Фішера);
Тобто набагато перевищують мінімально-критеріальні значення по Фішеру і отримані регресійні багатовимірні рівняння є значущими.
Список використаної літератури
1. Агропромисловий комплекс України: стан, тенденції та перспективи розвитку // Інформаційно-аналітичний збірник. – Випуск №5. – К.: ІАЕ УААН. – 2002. – 647 с.
2. Бараник З.П. Статистика. – К.: Університет «Україна, 2006. – 268 с.
3. Відтворення та ефективне використання ресурсного потенціалу АПК (теоретичні і практичні аспекти) / Відп. ред. акад. УААН В.М. Трегобчук. – К.: Ін-т економіки НАН України, 2003. – 259 с.
4. Єріна А.М., Пальян З.О. Теорія статистики. – К.: Знання, 2006. – 255 с.
5. Доугерти, Кристофер. Введение в эконометрику: Учебник/ К. Доугерти. – 2е изд. – М.: ИНФРАМ, 2007. – 419 с. – (Университетский учебник)
6. Загній О.Г. Сучасні проблеми та перспективи розвитку харчової і переробної промисловості України. Економіка промисловості України. Зб. наук. пр. – К.: РВПС України НАН України, – 2002. – 255 с.
7. Іщук С. І. Розміщення продуктивних сил (теорія, методи, практика). – К.: Видавництво Європейського університету, 2004. – 216 с.
8. Качан Є. П., Пушкар М.С. Розміщення продуктивних сил України. – К.: Видавничий Дім «Юридична книга», 2004. – 552 с.
9. Ковалевський В.В. Розміщення продуктивних сил і регіональна економіка. – К.: Знання, 2004. – 350 с.
10. Кулинич О. І. Теорія статистики: Підручник/ О.І. Кулинич, Р.О. Кулинич. – 3тє вид., переробл. і допов. – К.: Знання, 2006. – 294 с. – (Вища освіта XXI століття)
11. Максимов О.В. Математична статистика. – Кривий Ріг, 2005. – 160 с.
12. Мартиненко М.А., Нещадим О.М., Радзієвська О. І., Сафонов В.М. Математична статистика. – К.: Четверта хвиля, 2005. – 208 с.
13. Моторин Р.М., Головач А.В., Сідорова А.В., Атаманчук Н.М., Баранік З.П. Економічна статистика. – К.: КНЕУ, 2005. – 362 с.
14. Моторин Р.М., Чекотовський Е.В. Статистика. Збірник індивідуальних завдань з використанням Excel. – К.: КНЕУ, 2005. – 266 с.
15. Уманець Т.В. Економічна статистика. – К.: Знання, 2006. – 429 с.
16. Уманець Т.В. Загальна теорія статистики. – К.: Знання, 2006. – 239 с.
17. Чернюк Л.Г., Клиновий Д.В. Розміщення продуктивних сил і регіональна економіка. – К.: Університет «Україна», 2004. – 245 с.
18. Штангрет А.М., Копилюк О. І. Статистика. – Л.: Українська академія друкарства, 2005. – 176 с.
19. http://www.minagro.gov.ua – Офіційний сайт міністерства аграрної політики //