Теория вероятности
СОДЕРЖАНИЕ: Вероятность и распределение вероятности. Предмет теории вероятности. Вероятность и статистика. Основные категории теории вероятности. Классическое и статистическое определение вероятности.Вероятность и распределение вероятности.
1. Предмет теории вероятности. Вероятность и статистика.
2. Основные категории теории вероятности.
3. Классическое и статистическое определение вероятности.
4. Теорема сложения вероятностей.
5. Теорема умножения вероятностей.
6. Следствие теорем сложения и умножения вероятностей.
7. Вероятность гипотез. Формула Байеса.
8. Независимые события. Биномиальное распределение.
9. Вероятность редких событий. Формула Пуассона.
10. Локальная теорема де Муавра-Лапласа.
11. Интегральная формула Лапласа.
12. Зависимые события. Гипергеометрическое распределение.
13. Нормальное распределение.
14. Сравнительная оценка параметров эмпирического и нормального распределений. Критерий Пирсона.
1. Предмет теории вероятности. Вероятность и статистика.
Теория вероятности и математическая статистика – это наука, занимающаяся изучением закономерностей массовых случайных явлений , то есть статистических закономерностей. Такие же закономерности, только в более узкой предметной области социально-экономических явлений, изучает статистика. Между этими науками имеется общность методологии и высокая степень взаимосвязи. Практически любые выводы сделанные статистикой рассматриваются как вероятностные.
Особенно наглядно вероятностный характер статистических исследований проявляется в выборочном методе, поскольку любой вывод сделанный по результатам выборки оценивается с заданной вероятностью.
С развитием рынка постепенно сращивается вероятность и статистика, особенно наглядно это проявляется в управлении рисками, товарными запасами, портфелем ценных бумаг и т.п. За рубежом теория вероятности и математическая статистика применятся очень широко. В нашей стране пока широко применяется в управлении качеством продукции, поэтому распространение и внедрение в практику методов теории вероятности актуальная задача.
2. Основные категории теории вероятности.
Как и всякая наука, теория вероятности и математическая статистика оперируют рядом основных категорий:
- События;
- Вероятность;
- Случайность;
- Распределение вероятностей и т.д.
События – называется произвольное множество некоторого множества всех возможных исходов, могут быть:
- Достоверные;
- Невозможные;
- Случайные.
Достоверным называется событие, которое заведомо произойдет при соблюдении определенных условий.
Невозможным называется событие, которое заведомо не произойдет при соблюдении определенных условий.
Случайным называют события, которые могут произойти либо не произойти при соблюдении определенных условий.
События называют единственновозможными , если наступление одного из них это событие достоверное.
События называют равновозможными , если ни одно из них не является более возможным, чем другие.
События называют несовместимыми , если появление одного из них исключает возможность появления другого в том же испытании.
3. Классическое и статистическое определение вероятности.
Вероятность – численная характеристика реальности появления того или иного события.
Классическое определение вероятности : если множество возможных исходов конечное число, то вероятностью события Е считается отношение числа исходов благоприятствующих этому событию к общему числу единственновозможных равновозможных исходов.
Множество возможных исходов в теории вероятности называется пространством элементарных событий.
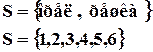
Пространство элементарных событий всегда можно описать числом nS=2, nS=6.
Если обозначить число исходов благоприятствующих событию n(E), то вероятность события Е будет выглядеть ![]() . Для наших примеров
. Для наших примеров ![]() .
.
Исходя из классического определения вероятности, можно вывести ее основные свойства :
1) Вероятность достоверного события равна 1.
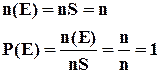
2) Вероятность невозможного события равна 0.
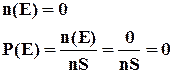
3) Вероятность случайного события находится в пределах от 0 до 1.
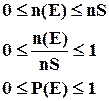
Классическое определение вероятности связано с непосредственным подсчетом вероятности, требует точного знания числа всех возможных исходов, и удобно для расчета вероятности достаточно простых событий.
Расчет вероятности более сложных событий - это сложная задача, требующая определения чисел всех возможных комбинаций появления этих событий. Подобными расчетами занимается специальная наука – комбинаторика . Поэтому на практике часто используется статистическое определение вероятности.
| Цена, руб./кг |
Объем продаж, т |
Доля в общем объеме продаж |
| 15 |
45 |
0,45 |
| 20 |
35 |
0,35 |
| 25 |
20 |
0,2 |
| 100 |
1,0 |
Доказано, что при многократном повторении опыта частости довольно устойчивы и колеблятся около некоторого постоянного числа, представляющего собой вероятность события.
Таким образом, в условиях массовых испытаний распределение частостей превращается в распределение вероятности случайной перемены.
Достоинство статистического определения вероятности в том, что для ее расчета не обязательно знать конечное число исходов.
Если классическое определение вероятности осуществляется априори (до опыта), то статистическое апосториори (после опыта по результатам).
Распределение частостей дискретного ряда, выраженных конечными числами, называется дискретным распределением вероятности .
Если осуществляются исследования массовых событий частостей, которые распределяются непрерывно и могут быть выражены какой-либо функцией, называются непрерывным распределением вероятности .
На графике такое распределение отражается непрерывной плавной линией, а площадь ограниченная этой линией и осью абсцисс всегда равна 1.
4. Теорема сложения вероятностей.
Суммой или объединением событий Е1 и Е2 , называют событием Е, состоящим в появлении события Е1 или Е2 или обоих этих событий.
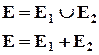
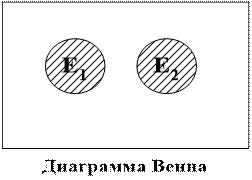
Площадь прямоугольника – это пространство элементарных событий (число единственно возможных равновозможных исходов). Площади кругов Е1 и Е2 соответственно – это числа исходов благоприятствующих событиям Е1 и Е2 .
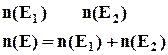 - число появлений исходов благоприятствующих событиям Е1
или Е2
или обоих этих событий.
- число появлений исходов благоприятствующих событиям Е1
или Е2
или обоих этих событий.
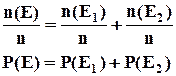
То есть вероятность появления хотя бы одного из двух несовместимых событий равна сумме вероятности этих событий.
Данная формула является частным случаем теоремы сложения вероятностей .
![]()
Доказывается общий случай теоремы методом математической индукции, путем последовательной разбивки сложного события на пары.
Пример : По результатам наблюдения за продажей мужских костюмов получены следующие данные о вероятности продажи костюмов разных размеров.
| Размер |
48 |
50 |
52 |
54 |
56 |
58 |
60 |
| Вероятность |
0,16 |
0,22 |
0,2 |
0,19 |
0,07 |
0,05 |
0,02 |
![]()
Совокупность единственно возможных событий называется полной группой или полной системой .
Сумма вероятностей событий, образующих полную систему равна 1.
![]() образуют полную систему, тогда вероятность появления хотя бы одного события равна 1.
образуют полную систему, тогда вероятность появления хотя бы одного события равна 1.
![]()
В то же время ![]() не совместны, тогда по теории сложения вероятностей
не совместны, тогда по теории сложения вероятностей ![]() .
.
Пример : Из каждых 10 посетителей магазина 6 не делают покупок.
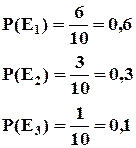 Вероятность появления хотя бы одного из этих событий равна 1.
Вероятность появления хотя бы одного из этих событий равна 1.
![]()
Два единовременно возможных события, образующих полную группу, называются противоположными (например: орел и решка).
![]()
Сумма вероятностей противоположных событий равна 1.
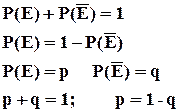
Если случайное событие Е имеет весьма малую вероятность, то практически можно считать, что в единичном испытании это событие не произойдет. Если ![]() .
.
На практике весьма малой считается вероятность Р(Е)0,1.
Игнорировать возможность появления редких событий в виду их малой вероятности на практике можно только в том случае, если это событие не имеет катастрофических последствий.
Если случайное событие имеет вероятность весьма близкую к 1, то в конкретном испытании это событие, скорее всего, произойдет.
5. Теорема умножения вероятностей.
Два события считаются независимыми , если вероятность одного из них не зависит от появления или не появления другого события.
Независимые события имеют место при повторном отборе, когда отобранная в первом испытании единица после регистрации исхода испытания возвращается в генеральную совокупность.
Вероятность совместного появления двух независимых событий Е1 и Е2 равна произведению их вероятностей.
![]()
n(E1 ) – число исходов благоприятных событию Е1 ;
n(E2 ) – число исходов благоприятных событию Е2 ;
n1 – число исходов благоприятных и неблагоприятных событию Е1 ;
n2 - число исходов благоприятных и неблагоприятных событию Е2 .
Поскольку каждый конкретный результат испытания может осуществиться в комбинации с любым другим возможным результатом испытания, вероятность совместного появления событий Е1 и Е2 можно определить по формуле:
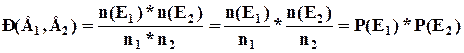
Несколько событий называются совместно независимыми или независимыми в совокупности, если каждая из них и любая комбинация из них содержащая либо все остальные события, либо часть из них – есть события независимые.
Е1 Е2 Е3
Е1 и Е2 – независимы;
Е1 и Е3 – независимы;
Е2 и Е3 - независимы;
Е1 и Е2 Е3 – независимы;
Е2 и Е1 Е3 – независимы;
Е3 и Е1 Е2 - независимы.
Попарная независимость событий не означает их независимость совокупности, однако независимость событий в совокупности обуславливает их попарную независимость.
Вероятность совместного появления нескольких событий ![]() независимых в совокупностях равна произведению вероятностей этих событий.
независимых в совокупностях равна произведению вероятностей этих событий.
![]()
Так же доказывается по методу математической индукции (то есть последовательным делением на пары),
Вероятность появления хотя бы одного из независимых в совокупности событий равна разности между 1 и произведением вероятностей противоположных событий.
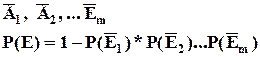
Произведение вероятностей противоположных событий позволяет определить вероятность их совместного появления, то есть вероятность того, что не произойдет ни одного из событий ![]() .
.
Но совместное появление противоположных событий и какого-либо из событий ![]() - составляют полную группу, при этом сумма вероятностей таких событий равна 1.
- составляют полную группу, при этом сумма вероятностей таких событий равна 1.
![]()
Пример : Вероятность приобретения женского платья составляет 0,09.
![]() =0,09
=0,09
![]() =0,03 (пальто)
=0,03 (пальто)
![]() =0,02 (плащи)
=0,02 (плащи)
Какова вероятность, что посетитель купит хотя бы одну из этих вещей?

Если события ![]() равновероятны, то есть
равновероятны, то есть ![]() =
=![]() =
=![]() , то равновероятные и противоположные им события q1
=q2
=…=qm
, тогда вероятность появления хотя бы одного из этих событий
, то равновероятные и противоположные им события q1
=q2
=…=qm
, тогда вероятность появления хотя бы одного из этих событий ![]() .
.
Два события считаются зависимыми , если вероятность появления одного из них зависит от появления или не появления другого события. Такие события (зависимые) имеют место при бесповторном отборе (по схеме невозвращаемого шара), когда отобранная единица обратно в генеральную совокупность не возвращается.
С зависимыми событиями связана условная вероятность. Условной вероятностью
![]() называется вероятность события Е, исчисленная в предположении, что событие Е1
уже наступило.
называется вероятность события Е, исчисленная в предположении, что событие Е1
уже наступило.
Пример : Из колоды вынута карта «дама». Какова вероятность, что она будет черной масти.
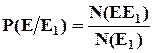 , где
, где ![]() - число исходов благоприятствующих совместному появлению событий Е и Е1
,
- число исходов благоприятствующих совместному появлению событий Е и Е1
, ![]() - число исходов благоприятствующих появлению события Е1
.
- число исходов благоприятствующих появлению события Е1
.
Зная числа элементарных исходов всегда можно рассчитать условную вероятность.
![]()
Пример : Вынута карта красной масти, какова вероятность, что это «дама»?
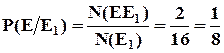
Если события Е и Е1
неравновероятны, то ![]() .
.
Непосредственный подсчет условной вероятности требует знания конечного числа исходов, поэтому более приемлемым на практике является расчет условной вероятности по формуле:
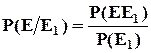 , где
, где ![]() - вероятность совместного наступления событий Е и Е1
;
- вероятность совместного наступления событий Е и Е1
; ![]() - вероятность наступления события Е1
.
- вероятность наступления события Е1
.
Данная формула не требует знания конечного числа исходов, хотя является полным аналогом, по сути, предыдущей формуле.
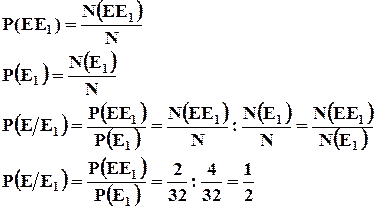
Вероятность совместного появления двух зависимых событий равна произведению вероятности одного из них на условную вероятность другого, исчисленную в предположении, что первое событие уже произошло.
Если 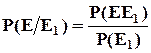 , то
, то ![]() .
.
Пример : Вероятность брака при поставке женской одежды составляет 0,015. Определить вероятность того, что проверенные наугад 2 платья из партии в 200 шт., окажутся стандартными.
q=0,015
N=200
Вероятность стандартных платьев ![]() ;
;
Количество стандартных платьев ![]()
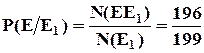
![]()
Вероятность совместного появления нескольких зависимых событий ![]() равна произведению вероятности первого из них на условные вероятности остальных, исчисленные в предположении, что это и все предшествующие события уже произошли.
равна произведению вероятности первого из них на условные вероятности остальных, исчисленные в предположении, что это и все предшествующие события уже произошли.
![]()
6. Следствие теорем сложения и умножения вероятностей.
Площадь прямоугольника – это пространство элементарных всех событий. Площадь кругов Е1 и Е2 – числа исходов, благоприятствующих событиям Е1 и Е2 .
![]() - число исходов, благоприятствующих совместному появлению событий Е1
и Е2
.
- число исходов, благоприятствующих совместному появлению событий Е1
и Е2
.

Допустим нас удовлетворяет появление только одного из двух событий Е1
и Е2
. Если эти события не совместны, то их пересечение пустое множество ![]() , а вероятность появления Е1
и Е2
несовместимых событий определяется по формуле:
, а вероятность появления Е1
и Е2
несовместимых событий определяется по формуле:
![]() .
.
Однако, при совместных событиях нас не удовлетворяет ситуация, когда оба события появляются одновременно. Вероятность такого исхода определяется по теореме умножения вероятностей.
![]()
Таким образом, вероятность появления событий Е1 и Е2 в общем случае можно рассчитать по формуле:
![]() - для независимых событий.
- для независимых событий.
Вероятность появления хотя бы одного из двух совместных событий равна сумме вероятностей этих событий без вероятности их совместного появления.
![]() - для зависимых событий.
- для зависимых событий.
Пример : Два продавца независимо друг от друга обслуживают покупателей. Вероятность того, что первый продавец сумеет продать товар 0,3, а второй – 0,2. Какова вероятность того, что хотя бы один из продавцов реализует товар?
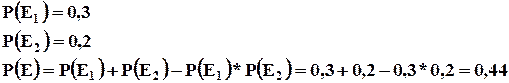
Данную задачу можно решить и другим способом, рассматривая события, как независимые совокупности. Тогда вероятность, что первый продавец не сумет продать товар – 0,7, а вероятность того, что второй не сумеет продать товар – 0,8.
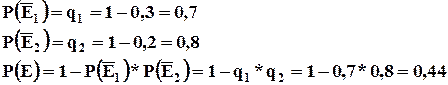
Пример : Вероятность покупки мужского костюма посетителем магазина составляет 0,02, галстука – 0,1, а вероятность покупки галстука под приобретенный костюм - 0,3.
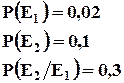 Надо определить вероятность покупки покупателями хотя бы одной из этих вещей.
Надо определить вероятность покупки покупателями хотя бы одной из этих вещей. ![]()
Комбинация теорем сложения и умножения вероятностей выражается в формуле полной вероятности .
Вероятность события Е, которое может произойти только при появлении одного из событий ![]() , составляющих полную группу, равна сумме произведений вероятностей каждого из этих событий на соответствующую условную вероятность события Е.
, составляющих полную группу, равна сумме произведений вероятностей каждого из этих событий на соответствующую условную вероятность события Е.
![]()
По условию достоверным является появление одного из событий ![]() или
или ![]() или
или ![]() или
или ![]() . По теореме умножения вероятностей:
. По теореме умножения вероятностей:
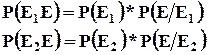
Но так как все эти события не совместны, вероятность появления одного из них определяется по теореме сложения вероятностей.
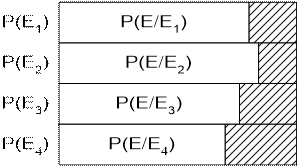
Пример : На плодоовощную базу поступило 4 партии картофеля. В первой партии – 95% доля стандартных клубней, во второй – 97%, в третьей – 94%, в четвертой – 91%. При этом доля первой партии в общем объеме поставок – 28%, второй – 31%, третьей – 24%, четвертой – 17%. Определить вероятность того, что магазину, заказавшему товар, достанется стандартная продукция.
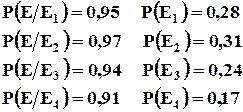
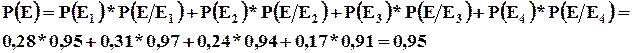
Полученный результат характеризует математическое ожидание или вероятность поставки стандартной продукции в магазин. Фактически это долевая средняя, показывающая среднюю долю стандартных клубней в четырех партиях.
7. Вероятность гипотез. Формула Байеса.
Как уже отмечалось, практически любое утверждение в статистике рассматривается как гипотеза, то есть некоторое предположение о наличии, форме, тесноте взаимосвязей.
Предположим, событие Е наступает только при появлении одного из несовместных событий ![]() , образующих полную группу. Допустим, в результате испытания событие Е произошло, то есть достоверным стало одно из событий
, образующих полную группу. Допустим, в результате испытания событие Е произошло, то есть достоверным стало одно из событий ![]() или
или ![]() или
или ![]() или
или ![]() .
.
Каждое из этих событий рассматривается как гипотетическое и его вероятность как раз определяется по формуле Байеса .
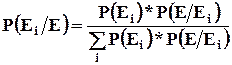
Предыдущий пример : Известно, что в магазин поставлен стандартный картофель. Какова вероятность того, что он из четвертой партии.
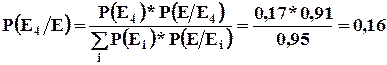
Таким образом, только в 16-ти случаях из 100 доставленная в магазин стандартная продукция окажется из четвертой партии.
Применение формулы Байеса позволяет переоценить вероятности гипотез по результатам испытаний, в следствие которых появилось событие Е.
Достоинство формулы Байеса в том, что она может применяться при отсутствии сведений о числе элементарных исходов, достаточно знать вероятности или частости событий.
8. Независимые события. Биномиальное распределение.
Предположим событие Е во всех случаях имеет одну и ту же вероятность ![]() , тогда вероятность противоположного события будет так же постоянна и может определяться по формуле
, тогда вероятность противоположного события будет так же постоянна и может определяться по формуле ![]() .
.
Такой подход позволяет рассматривать практически любое пространство элементарных событий, как дихотомно е (то есть состоит из противоположных событий).
Допустим, необходимо определить вероятность появления события Е ровно k раз в n независимых испытаниях. В этом случае событие противоположное Е произойдет n-k раз. Отобрать k-элементов из n можно различными способами, каждый из которых несовместное событие, появление которого это результат игры случая.
В математике доказано, что число различных комбинаций из n элементов по k определяется по формуле:
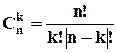 , ! это произведение натурального ряда чисел, каждое из которых больше предыдущего на 1 (начиная с 1).
, ! это произведение натурального ряда чисел, каждое из которых больше предыдущего на 1 (начиная с 1).
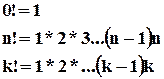
В соответствии с теоремой умножения вероятностей вероятность появления одной из возможных комбинаций определяется по формуле:
![]()
![]()
Формула, которая определяет вероятность появления события Е k-раз в n-независимых испытаниях, называется формулой Бернулли . А схема отбора из дихотомной совокупности схемой Бернулли (или схемой возвращаемого шара или схемой повторного отбора).
Пример : Для обслуживания покупателей супермаркета в час пик без очередей должно работать не менее 6 контролеров-кассиров из 8. Вероятность отсутствия одного из работников составляет 0,1. Найти вероятность работы расчетно-кассового узла без очередей.
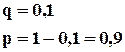
Поскольку нас устраивает работа 6, 7, 8 кассовых кабин, то вероятность появления одного из этих несовместных событий будет определяться по формуле сложения вероятностей. Каждая из этих вероятностей может определяться по формуле Бернулли.
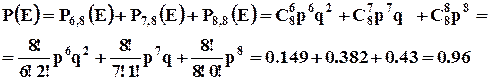
Таким образом, в 96 случаях из 100 очередей не будет.
Если при фиксированной численности n-повторного отбора из дихотомной совокупности изменять величину k, то полученное распределение вероятности будет называться биномиальным. Поскольку его ординаты представляют собой элементы разложения бинома ![]() .
.
![]()
Число наступления событий в n-независимых испытаниях называется наивероятнейшим , если этому числу соответствует наибольшая вероятность.
![]()
При этом если k смешанное число, то в результате выбирается ближайшее к этому смешанному числу, но меньше его, целое число.
В примере с кассирами ![]() .
.
Математическое ожидание М( k ) числа появления событий Е в n-независимых испытаниях равно произведению числа испытаний на вероятность появления события в каждом испытании.
![]()
Если перейти от абсолютного числа раз появления события к плотностям распределения вероятностей, то будет равно p.
![]()
Дисперсия биномиального распределения ![]() ,
, ![]() - по плотности.
- по плотности.
График биномиального распределения зависит от соотношения p и q. Если p равно q и равно 0,5, то распределение симметрично, в противном случае (pq) наблюдается асимметрия или скошенность полигона.
Показатель асимметрии биномиального распределения определяется по формуле:
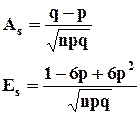
Если ![]() , то высота биномиального распределения соответствует высоте кривой нормального распределения. Доказано, что с увеличением числа испытаний значения
, то высота биномиального распределения соответствует высоте кривой нормального распределения. Доказано, что с увеличением числа испытаний значения ![]() , а биномиальное распределение стремится к нормальному распределению.
, а биномиальное распределение стремится к нормальному распределению.
9. Вероятность редких событий. Формула Пуассона.
Применение формулы Бернулли сопряжено с расчетами трех факториалов, что при достаточно больших значениях n, k, n-q, осложняет задачу. Поэтому статистики математики разработали ряд примерных методов, заменяющих формулу Бернулли при решении некоторых частных и общих задач.
Пример
: Определение вероятности появления редких событий ![]() , k-раз, в n независимых испытаниях. Причем подразумевается нефиксированное, а бесконечно большое количество испытаний (
, k-раз, в n независимых испытаниях. Причем подразумевается нефиксированное, а бесконечно большое количество испытаний (![]() ). При этом
). При этом ![]() . Такая вероятность определяется по формуле Пуассона (альтернативные независимые события).
. Такая вероятность определяется по формуле Пуассона (альтернативные независимые события).
![]() - математическое ожидание;
- математическое ожидание;
![]()
Формула Пуассона
выводится из формулы Бернулли и после ряда преобразований выглядит следующим образом 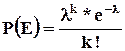 , где k – количество раз, которое произойдет редкое событие.
, где k – количество раз, которое произойдет редкое событие.
Эта формула применяется в прикладных разработках, в теории массового обслуживания (теории очередей), которая используется для расчета оптимального числа точек обслуживания, числа бензоколонок, числа рабочих мест операционистов в банке (такое число, чтобы не было очередей).
Кроме того, формула Пуассона применяется в ситуациях, когда не требуется высокая точность расчетов, а вероятность события p не велика.
10. Локальная теорема де Муавра-Лапласа.
В 1730 г. формула для приближения расчета значений для случая, когда p=q=0,5 предложил французский математик де Муавр.
Позднее в 1783 г. Лаплас обобщил результаты, полученные де Муавром, в своей теореме. Если вероятность p появления события Е в каждом испытании постоянна и отлична от 0 и 1, то вероятность ![]() появления события Е в n испытаниях равно k раз приближенно равна значению функции:
появления события Е в n испытаниях равно k раз приближенно равна значению функции:
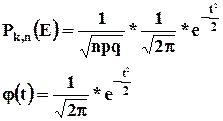
Созданы специальные таблицы значений функции ![]() в зависимости от величины t. t – стандартизированное значение.
в зависимости от величины t. t – стандартизированное значение.
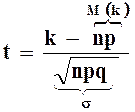
Пример : Найти вероятность того, что 80 из 1000 приобретут мужскую обувь, если вероятность покупки обуви p=0,11 (по данным из наблюдений за предыдущий период).
1) ![]()
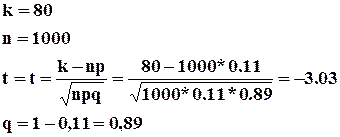
Поскольку в функции ![]() использована четная степень t – функция положительна, то есть
использована четная степень t – функция положительна, то есть ![]() .
.
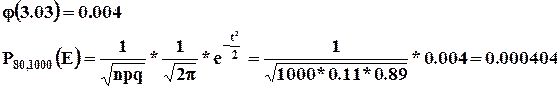
Таким образом, только в 404 случаях из 1 млн. ровно 80 из 1000 посетителей приобретут мужскую обувь.
2) ![]()
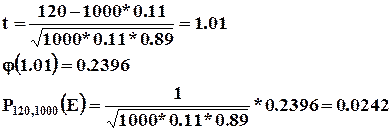
Таким образом, в 242 случаях из 10000 ровно 120 из 1000 посетителей приобретут мужскую обувь.
11. Интегральная формула Лапласа.
Локальная теорема Лапласа имеет важное значение, однако ее практическое значение ограничено. На практике важно знать вероятность того, что событие Е произойдет число раз, заданное в определенных пределах.
Пример : Вероятность приобретения покупателями мужской обуви от 80 до 120 человек из 1000.
![]() , то есть, равна сумме вероятностей несовместных событий покупки 1000 посетителей конкретного числа пар обуви в пределах от 80 до 120 пар обуви.
, то есть, равна сумме вероятностей несовместных событий покупки 1000 посетителей конкретного числа пар обуви в пределах от 80 до 120 пар обуви.
Каждое из слагаемых определяется по локальной формуле Лапласа. Высокая трудоемкость задачи очевидна, поэтому рациональным способом решения задачи является интегрирование локальной функции Лапласа.
Если вероятность p появления событий Е в каждом испытании постоянна и отлична от 0 и 1 , то
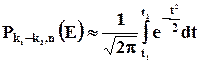 , при этом
, при этом
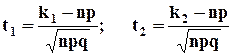
Интегрированная функция описывает распределение вероятности полной группы событий, поэтому ее общая площадь в пределах изменения t от ![]() до
до ![]() равна 1.
равна 1.
Поскольку функция асимптотически приближается к оси абсцисс в пределах изменения t от ![]() до -5, а так же от +5 до
до -5, а так же от +5 до ![]() считается, что единице равна площадь кривой в пределах ординат
считается, что единице равна площадь кривой в пределах ординат ![]() .
.
Значения функции даны в приложении 3, они указаны в пределах от –t до +t.
Пример : от 80 до 120
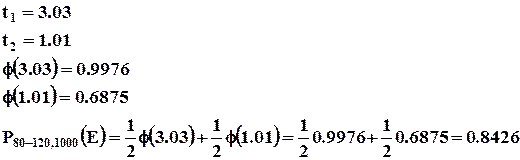
Таким образом, в 84 случаях из 100.
Складывая и вычитая площади, определенные по таблицам всегда можно получить необходимый результат.
12. Зависимые события. Гипергеометрическое распределение.
Для вывода функции гипергеометрического распределения проводятся испытания (выборка) по схеме невозвращающегося шара. В этом случае вероятность появления события Е k-раз в n зависимых испытаниях подвергается влиянию не только числа отбираемых единиц n, но и численности всей генеральной совокупности N.
Если p доля единиц генеральной совокупности, обладающих изучаемым признаком, а q – доля необладающих этим признаком, то вероятность появления события Е k раз n зависимых испытаний определяется по формуле:
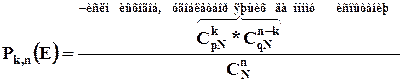 , где
, где ![]() - число сочетаний из pN=M элементов генеральной совокупности, обладающих изучаемым признаком по k;
- число сочетаний из pN=M элементов генеральной совокупности, обладающих изучаемым признаком по k; ![]() - число сочетаний из qN=N-M единиц, необладающих изучаемым признаком n-k единиц;
- число сочетаний из qN=N-M единиц, необладающих изучаемым признаком n-k единиц; ![]() - число исходов, удовлетворяющих и неудовлетворяющих данному испытанию.
- число исходов, удовлетворяющих и неудовлетворяющих данному испытанию.
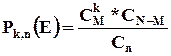
Математическое ожидание гипергеометрического распределения не зависит от объема генеральной совокупности и как в биномиальном распределении определяется по формуле:
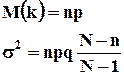 , где
, где ![]() - корректирует дисперсию при бесповторном отборе в зависимости от численности выборки и генеральной совокупности.
- корректирует дисперсию при бесповторном отборе в зависимости от численности выборки и генеральной совокупности.
Если численность генеральной совокупности достаточно велика, то ![]() , в этом случае
, в этом случае ![]() , то
, то 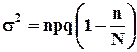 , то есть, зная параметры биномиального распределения всегда можно рассчитать параметры гипергеометрического.
, то есть, зная параметры биномиального распределения всегда можно рассчитать параметры гипергеометрического.
13. Нормальное распределение.
Нормальное распределение – это наиболее важный вид распределения в статистике.
Нормально распределяются значения признака под воздействием множества различных причин, которые практически не взаимосвязаны друг с другом и влияние каждой из которых сравнительно мало, по сравнению с действием всех остальных факторов.
Нормальное распределение отражает вариацию значений признака у единиц однородной совокупности. Подобное распределение наблюдается преимущественно в естественно-научных испытаниях (измерение роста, веса).
В социально-экономических явлениях нормального распределения данные встречаются редко. Здесь всегда присутствуют причины существенным образом влияющие на уровень изучаемого признака (результат управленческого воздействия).
Тем не менее, гипотеза о нормальном распределении исходных данных лежит в основе методологии анализа взаимосвязей выборочного метода и многих других статистических методов.
При достаточно большом числе испытаний нормальная кривая служит пределом, к которому стремятся многие виды распределения, в том числе биномиальное и гипергеометрическое.
Нормальное распределение выражается функцией вида:
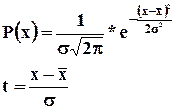
Данная функция характеризует плотность нормального распределения вероятности, ее математическое ожидание ![]() , а показатель степени – стандартное значение отклонений эмпирических данных от среднеарифметических.
, а показатель степени – стандартное значение отклонений эмпирических данных от среднеарифметических.
Масштабирование данных кривой по оси x осуществляется величинами среднеквадратического отклонения ![]() . Так как показатель степени функции возведет в четную степень, функция положительна, кривая симметрична относительно средней, то есть показатель асимметрии равен
. Так как показатель степени функции возведет в четную степень, функция положительна, кривая симметрична относительно средней, то есть показатель асимметрии равен ![]() . Показатель эксцесса кривой нормального распределения так же равен 0.
. Показатель эксцесса кривой нормального распределения так же равен 0.
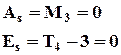
Значения параметров ![]() и
и ![]() влияют на форму и положение графика на координатной плоскости. С изменением
влияют на форму и положение графика на координатной плоскости. С изменением ![]() при
при ![]() кривая скользит вдоль оси x. С изменением
кривая скользит вдоль оси x. С изменением ![]() при
при ![]() чем больше
чем больше ![]() тем более плосковершинной становится нормальная кривая. Нормальная кривая имеет точки перегиба с координатами
тем более плосковершинной становится нормальная кривая. Нормальная кривая имеет точки перегиба с координатами ![]() . Площадь, ограниченная функцией и ординатами, проведенными из точек с координатами:
. Площадь, ограниченная функцией и ординатами, проведенными из точек с координатами:
![]() составляет 0,6827 площади всей кривой;
составляет 0,6827 площади всей кривой;
![]() - 0,9545 площади всей кривой;
- 0,9545 площади всей кривой;
![]() - 0,9973 площади всей кривой.
- 0,9973 площади всей кривой.
14. Сравнительная оценка параметров эмпирического и нормального распределений. Критерий Пирсона.
Нормальный характер распределения свидетельствует о количественной однородности статистических данных и об отсутствии каких-либо причин существенным образом определяющих вариацию изучаемого явления.
Поэтому статистический анализ нередко начинается с проверки того, как фактически (эмпирически) данные ложатся на идеальную теоретическую кривую или апроксимируются (то есть выражение данных какой-либо кривой) сравнение эмпирических и теоретических данных. Производится путем оценки гипотезы нормального характера распределения. Вероятностные статистические предположения выдвигаются в виде нулевой гипотезы. Отклонения данных эмпирических от нормальных носят случайный характер. Оценку нулевой гипотезы в данном случае осуществляют графическим методом или путем расчета специальных обобщающих показателей сходства, называемых критериями согласия.
Независимо от выбранного метода генеральные ряды распределения преобразуются в дискретные и стандартизируются.
Пример
: Известно, что среднемесячная заработная плата всех рабочих ![]() =1402,42 руб., среднеквадратическое отклонение
=1402,42 руб., среднеквадратическое отклонение ![]() =338,58 руб.
=338,58 руб.
Данные распределения среднемесячной заработной платы.
| Средне-месячная заработная плата |
Число раб-ков, |
|
|
|
|
(теор.) |
|
|
|
| До 700 |
16 |
600 |
-2,37 |
-2,81 |
0,0241 |
12,93 |
3,07 |
9,41 |
0,73 |
| 700,1-900 |
56 |
800 |
-1,78 |
-1,58 |
0,0819 |
44,04 |
11,96 |
142,95 |
3,25 |
| 900,1-1100 |
89 |
1000 |
-1,19 |
-0,71 |
0,1969 |
105,82 |
-16,82 |
282,90 |
2,67 |
| 1100,1-1300 |
172 |
1200 |
-0,60 |
-0,18 |
0,3337 |
179,35 |
-7,35 |
54,05 |
0,30 |
| 1300,1-1500 |
244 |
1400 |
-0,01 |
0,00 |
0,3989 |
214,44 |
29,56 |
873,70 |
4,07 |
| 1500,1-1700 |
163 |
1600 |
0,58 |
-0,17 |
0,3365 |
180,87 |
-17,87 |
319,44 |
1,77 |
| 1700,1-1900 |
93 |
1800 |
1,17 |
-0,69 |
0,2002 |
107,62 |
-14,62 |
213,80 |
1,99 |
| 1900,1-2100 |
64 |
2000 |
1,76 |
-1,56 |
0,0840 |
45,17 |
18,83 |
354,42 |
7,85 |
| Свыше 2100,1 |
13 |
2200 |
2,36 |
-2,77 |
0,0249 |
13,38 |
-0,38 |
0,14 |
0,01 |
| Итого |
910 |
22,63 |
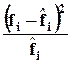
В связи с тем, что табличные значения рассчитаны для непрерывно изменяющегося признака с дисперсией равной 1, необходимо скорректировать полученные частости на фактическую величину интервала и среднеквадратическое отклонение.
![]() , где
, где ![]() величина интервала. Так как все интервалы равны
величина интервала. Так как все интервалы равны ![]() , тогда
, тогда 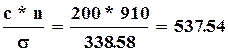 .
.
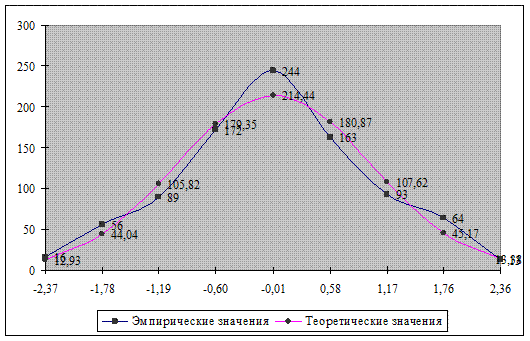
Графики не позволяют определить насколько существенны отклонения, поэтому более точным считается способ расчета критериев согласия. Наиболее известный из них:
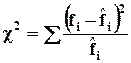
В соответствии с формулой, чем сильнее совпадение кривых, тем меньше величина ![]() . При отсутствии отклонений
. При отсутствии отклонений ![]() , но даже при небольших отклонениях величина
, но даже при небольших отклонениях величина ![]() зависит от числа слагаемых (то есть от числа групп). Если
зависит от числа слагаемых (то есть от числа групп). Если ![]() 0, то необходима его вероятностная оценка (стр. 368).
0, то необходима его вероятностная оценка (стр. 368).
![]() - число степеней свободы и заданная вероятность несущественности отклонений эмпирических данных и теоретических. r – число групп, k - число параметров, которые нельзя изменить.
- число степеней свободы и заданная вероятность несущественности отклонений эмпирических данных и теоретических. r – число групп, k - число параметров, которые нельзя изменить.
![]()
Поскольку фактическое значение ![]() (22,63) гораздо больше табличного (5,348) даже для вероятности 0,5, гипотеза о случайном характере отклонений эмпирических данных от теоретических отклоняется.
(22,63) гораздо больше табличного (5,348) даже для вероятности 0,5, гипотеза о случайном характере отклонений эмпирических данных от теоретических отклоняется.